Multifactorial Evolutionary Algorithm: A Complete Guide to Theory, Applications, and Optimization in Drug Discovery
This comprehensive guide explores multifactorial evolutionary algorithms (MFEAs), an emerging paradigm in evolutionary computation that simultaneously solves multiple optimization tasks through implicit knowledge transfer.
Multifactorial Evolutionary Algorithm: A Complete Guide to Theory, Applications, and Optimization in Drug Discovery
Abstract
This comprehensive guide explores multifactorial evolutionary algorithms (MFEAs), an emerging paradigm in evolutionary computation that simultaneously solves multiple optimization tasks through implicit knowledge transfer. Targeting researchers, scientists, and drug development professionals, the article examines MFEA foundations in multifactorial optimization, detailed methodological implementations, advanced troubleshooting strategies for negative transfer avoidance, and rigorous validation approaches. With special emphasis on biomedical applications, particularly de novo drug design and multi-objective molecular optimization, this resource provides both theoretical understanding and practical insights for leveraging MFEAs in complex research optimization scenarios.
Understanding Multifactorial Evolutionary Algorithms: Core Principles and Evolutionary Foundations
Defining Multifactorial Optimization and Evolutionary Multitasking
Multifactorial Optimization (MFO) represents a paradigm shift in evolutionary computation, enabling the simultaneous solving of multiple distinct optimization tasks within a single algorithmic run. Unlike traditional single-objective or multi-objective optimization that focuses on a single problem, MFO tackles a set of K different optimization problems, termed tasks, concurrently [1]. Each task has its own search space, objective function(s), and constraints. The fundamental goal of MFO is to find a set of optimal solutions, where each solution is the optimum for one of the K component tasks, by leveraging potential synergies and commonalities between them [2] [1].
Evolutionary Multitasking is the computational embodiment of the MFO concept, implemented through specialized evolutionary algorithms (EAs). It refers to the process of conducting evolutionary search across multiple optimization problems simultaneously. The key innovation in evolutionary multitasking is the transfer of knowledge or genetic material between tasks, a mechanism that allows an algorithm to use information discovered while solving one task to accelerate progress on another related task [1]. This paradigm is inspired by the biological concept of cultural evolution, where knowledge is transferred across generations and domains through assortative mating and vertical cultural transmission [1].
The Multifactorial Evolutionary Algorithm (MFEA) was the pioneering algorithm to realize this evolutionary multitasking paradigm [1]. MFEA creates a unified search space where individuals encoded in a common representation can be decoded and evaluated for different tasks. The algorithm utilizes two primary mechanisms to enable knowledge transfer: (1) assortative mating, which allows individuals with similar skill factors (the task they perform best on) to preferentially mate, while still permitting cross-task reproduction with a controlled probability, and (2) vertical cultural transmission, which ensures that offspring inherit cultural traits (skill factors) from their parents [2] [1].
Fundamental Principles and Mechanisms
Core Definitions in MFO
In a formal MFO environment with K tasks, the i-th task (T_i) is an optimization problem with search space Ω_i and objective function f_i: Ω_i → R. For a population of individuals P = {p_1, p_2, ..., p_N}, the following properties are defined for each individual [1]:
- Factorial Cost (
Ψ_i^j): The objective valuef_j( p_i )of individualp_ion taskT_j. - Factorial Rank (
r_i^j): The index of individualp_iwhen the population is sorted in ascending order ofΨ_j(for minimization problems). - Scalar Fitness (
φ_i): Defined as1 / min_{j∈{1,...,K} { r_i^j }, representing the overall performance of an individual across all tasks. - Skill Factor (
τ_i): The index of the task on which the individual performs best, formallyτ_i = argmin_{j∈{1,...,K}} { r_i^j }.
These definitions enable meaningful comparison and selection of individuals in a multitasking environment, where each individual may excel at different tasks.
The Knowledge Transfer Mechanism
The transfer of knowledge between tasks is controlled primarily through a parameter called random mating probability (rmp) [1]. The rmp determines the probability that two individuals with different skill factors will mate and produce offspring. When rmp is high, cross-task reproduction occurs frequently, promoting knowledge transfer. When rmp is low, individuals primarily mate with others having the same skill factor, limiting knowledge transfer.
A significant challenge in evolutionary multitasking is managing negative transfer—when the transfer of genetic material between unrelated tasks deteriorates optimization performance [1]. To address this, advanced MFEAs incorporate adaptive transfer strategies that dynamically adjust the rmp based on online estimation of inter-task relatedness, or use prediction models to identify promising individuals for knowledge transfer [1].
Table 1: Key Characteristics of Multifactorial Optimization
| Characteristic | Description | Significance |
|---|---|---|
| Unified Search Space | A common encoding allows individuals to be evaluated across different tasks [1]. | Enables direct comparison and knowledge transfer between tasks. |
| Skill Factor | Identifies the task an individual performs best on [1]. | Guides assortative mating and cultural transmission. |
| Implicit Transfer | Knowledge is transferred through crossover of encoded solutions [1]. | No explicit mapping required; transfer occurs naturally. |
| Cultural Transmission | Offspring inherit the skill factor of a parent [1]. | Maintains population diversity across tasks. |
Experimental Protocols and Methodologies
Standardized Benchmark Problems
Research in MFO relies on standardized benchmark problems to evaluate algorithm performance. Commonly used benchmarks include [1]:
- CEC2017 MFO Benchmark Problems: A set of problems specifically designed for multifactorial optimization, featuring tasks with varying degrees of relatedness.
- WCCI20-MTSO and WCCI20-MaTSO Benchmark Problems: Benchmark suites from the 2020 IEEE World Congress on Computational Intelligence, covering both single-objective and many-objective task optimization scenarios.
These benchmarks typically include problems where tasks share global optima, have overlapping basins of attraction, or are completely unrelated, allowing researchers to test both the convergence speed and the robustness of transfer mechanisms.
Performance Evaluation Metrics
The performance of MFEAs is typically evaluated using the following metrics [1]:
- Convergence Speed: The number of generations or function evaluations required to reach a satisfactory solution for each task.
- Solution Accuracy: The precision of the obtained solutions compared to known global optima.
- Transfer Effectiveness: The success rate of knowledge transfer, often measured by comparing performance with and without transfer mechanisms.
Table 2: Advanced Multifactorial Evolutionary Algorithms and Their Core Methodologies
| Algorithm | Core Methodology | Key Innovation | Reported Advantage |
|---|---|---|---|
| MFEA [1] | Cultural transmission with fixed rmp parameter. | Pioneering framework for evolutionary multitasking. | Foundation for all subsequent MFEAs. |
| MFEA-II [1] | Online transfer parameter estimation. | Replaces scalar rmp with an adaptive RMP matrix. | Captures non-uniform inter-task synergies; reduces negative transfer. |
| EMT-ADT [1] | Adaptive transfer strategy based on decision tree. | Uses supervised learning to predict an individual's transfer ability. | Improves probability of positive transfer; enhances solution precision. |
| EMTO-HKT [1] | Hybrid knowledge transfer strategy. | Combines individual-level and population-level learning. | Adapts to different degrees of task relatedness. |
| MPUSMs-IMFEOA [2] | Multidimensional preference user surrogate models. | Applies MFEA to interactive evolutionary algorithms for recommendation. | Improves recommendation diversity and novelty by 54.02% and 2.69% [2]. |
Protocol for the EMT-ADT Algorithm
The Evolutionary Multitasking Optimization with Adaptive Transfer Strategy Based on Decision Tree (EMT-ADT) exemplifies a modern MFEA methodology [1]:
- Initialization: Generate a unified population of individuals and initialize the adaptive parameters.
- Skill Factor Assignment: Evaluate each individual on all tasks and assign skill factors based on factorial ranks.
- Decision Tree Construction:
- Define an evaluation indicator to quantify the transfer ability of each individual.
- Use the Gini coefficient to construct a decision tree that predicts the transfer ability of candidate individuals.
- Assortative Mating and Cultural Transmission:
- Select parents based on their scalar fitness.
- Apply crossover between individuals with the same skill factor or with different skill factors based on the rmp.
- Use the decision tree to select promising positive-transfer individuals for knowledge transfer.
- Offspring Evaluation: Decode and evaluate offspring on their inherited skill factor's task (vertical cultural transmission).
- Population Update: Combine parent and offspring populations and select survivors based on scalar fitness.
- Parameter Adaptation: Dynamically update the rmp or transfer strategy based on the success history of cross-task transfers.
Visualization of Core Workflows
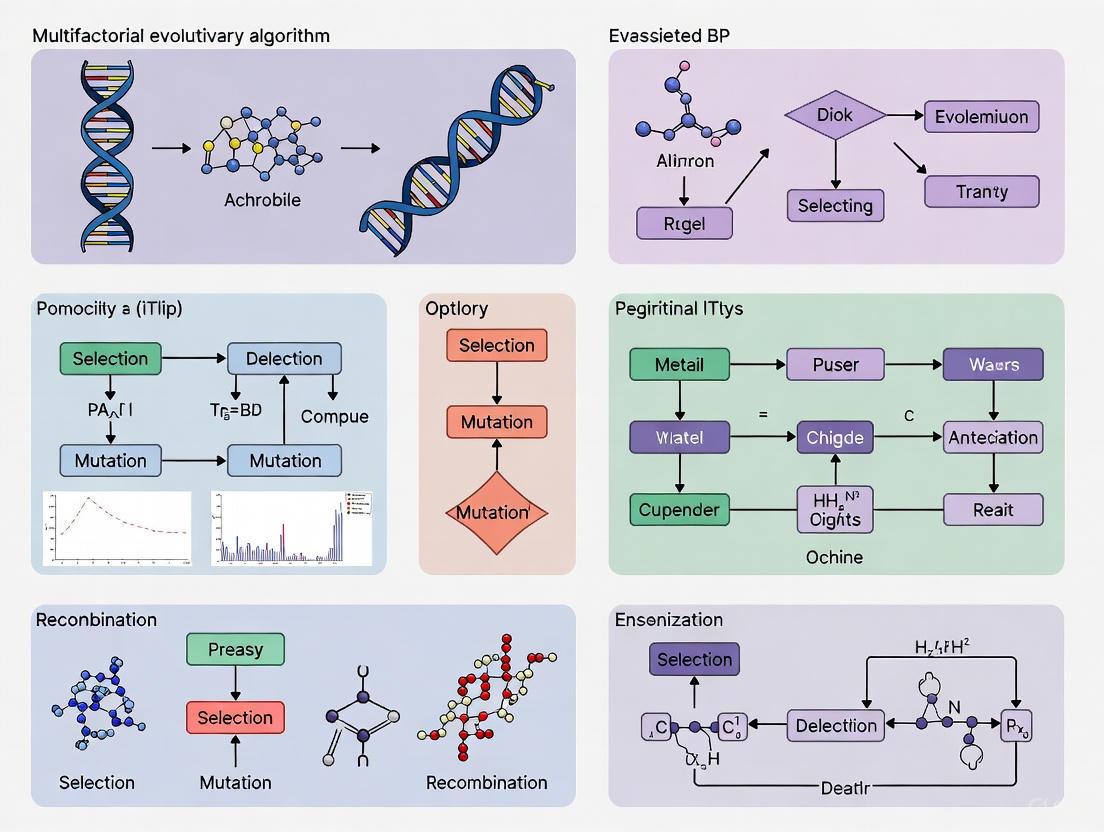
High-Level MFEA Workflow
The following diagram illustrates the generalized workflow of a Multifactorial Evolutionary Algorithm, showing how multiple tasks are optimized concurrently through a unified population and shared genetic material.
Knowledge Transfer and Negative Transfer Mitigation
This diagram details the critical process of knowledge transfer and the modern strategies used to mitigate negative transfer, which is a central challenge in evolutionary multitasking.
The Scientist's Toolkit: Essential Research Reagents
Table 3: Essential Computational Tools for MFO Research
| Research Reagent | Function | Example Implementation/Usage |
|---|---|---|
| Benchmark Problems | Standardized test functions to evaluate and compare algorithm performance. | CEC2017 MFO, WCCI20-MTSO, WCCI20-MaTSO [1]. |
| Unified Encoding | A representation scheme that allows a solution to be decoded for multiple tasks. | Random keys, direct representation, or problem-specific unified encodings [1]. |
| Skill Factor Calculator | Computational module that identifies the best-performing task for each individual. | Algorithm implementing factorial cost and rank calculations [1]. |
| Transfer Ability Predictor | Model to quantify and predict the usefulness of an individual for cross-task knowledge transfer. | Decision tree (EMT-ADT) [1] or other supervised learning models. |
| RMP Adaptation Mechanism | Component to dynamically adjust the random mating probability based on inter-task relatedness. | RMP matrix (MFEA-II) [1] or success-history based adaptation. |
| Domain Adaptation Technique | Methods to transform search spaces to improve inter-task correlation. | Linearized Domain Adaptation (LDA) [1] or autoencoders. |
The Multifactorial Evolutionary Algorithm (MFEA) is a pioneering algorithm in the field of Evolutionary Multitasking (EM) and Multifactorial Optimization (MFO) [3]. Unlike traditional evolutionary paradigms that solve a single optimization problem in isolation, MFEA is designed to solve multiple, self-contained optimization tasks simultaneously within a single, unified search process [4]. This approach is inspired by the biological concept of multifactorial inheritance, where an individual's traits are influenced by multiple hereditary factors [5]. The core innovation of MFEA lies in its ability to exploit potential synergies and complementarities between different tasks through the transfer of genetic material, often leading to accelerated convergence and improved solution quality for the tasks involved [6] [3]. The algorithm's efficacy hinges on three fundamental concepts: Factorial Cost, Factorial Rank, and Skill Factor, which together enable the implicit transfer of knowledge and effective management of multiple search spaces [4].
Foundational Concepts and Definitions
Within the MFEA framework, every individual in the population is encoded in a unified search space and can be decoded into a task-specific solution for any of the K optimization tasks being addressed [3]. To manage this multitasking environment, each individual is assigned several key properties.
Table 1: Core Properties of an Individual in MFEA
| Property | Symbol | Description |
|---|---|---|
| Factorial Cost | Ψₖᵖ | The fitness value of individual p when evaluated on a specific task Tₖ [4] [3]. |
| Factorial Rank | rₖᵖ | The rank of individual p within the population sorted by performance on task Tₖ [4] [3]. |
| Scalar Fitness | φᵖ | A unified fitness measure derived from the individual's best factorial rank across all tasks [4]. |
| Skill Factor | τᵖ | The single task on which an individual performs the best, defining its specialization [4]. |
Factorial Cost
The Factorial Cost is the most direct measure of an individual's performance on a given task. For an individual p and a task Tₖ, its factorial cost, denoted as Ψₖᵖ, is simply the value returned by the objective function fₖ of that task [3]. Each individual in the population possesses a vector of K factorial costs, {Ψ₁ᵖ, Ψ₂ᵖ, ..., Ψₖᵖ}, representing its performance across all concurrent tasks. In a minimization scenario, a lower factorial cost indicates better performance for that particular task.
Factorial Rank
The Factorial Rank provides a relative, task-specific performance measure. For each task Tₖ, the entire population is sorted in ascending order of their factorial cost (for minimization problems). The position index of an individual p in this sorted list is its factorial rank, rₖᵖ [4] [3]. An individual ranked 1 is the best-performing individual for that task. The factorial rank is crucial because it allows for a standardized comparison of individuals across different tasks, which may have objective functions on vastly different scales.
Skill Factor
The Skill Factor is the task identifier on which an individual exhibits its best performance, effectively defining its specialization [4]. It is determined by identifying the task for which the individual has the highest scalar fitness, φᵖ. The scalar fitness is itself calculated from the best (lowest) factorial rank an individual achieves across all tasks: φᵖ = 1 / minₖ { rₖᵖ } [4]. Consequently, an individual's skill factor, τᵖ, is set to the task k corresponding to this minₖ { rₖᵖ }. The skill factor governs the evolutionary process, as individuals are only evaluated on their skill factor task during reproduction, significantly reducing computational cost [4].
The MFEA Workflow and Algorithmic Structure
The MFEA process integrates these core concepts into a cohesive evolutionary workflow, as outlined in Algorithm 1 [4]. The algorithm begins by initializing a population and evaluating each individual on all tasks to determine their initial skill factors. The main loop then consists of generating offspring through genetic operators, selectively evaluating them, and creating the next generation.
Diagram 1: MFEA High-Level Workflow
Knowledge Transfer via Assortative Mating
A critical mechanism in MFEA is assortative mating, which controls knowledge transfer between tasks. During crossover, two randomly selected parents p1 and p2 have a fixed probability rmp (random mating probability) to undergo inter-task crossover, regardless of their skill factors. If their skill factors differ (τᵖ¹ ≠ τᵖ²) and a random number exceeds rmp, inter-task crossover is bypassed to prevent negative transfer [4]. This encourages beneficial knowledge exchange between similar tasks while reducing the risk of detrimental interference from unrelated tasks.
Vertical Cultural Transmission
The selection process in MFEA implements a form of vertical cultural transmission. The current population and the offspring population are combined into an intermediate pool. The scalar fitness φ of every individual in this pool is recalculated, and the best individuals are selected to form the next generation [4]. This ensures that high-performing individuals, and the beneficial genetic material they carry, are propagated, thereby driving the population towards improved solutions for all tasks.
Experimental Protocols and Methodologies
To empirically validate the performance of MFEA and its core concepts, researchers typically follow a structured experimental protocol involving benchmark problems and performance metrics.
Table 2: Typical Experimental Setup for MFEA Validation
| Component | Description | Example from Literature |
|---|---|---|
| Benchmark Problems | A set of known optimization problems (e.g., TSP, TRP) used to create multitasking environments [6]. | Traveling Salesman Problem (TSP) and Traveling Repairman Problem (TRP) with Time Windows [6]. |
| Performance Metrics | Quantitative measures to evaluate algorithm performance and efficiency. | Average Best Cost: The mean of the best objective values found over multiple runs. Performance Ranking: Ranking algorithms based on solution quality and computation time [7]. |
| Comparison Baselines | Standard algorithms used for performance comparison. | Independent runs of single-task optimizers like Genetic Algorithm (GA) and Particle Swarm Optimization (PSO) [7]. |
| Statistical Analysis | Methods to ensure the statistical significance of the results. | Multi-criteria decision-making methods like TOPSIS for overall ranking [7]. |
Sample Protocol: Evaluating MFEA on TSPTW and TRPTW
- Problem Instantiation: Select specific benchmark instances for the Traveling Salesman Problem with Time Windows (TSPTW) and the Traveling Repairman Problem with Time Windows (TRPTW) [6].
- Algorithm Configuration: Initialize the MFEA parameters, including population size, number of generations, crossover and mutation rates, and the random mating probability (
rmp). - Execution: Run the MFEA simultaneously on both tasks. In parallel, run traditional single-task optimizers (e.g., GA) independently on each problem.
- Data Collection: Record the best factorial cost found for each task at every generation. For single-task optimizers, record the best cost over evaluations.
- Analysis: Compare the convergence speed and final solution quality of MFEA against the single-task solvers. Analyze the genetic transferability by examining how individuals with different skill factors influence each other's search process [6].
The Scientist's Toolkit: Essential Research Reagents
Table 3: Key "Research Reagents" in Multifactorial Evolutionary Algorithm Research
| Item / Concept | Function / Role in the MFEA "Experiment" |
|---|---|
| Unified Search Space (Y) | A normalized representation (e.g., [0,1]^D) into which all task solutions are encoded. Allows for a common search domain and application of standard genetic operators [4]. |
| Random Mating Probability (rmp) | A key control parameter that regulates the rate of inter-task crossover, thereby balancing exploration and the risk of negative knowledge transfer [4]. |
| Scalar Fitness (φ) | Acts as a universal selector, enabling the comparison and selection of individuals from different tasks based on their relative performance, thus guiding the overall evolution [4]. |
| Benchmark Suites | Standardized sets of optimization problems (e.g., CEC competitions) used to rigorously test and compare the performance of different MFEA variants under controlled conditions [8]. |
| Skill Factor (τ) | A labeling mechanism that reduces computational cost by limiting expensive fitness evaluations and also identifies the specialist role of each individual in the population [4]. |
Advanced MFEA Variants and Future Directions
The basic MFEA framework has spawned numerous advanced variants designed to enhance its performance and robustness. Recent research has introduced methods for online transfer parameter estimation (MFEA-II) to automatically adapt the degree of knowledge transfer between tasks, moving beyond the fixed rmp and mitigating negative transfer [7]. Other variants, like the Mutagenic MFEA (M-MFEA), incorporate biological principles such as trait segregation to guide genetic exchanges without manually predefined parameters [9]. Furthermore, the integration of MFEA with local search techniques, such as the Randomized Variable Neighborhood Search (RVNS), has been shown to better balance exploration and exploitation, leading to superior results on complex combinatorial problems like the TSPTW and TRPTW [6].
Diagram 2: Evolution of MFEA Variants
These advancements frame the core concepts of factorial cost, rank, and skill factor not as static definitions, but as the foundation of a dynamic and rapidly evolving research paradigm aimed at solving complex, real-world optimization problems in areas such as drug development, industrial planning, and system reliability more efficiently [9] [7] [10]. The ongoing research focuses on making knowledge transfer in evolutionary multitasking more adaptive, explainable, and effective.
Multifactorial Evolutionary Algorithm (MFEA) represents a pioneering computational paradigm within the broader field of evolutionary multitasking optimization (EMTO). This innovative framework addresses multiple optimization tasks simultaneously within a single unified search process, mimicking human cognitive ability to leverage knowledge across related problems. Unlike traditional evolutionary algorithms that solve tasks in isolation, MFEA capitalizes on implicit genetic transfer and cross-task synergies to accelerate convergence and improve solution quality across all tasks. The fundamental premise is that related optimization tasks often contain complementary information, and transferring this knowledge can enhance overall search efficiency [11] [12]. This capability makes MFEA particularly valuable for complex real-world domains like pharmaceutical research, where related drug development problems can benefit from shared insights.
The MFEA framework introduces two foundational mechanisms: a unified search space that enables cross-task operations, and cultural transmission principles that facilitate knowledge transfer. These mechanisms work synergistically to overcome the limitations of traditional evolutionary approaches, which treat each optimization task independently, often resulting in computational inefficiency and missed opportunities for leveraging inter-task correlations [1]. By explicitly designing for multitasking environments, MFEA achieves what conventional methods cannot – the simultaneous improvement on multiple fronts through intelligent genetic exchange, establishing itself as a transformative approach in computational optimization with significant implications for data-driven scientific fields.
Core Architecture of MFEA
Foundational Principles and Definitions
The MFEA architecture builds upon several formally defined concepts that enable its multitasking capability. In a multitasking environment with K distinct optimization tasks, each task Tj possesses its own search space Xj and objective function fj. The algorithm maintains a single population of individuals, each with specific properties defined relative to all tasks [1]:
- Factorial Cost (Ψji): The objective value of individual pi on task Tj, representing its raw performance on that specific task.
- Factorial Rank (rji): The performance ranking of individual pi within the population when sorted ascendingly by factorial cost for task Tj.
- Scalar Fitness (φi): A unified fitness measure defined as φi = 1/min{rji} across all tasks j ∈ {1,…,K}, enabling cross-task comparison.
- Skill Factor (τi): The task index where individual pi achieves its best factorial rank, identifying its specialized domain expertise.
These properties collectively enable MFEA to maintain a unified population while preserving task-specific specialization. The scalar fitness provides a common ground for selection pressure, while skill factors ensure that individuals contribute most effectively to tasks where they demonstrate superior performance [1].
The Unified Search Space
The unified search space represents a fundamental innovation in MFEA, serving as a common representation framework that encodes solutions for all tasks. This unified representation enables genetic operations across individuals specialized for different tasks, facilitating the implicit knowledge transfer that drives MFEA's efficiency gains. Through careful design of encoding and decoding mechanisms, disparate search spaces for different tasks are mapped to a shared representation space where crossover and mutation operations can occur without losing task-specific semantics [13].
This unified approach differs significantly from traditional multi-population methods, as it maintains a single population where each individual carries a skill factor denoting its specialized task. The unified space enables assortative mating – the controlled exchange of genetic material between individuals from different tasks – which serves as the primary mechanism for knowledge transfer. The efficiency of this approach stems from its ability to leverage genetic complementarity across tasks while maintaining population diversity, often resulting in convergence rates 3-4 orders of magnitude faster than traditional iterative methods on related tasks [14].
Cultural Transmission Mechanisms
Theoretical Foundation
Cultural transmission in MFEA implements knowledge transfer through biologically-inspired mechanisms operating on the unified population. Drawing inspiration from modern cultural evolution theory, these mechanisms enable the flow of valuable genetic information between tasks, mimicking how humans acquire and transfer knowledge across related domains [12]. The cultural transmission framework incorporates two primary evolutionary engines:
Vertical Cultural Transmission: This mechanism involves the inheritance of genetic material from parent to offspring during reproduction, preserving specialized knowledge within task lineages. It ensures that offspring initially specialize in the same tasks as their parents, maintaining expertise continuity while allowing for potential skill factor changes through subsequent operations.
Horizontal Cultural Transmission: This complementary mechanism enables knowledge acquisition across different task specialties through cross-task mating and information exchange. It introduces genetic diversity and allows promising solution features discovered in one task to propagate to other tasks, potentially accelerating convergence across the entire multitasking environment [12].
These cultural transmission principles address a fundamental challenge in evolutionary computation: balancing exploitation of known good solutions with exploration of new regions in the search space. By strategically controlling the flow of genetic information, MFEA navigates this trade-off more effectively than single-task approaches.
Assortative Mating and Knowledge Transfer
Assortative mating implements cultural transmission through controlled reproduction within the unified population. The process is governed by a key parameter – the random mating probability (rmp) – which determines the likelihood of cross-task reproduction versus within-task mating [1]. The assortative mating process follows these steps:
- Parent Selection: Two parents are selected from the unified population, each with their respective skill factors.
- Mating Decision: If both parents share the same skill factor, mating proceeds unconditionally. If they have different skill factors, a random number is generated; if it exceeds the rmp threshold, mating is prohibited.
- Offspring Generation: Successful mating produces offspring through genetic operators, with offspring potentially inheriting genetic material from parents specialized in different tasks.
- Skill Factor Assignment: Offspring are assigned skill factors, initially often inheriting from parents but potentially developing new specializations through evaluation.
This controlled mating strategy enables MFEA to dynamically regulate knowledge transfer intensity between tasks. High rmp values encourage extensive cross-task genetic exchange, beneficial for highly similar tasks, while lower rmp values restrict transfer, reducing negative interference between dissimilar tasks [1]. This parameter can be fixed based on domain knowledge or adaptively tuned during evolution based on measured task relatedness.
Advanced Knowledge Transfer Strategies
Addressing Negative Transfer
A significant challenge in MFEA is negative knowledge transfer, which occurs when genetic exchange between dissimilar tasks degrades performance rather than enhancing it. This phenomenon is particularly problematic when tasks have low inter-task similarity, as transferred solutions may disrupt rather than accelerate convergence [11] [15]. Recent research has developed sophisticated strategies to mitigate this issue:
Adaptive Gaussian-Mixture-Model-Based Knowledge Transfer (MFDE-AMKT): This approach uses Gaussian distributions to model subpopulation distributions for each task, creating a Gaussian Mixture Model (GMM) for comprehensive knowledge transfer. The mixture weights and mean vectors are adaptively adjusted based on evolutionary trends, with similarity measured through probability density overlap on each dimension for fine-grained assessment [11].
Evolutionary Trend Alignment in Subdomains (SETA-MFEA): This method decomposes tasks into subdomains with simpler fitness landscapes, then establishes precise inter-subdomain mappings by determining and aligning evolutionary trends of corresponding subpopulations. This enables more accurate knowledge transfer than treating tasks as indivisible domains [15].
Decision Tree-Based Adaptive Transfer (EMT-ADT): This innovative approach defines evaluation indicators to quantify individual transfer ability, then constructs decision trees to predict positive-transfer individuals, selectively enabling knowledge transfer from promising candidates only [1].
Residual Learning for Enhanced Crossover
Recent advances have introduced deep learning techniques to enhance MFEA's crossover operations. The MFEA-RL (Residual Learning) method employs a Very Deep Super-Resolution (VDSR) model to transform low-dimensional individuals into high-dimensional residual representations, enabling better modeling of complex variable interactions [16]. This approach addresses limitations of traditional crossover operators in handling high-dimensional, nonlinear task relationships.
The MFEA-RL framework incorporates three key innovations:
- High-Dimensional Representation: A VDSR model generates D×D high-dimensional representations from 1×D individuals, explicitly modeling complex inter-variable relationships.
- ResNet-Based Skill Factor Assignment: Dynamic skill factor assignment using residual networks that adapt to task relationships.
- Random Mapping Crossover: Extraction and mapping of single rows from high-dimensional data back to original space, replacing traditional simulated binary crossover [16].
This neural-enhanced crossover operator demonstrates MFEA's continuing evolution, incorporating modern deep learning to overcome limitations in traditional evolutionary operators, particularly for high-dimensional optimization problems common in pharmaceutical applications.
Quantitative Performance Analysis
Benchmarking Results
The performance of MFEA and its variants has been extensively evaluated on standardized benchmark problems. The following table summarizes key quantitative results from comparative studies:
Table 1: Performance Comparison of MFEA Variants on Standard Benchmark Problems
| Algorithm | Key Innovation | Convergence Speed | Solution Quality | Negative Transfer Resistance |
|---|---|---|---|---|
| MFEA [1] | Basic cultural transmission | Baseline | Baseline | Low |
| MFEA-II [15] | Online similarity learning | 1.5-2× faster than MFEA | Moderate improvement (5-15%) | Moderate |
| MFDE-AMKT [11] | Adaptive Gaussian mixture model | 2-3× faster than MFEA | Significant improvement (15-30%) | High |
| SETA-MFEA [15] | Subdomain evolutionary trend alignment | 2.5-3.5× faster than MFEA | Significant improvement (20-35%) | High |
| CT-EMT-MOES [12] | Cultural transmission theory | 2-2.8× faster than MFEA | Moderate improvement (10-20%) | Moderate |
| MFEA-RL [16] | Residual learning crossover | 3-4× faster than MFEA | Best improvement (25-40%) | High |
These results demonstrate consistent improvement across MFEA variants, with newer algorithms achieving significantly better performance through enhanced knowledge transfer mechanisms. The table shows a clear trend toward both faster convergence and better solution quality, with modern variants achieving speedups of 3-4 orders of magnitude compared to traditional iterative methods on appropriate problem classes [14].
Pharmaceutical Application Performance
In pharmaceutical applications, MFEA has demonstrated particular value for complex optimization problems. The following table illustrates performance metrics for specific drug development applications:
Table 2: MFEA Performance in Pharmaceutical Applications
| Application Domain | Algorithm | Key Metric Improvement | Computational Efficiency |
|---|---|---|---|
| Inter-domain path computation [13] | NDE-MFEA | 25-40% better solution quality | 30-50% faster convergence |
| Drug design optimization [17] | Not specified | 15-25% improved binding affinity | 2-3× reduction in screening time |
| Protein stability prediction [17] | Not specified | 20-30% accuracy improvement | Enabled high-throughput in silico screening |
These results highlight MFEA's practical value in computationally intensive pharmaceutical domains, where its ability to simultaneously optimize multiple related objectives can significantly accelerate research timelines and improve outcomes.
Experimental Protocols and Methodologies
Standardized Evaluation Framework
Rigorous evaluation of MFEA implementations follows established experimental protocols using benchmark problems specifically designed for multitasking optimization. The Community Employment Center 2017 Multitasking Single Objective (CEC2017-MTSO) and IEEE World Congress on Computational Intelligence 2020 Multitasking Single Objective (WCCI2020-MTSO) benchmark suites provide standardized testing environments [16]. These benchmarks incorporate tasks with varying degrees of inter-task similarity, landscape modality, and variable interactions to comprehensively assess algorithm performance.
Standard experimental procedure includes:
- Population Initialization: A unified population is initialized with random individuals encoded in the unified search space.
- Skill Factor Assignment: Each individual is evaluated on all tasks and assigned a skill factor based on best performance.
- Evolutionary Cycles: The population undergoes repeated generations of selection, assortative mating, cultural transmission, and evaluation.
- Performance Tracking: Algorithm performance is measured using metrics like convergence speed, solution quality, and computational efficiency across all tasks.
Experiments typically run for a fixed number of generations or until convergence criteria are met, with multiple independent runs to ensure statistical significance. Performance is compared against baseline algorithms including single-task evolutionary algorithms, basic MFEA, and state-of-the-art multitasking approaches [11] [15].
Workflow Visualization
The following diagram illustrates the standard MFEA experimental workflow:
Essential Research Components
Successful implementation of MFEA in pharmaceutical research requires specific computational tools and methodological components. The following table details key "research reagents" – essential algorithms, models, and frameworks – that constitute the MFEA toolkit:
Table 3: Essential Research Components for MFEA Implementation
| Component | Function | Example Implementations |
|---|---|---|
| Unified Encoding Scheme | Represents solutions for all tasks in a common space | Node-depth encoding [13], Random keys, Direct representation |
| Similarity Measurement | Quantifies inter-task relatedness to guide transfer | Wasserstein distance [11], Probability density overlap [11], Evolutionary trend consistency [15] |
| Adaptive Transfer Controller | Dynamically regulates knowledge transfer intensity | Decision trees [1], Gaussian mixture models [11], Online similarity learning [15] |
| Domain Adaptation | Enhances transfer between dissimilar tasks | Linearized domain adaptation [15], Affine transformation [16], Subspace alignment [15] |
| Crossover Operators | Facilitates genetic exchange between tasks | Residual learning crossover [16], Simulated binary crossover, Partially mapped crossover |
Implementation Framework
The following diagram illustrates the architectural relationships between these components in a modern MFEA implementation:
Pharmaceutical Applications and Case Studies
MFEA has demonstrated significant potential in pharmaceutical research and development, where multiple related optimization problems frequently occur. In drug discovery, MFEA can simultaneously optimize multiple molecular properties such as binding affinity, solubility, and synthetic accessibility, overcoming the limitations of sequential optimization approaches [17]. For protein therapeutic development, researchers have used stability prediction models enhanced by deep learning to guide optimization, with MFEA enabling simultaneous consideration of multiple stability metrics and functional constraints [17].
In pharmacokinetic modeling, MFEA has been applied to optimize multiple model parameters simultaneously using experimental data, significantly reducing model calibration time while improving predictive accuracy [17]. The algorithm's ability to transfer knowledge between related compound classes allows it to leverage structural similarities, making particularly efficient use of limited experimental data – a common challenge in early-stage drug development.
Another promising application involves drug delivery system optimization, where MFEA can concurrently address multiple design objectives including release profile, stability, and manufacturing efficiency [17]. For complex delivery systems like nanoparticles or antibody-drug conjugates, this simultaneous optimization approach can identify design solutions that would likely be missed by traditional sequential methods, potentially accelerating development timelines while improving therapeutic outcomes.
The MFEA framework represents a significant advancement in evolutionary computation, with particular relevance for data-intensive fields like pharmaceutical research. Future development directions include increased integration with deep learning architectures, automated hyperparameter optimization, and enhanced negative transfer prevention through more sophisticated similarity metrics. As pharmaceutical problems grow in complexity, MFEA's ability to leverage relatedness between tasks will become increasingly valuable for accelerating discovery and optimization processes.
The continued evolution of MFEA will likely focus on explainable knowledge transfer – developing methods to interpret and justify cross-task genetic exchanges – which is particularly important in regulated pharmaceutical applications. Additionally, federated multitasking approaches that enable knowledge transfer across distributed datasets without sharing proprietary information could address significant industry concerns while preserving MFEA's efficiency benefits.
In conclusion, MFEA's unified search space and cultural transmission mechanisms provide a powerful framework for addressing complex multitasking optimization problems. Its demonstrated success across diverse domains, combined with ongoing methodological innovations, positions MFEA as a transformative computational approach with substantial potential to accelerate pharmaceutical research and development through more efficient knowledge leveraging across related optimization challenges.
The field of optimization is witnessing a significant paradigm shift, moving from algorithms designed for single, isolated problems towards those capable of addressing multiple tasks simultaneously. This transition mirrors a broader trend in Artificial Intelligence (AI), where the ability to handle several coexisting data flows and modeling tasks has become paramount [18]. Evolutionary Multitask Optimization (EMTO) has emerged as a prominent research area within this landscape, focusing on the development of solvers that can leverage knowledge acquired from one problem to enhance the solution of other, related or unrelated, problems [18]. This paradigm is part of the broader Transfer Optimization field, which also includes sequential transfer and multiform multitasking, but multitasking is currently the most prominent due to the central role played by Evolutionary Computation in its development [18]. The conceptual foundation of this field is the exploitation of synergies between concurrent tasks, aiming to achieve benefits such as accelerated convergence, more robust search, and a reduced need for computational resources.
Theoretical Foundations of Evolutionary Multitasking
Fundamental Concepts and Definitions
At its core, a multitasking environment involves optimizing K distinct tasks {T_k}_{k=1}^K, each defined over its own search space Ω_k [18]. The goal is not merely to find a good solution for each task in isolation, but to find a set of solutions {x_k}_{k=1}^K that jointly optimize all tasks, potentially by exploiting the commonalities between them. In the Evolutionary Multitasking paradigm, this is typically achieved through a unified population of individuals that evolves to address all tasks simultaneously. Knowledge transfer is the central mechanism that enables this synergistic search. It involves the exchange of genetic information or learned patterns between individuals solving different tasks. The effectiveness of a multitasking algorithm hinges on its ability to promote positive transfer—where knowledge from one task aids another—while minimizing negative transfer (or inter-task confusion), where the exchange of information hampers convergence [18].
The Multifactorial Evolutionary Algorithm (MFEA), often considered a canonical algorithm in this domain, embodies these principles by maintaining a single population where each individual is associated with a specific task but can potentially mate with individuals from other tasks based on a random mating probability [9]. This creates opportunities for genetic material from well-adapted individuals in one task to influence the search process in another.
The Biological Inspiration: From Single- to Multi-Task Phenotypes
The intellectual roots of EMTO are deeply embedded in biological principles. Traditional Evolutionary Algorithms (EAs) draw inspiration from Darwinian evolution, mimicking processes such as selection, crossover, and mutation to evolve a population of candidate solutions towards an optimum for a single task. EMTO extends this biological metaphor to encompass more complex phenomena observed in nature.
One key inspiration is the concept of multifactorial inheritance, where an individual's overall traits (phenotype) are determined by multiple genetic and environmental factors [9]. In EMTO, this translates to a single individual's genetic material (chromosome) possessing the latent potential to express solutions to multiple tasks. The algorithm's role is to unravel this potential effectively.
A more recent biological inspiration is trait segregation, a well-recognized phenomenon in biological evolution where genetic information is naturally segregated and expressed as dominant or recessive traits [9]. This principle has been leveraged to guide evolutionary exchanges in populations without relying on manually predefined parameters. For instance, the Mutagenic Multifactorial Evolutionary Algorithm based on Trait Segregation (M-MFEA) defines whether an individual's traits are dominant or recessive within a unified search space [9]. This allows for a more natural and spontaneous guidance of evolution, as individuals interact and transfer genetic information based on their expressed traits, leading to enhanced information transfer within and across tasks.
Table 1: Core Concepts in Evolutionary Multitask Optimization
| Concept | Description | Biological Analogy |
|---|---|---|
| Multitask Environment | A scenario comprising multiple optimization tasks to be solved concurrently. | Multiple selective pressures in a single ecosystem. |
| Unified Search Space | A generalized space that encapsulates the search spaces of all individual tasks. | A common gene pool for a population facing multiple environmental challenges. |
| Knowledge Transfer | The exchange of information (e.g., genetic material, learned models) between tasks. | Horizontal gene transfer or cultural learning between species. |
| Factorial Cost | A vector representing an individual's performance across all tasks. | An organism's fitness across different environmental niches. |
| Skill Factor | The task on which an individual performs best. | An organism's primary specialization or adaptation. |
| Random Mating Probability | A parameter controlling the likelihood of cross-task reproduction. | Biological mechanisms that influence reproductive isolation. |
| Trait Segregation | The natural emergence of dominant and recessive traits guiding genetic exchange. | Mendelian inheritance of dominant and recessive alleles. |
Key Algorithmic Frameworks and Methodologies
The Multifactorial Evolutionary Algorithm (MFEA)
The MFEA establishes a foundational framework for Evolutionary Multitasking. Its operational workflow can be visualized as a continuous cycle of evaluation, selection, and reproduction that facilitates cross-task knowledge exchange, as shown in the diagram below.
The key steps of the MFEA are:
- Initialization: A single, unified population of individuals is initialized. Each individual possesses a chromosome representation that can be decoded into a solution for any of the K tasks.
- Factorial Cost Evaluation: Each individual is evaluated for every task in the environment. The result is a factorial cost vector, representing the individual's performance across all tasks. The best performing task for an individual is designated as its skill factor.
- Selection and Mating: A mating pool is created by selecting parents based on their performance. A critical parameter, the Random Mating Probability (RMP), determines whether two selected parents can produce offspring. If a random number exceeds the RMP, mating occurs only if the parents share the same skill factor (within-task crossover). Otherwise, cross-task crossover is permitted, facilitating direct knowledge transfer.
- Genetic Operations: Crossover and mutation are applied to generate offspring. Vertical cultural transmission ensures that offspring inherit the skill factor of a parent if both parents share the same skill factor; otherwise, it is assigned randomly.
- Iteration: Steps 2-4 are repeated until a termination condition is met, yielding a set of highly adapted solutions for each task.
Advanced Paradigms: M-MFEA and Trait Segregation
Recent research has focused on overcoming the limitations of manually set parameters like RMP. The Mutagenic Multifactorial Evolutionary Algorithm based on Trait Segregation (M-MFEA) is a notable advancement inspired directly by biological trait segregation [9]. This algorithm introduces several key innovations:
- Trait Expression Mechanism: Individuals are characterized by having either dominant or recessive traits within the unified multitasking search space. This trait expression naturally guides the evolutionary process without requiring a predefined RMP.
- Mutagenic Genetic Information Interaction: A specialized strategy is designed to enhance information transfer both within and across tasks. Individuals spontaneously guide evolution according to their trait expressions, promoting more effective and organic knowledge sharing.
- Adaptive Mutagenic Gene Inheritance: This mechanism drives continuous task convergence by dynamically controlling how genetic information is passed on to offspring, based on the expressed traits of the parents.
Table 2: Comparison of Key Multitasking Evolutionary Algorithms
| Algorithm | Core Mechanism | Key Parameters | Advantages | Limitations/Challenges |
|---|---|---|---|---|
| MFEA [18] | Unified population, implicit genetic transfer | Random Mating Probability (RMP) | Foundational framework, relatively simple to implement. | Performance sensitive to RMP setting; risk of negative transfer. |
| MFEA-II [9] | Online transfer parameter estimation | Online learned parameters | Reduces reliance on pre-set parameters; more adaptive. | Increased computational overhead for parameter estimation. |
| M-MFEA [9] | Trait segregation and mutagenic inheritance | Trait expression (dominant/recessive) | Eliminates need for manual RMP; natural, biologically-inspired guidance. | Complexity in defining and managing trait expressions. |
Experimental Protocols and Validation
Benchmarking and Performance Evaluation
Validating the performance of multitasking algorithms requires rigorous experimentation on standardized benchmarks and real-world problems. Common benchmark suites often comprise multiple optimization functions (e.g., sphere, Rastrigin, Rosenbrock) grouped into different multitasking scenarios. These scenarios are carefully designed to have known inter-task correlations, allowing researchers to assess an algorithm's ability to exploit synergies [18].
The evaluation methodology must fairly compare the performance of multitasking algorithms against two baselines: (1) solving each task in isolation using a competitive single-task optimization algorithm, and (2) other state-of-the-art multitasking algorithms. Key performance metrics include:
- Convergence Speed: The number of generations or function evaluations required to reach a satisfactory solution for all tasks.
- Solution Quality: The average and best fitness values achieved for each task upon convergence.
- Statistical Significance: Results are typically reported over multiple independent runs, and statistical tests (e.g., Wilcoxon signed-rank test) are used to confirm the significance of performance differences.
A critical, yet often overlooked, aspect is the computational effort required for knowledge transfer. A comprehensive evaluation should account not only for fitness improvements but also for the overhead introduced by the transfer mechanisms [18].
Detailed Protocol: Validating M-MFEA on Benchmarks and an Industrial Problem
The validation protocol for the M-MFEA algorithm provides a concrete example of a modern experimental methodology [9]. The following diagram illustrates the structured workflow from problem definition to result analysis.
Protocol Steps:
Problem Definition:
- Benchmark Suites: Select a diverse set of benchmark problems from established suites. These should include tasks with varying degrees of relatedness to test the algorithm's robustness in different transfer scenarios.
- Industrial Problem: Employ a real-world problem to demonstrate practical applicability. In the case of M-MFEA, this was an industrial planar kinematic arm control problem, which presents a complex, high-dimensional optimization challenge relevant to intelligent manufacturing [9].
Algorithm Configuration:
- Configure the M-MFEA by defining its core components: the trait segregation mechanism, the mutagenic genetic information interaction strategy, and the adaptive gene inheritance mechanism.
- Set population size, maximum number of generations, and other standard evolutionary algorithm parameters. Note that M-MFEA does not require manual setting of RMP.
Execution and Data Collection:
- Execute the M-MFEA and all competitor algorithms (e.g., MFEA, MFEA-II) for a fixed number of independent runs (e.g., 30 runs) to account for stochasticity.
- In each run, record the best fitness for each task at every generation to create convergence profiles.
Performance Analysis:
- Convergence Accuracy: Analyze the final solution quality achieved for all tasks.
- Convergence Speed: Compare the number of function evaluations required to reach a pre-defined accuracy threshold.
- Statistical Testing: Perform non-parametric statistical tests (e.g., Wilcoxon signed-rank test) on the results to confirm that any performance differences are statistically significant.
- Knowledge Transfer Quality: Investigate the algorithm's behavior to quantify the occurrence of positive and negative transfer, validating the effectiveness of the trait segregation mechanism.
The Scientist's Toolkit: Research Reagent Solutions
For researchers embarking on experimental work in Evolutionary Multitasking, a suite of "research reagents" is essential. The following table details key components and their functions in a typical experimental setup.
Table 3: Essential Research Reagents for Evolutionary Multitasking Experiments
| Research Reagent / Tool | Function / Purpose | Exemplars / Notes |
|---|---|---|
| Benchmark Suites | Standardized set of problems for fair algorithm comparison and validation. | Compositions of classic functions (e.g., Sphere, Rastrigin, Ackley) with known inter-task relationships. |
| Real-World Test Problems | Validate algorithmic performance and practicality in complex, applied scenarios. | Industrial planar kinematic arm control [9], aluminum electrolysis process optimization [9], wind turbine blade design [9]. |
| Performance Metrics | Quantify algorithm effectiveness, efficiency, and robustness. | Average convergence curve, best objective value, hypervolume indicator, performance gain over single-task solvers. |
| Statistical Testing Framework | Provide rigorous, statistically sound validation of experimental results. | Wilcoxon signed-rank test, Friedman test with post-hoc analysis for multiple algorithm comparison. |
| Software Libraries & Platforms | Provide implementations of core algorithms and utilities for rapid prototyping and testing. | Platforms like MATLAB, Python (with libraries like DEAP, PyGMO), and custom software. |
Applications in Drug Development and Complex Domains
The principles of evolutionary multitasking show significant promise for addressing complex challenges in drug development and related fields. While direct applications in pharmaceutical research are still emerging, the underlying methodologies are perfectly suited to problems involving multiple, interrelated optimization tasks. Potential application areas include:
- Multi-Objective Molecular Design: Simultaneously optimizing a drug candidate for multiple properties, such as binding affinity, solubility, and synthetic accessibility, can be naturally framed as a multitask optimization problem. Knowledge about chemical structures that favor one property could inform the search for structures that satisfy another.
- Polypharmacology and Target Interaction Prediction: Optimizing a single compound to interact with multiple biological targets (polypharmacology) while minimizing off-target effects is a quintessential multitask challenge. EMTO could help explore the complex chemical space to find molecules with a desired multi-target profile.
- Genotype-Environment Interaction Analysis: Understanding how genetic factors interact with environmental variables to influence disease risk or drug response involves analyzing multiple, correlated tasks [9]. Multitasking algorithms could help unravel these complex interactions more efficiently than single-task approaches.
- Process Optimization in Pharmaceutical Manufacturing: As seen in other industrial sectors like aluminum electrolysis [9], EMTO can optimize multiple, interdependent operational parameters in a manufacturing process to simultaneously maximize yield, purity, and energy efficiency.
The ability of algorithms like M-MFEA to perform adaptive knowledge transfer is particularly valuable in these domains, where the relationships between tasks (e.g., between different ADMET properties) may not be known a priori and must be learned during the optimization process [9].
Future Directions and Open Challenges
Despite its promising advances, Evolutionary Multitask Optimization faces several fundamental questions and open challenges that require community effort to resolve [18]. Key future research directions include:
- Plausibility and Practical Applicability: There is an urgent need to demonstrate that the simultaneous optimization of several related problems occurs naturally in real-world applications and that EMTO provides a tangible profit over solving problems in isolation with powerful single-task algorithms [18].
- Algorithmic Novelty and Terminology: The field must strive for genuine innovation, ensuring that new algorithms are not merely minor variations or renamings of existing methods. Establishing clear and consistent terminology is crucial [18].
- Fair and Comprehensive Evaluation: Research studies must adopt more rigorous evaluation methodologies that go beyond simple fitness comparisons. This includes reporting computational effort, clearly demonstrating the benefit over single-task baselines, and using benchmarks that reflect realistic scenarios [18].
- Scalability and Many-Task Optimization: Extending these paradigms to handle a large number of tasks (so-called "many-task" optimization) presents significant scalability challenges. Efficient knowledge extraction and transfer in such high-task environments is an active area of research [9].
- Hybrid and Surrogate-Assisted Models: Integrating multitasking algorithms with surrogate models (e.g., for expensive finite-element simulations in photonics [19] or molecular dynamics) and other AI paradigms like deep learning can greatly enhance their applicability to computationally demanding real-world problems.
Multifactorial Evolutionary Algorithms (MFEAs) represent a paradigm shift in evolutionary computation, moving from single-task optimization to a concurrent multitasking environment. This framework, known as Evolutionary Multitasking Optimization (EMTO), allows multiple optimization tasks to be solved simultaneously by leveraging potential synergies and complementarities between them [20] [21]. The core principle underpinning this approach is that useful knowledge gained while solving one task may contain valuable information that can accelerate the search process or improve the solution quality of other, related tasks [22].
The success of EMTO hinges critically on the effective management of knowledge transfer between tasks. Within this context, three fundamental concepts emerge as cornerstones of the field: positive transfer, negative transfer, and random mating probability (RMP). These interconnected mechanisms govern how information flows between tasks and ultimately determine whether multitasking provides a net benefit over traditional single-task optimization approaches. This technical guide provides an in-depth examination of these critical terminologies, their interrelationships, and their practical implications for researchers implementing multifactorial evolutionary algorithms.
Foundational Concepts in Multifactorial Evolution
Before delving into the core terminology, it is essential to understand the basic framework of multifactorial optimization. In a typical MTO scenario, K distinct optimization tasks are solved simultaneously [20] [23]. Each task, Tᵢ, possesses its own search space Xᵢ and objective function fᵢ: Xᵢ → ℝ. The goal of MTO is to find a set of optimal solutions {x₁, x₂, ..., x𝐾} such that each xᵢ minimizes its corresponding fᵢ [20].
The Multifactorial Evolutionary Algorithm (MFEA), introduced by Gupta et al., was the pioneering algorithm to implement this paradigm through implicit genetic transfer [20]. In MFEA, individuals in a unified population are assigned a skill factor (τᵢ), which indicates the task on which the individual performs best [1] [21]. Knowledge transfer occurs primarily through crossover operations between parents with different skill factors, governed by a key control parameter called random mating probability [20].
Table 1: Key Definitions in Multifactorial Evolutionary Algorithms
| Term | Definition | Significance |
|---|---|---|
| Skill Factor | The task on which an individual performs best [1] [21] | Determines an individual's specialized task and influences mating selection |
| Factorial Rank | The performance index of an individual on a specific task when the population is sorted by factorial cost [1] [21] | Used to compute scalar fitness and skill factors |
| Scalar Fitness | A unified measure of an individual's overall performance across all tasks, calculated as φᵢ = 1/min{rᵢⱼ} [1] [21] | Enables cross-task comparison and selection |
| Assortative Mating | A mating strategy where individuals with similar skill factors are more likely to mate, unless the random mating probability condition is met [20] | Balances knowledge transfer with task specialization |
Critical Terminology Deep Dive
Positive Transfer
Positive transfer occurs when knowledge exchange between optimization tasks leads to improved performance in one or more tasks—either through accelerated convergence, better solution quality, or enhanced population diversity [20] [22]. This beneficial effect emerges when tasks share complementary features or similar fitness landscapes, allowing progress in one task to inform and guide the search in another.
The mechanism can be visualized as a scenario where the global optimum of one task (G1) shares decision space characteristics with the global optimum of another task (G2) [20]. When genetic material from individuals near G1 is transferred to the population of task T2, it pulls the search toward regions containing G2, thereby accelerating discovery of the optimal solution.
Table 2: Methodologies for Enhancing Positive Transfer
| Methodology | Underlying Principle | Implementation Example |
|---|---|---|
| Domain Adaptation | Aligns search spaces of different tasks to facilitate more effective knowledge transfer [20] [1] | MDS-based Linear Domain Adaptation (LDA) creates low-dimensional subspaces for each task and learns mapping relationships between them [20] |
| Elite Knowledge Transfer | Leverages high-quality solutions to guide the evolution of other tasks [24] | Gaussian distribution models constructed from current populations and elite individuals generate offspring for knowledge transfer [24] |
| Similarity-Based Transfer | Dynamically identifies task relatedness to adjust transfer intensity [22] | Source Task Transfer (STT) strategy matches static features of historical tasks with dynamic evolution trends of target tasks [22] |
| Multi-Knowledge Fusion | Combines multiple knowledge types and transfer mechanisms [1] | Hybrid knowledge transfer strategies employ both individual-level and population-level learning based on task relatedness [1] |
Negative Transfer
Negative transfer represents the detrimental counterpart to positive transfer—it occurs when knowledge exchange between tasks impedes optimization performance, typically by misleading the search process or promoting convergence to suboptimal solutions [20] [22] [1]. This phenomenon poses a significant challenge in EMTO, as indiscriminate knowledge sharing can degrade performance below what would be achieved through independent task optimization.
The risk of negative transfer is particularly pronounced under two conditions: (1) when attempting knowledge transfer between high-dimensional tasks with differing dimensionalities, where learning robust mappings from limited population data becomes challenging [20]; and (2) when transferring knowledge between dissimilar or unrelated tasks, which can easily lead to premature convergence [20]. A classic example of this mechanism occurs when the global optimum of Task 1 (G1) is located in a decision space region corresponding to a local optimum for Task 2 (L2), and vice versa [20]. Transferring genetic material from high-performing individuals of Task 1 (near G1) to Task 2 then pulls the search for Task 2 away from its true global optimum (G2) and traps it in the basin of L2 [20].
Figure 1: Negative Transfer: Causes, Mechanisms, and Consequences
Random Mating Probability (RMP)
Random mating probability is a crucial control parameter in MFEA that directly governs the frequency of cross-task mating and knowledge transfer [20] [1]. The RMP determines whether two randomly selected parent individuals from the population with different skill factors will undergo crossover, thereby facilitating knowledge exchange between their respective tasks.
In the basic MFEA, RMP is typically implemented as a single scalar value, often set between 0.1 and 0.5 based on empirical studies [20]. When a random number generated during mating selection is less than the RMP value, crossover occurs regardless of the parents' skill factors; otherwise, assortative mating is favored (preferring parents with the same skill factor) [20]. This simple yet effective mechanism serves as the primary gateway for knowledge transfer in multifactorial evolution.
Advanced RMP Strategies and Interrelationships
Evolution Beyond Fixed RMP
While the basic MFEA employs a fixed RMP value, recent research has demonstrated that adaptive RMP strategies can significantly enhance algorithmic performance by dynamically adjusting transfer intensity based on online assessments of task relatedness and transfer effectiveness [23] [1].
One prominent approach replaces the scalar RMP with an RMP matrix that captures non-uniform inter-task synergies across different task pairs [1]. In MFEA-II, this matrix is continuously learned and adapted during the search process, allowing the algorithm to automatically identify which task pairs benefit from knowledge sharing and which should be isolated to prevent negative transfer [1].
Alternative adaptive strategies adjust RMP based on the success rate of cross-task transfers. For instance, some algorithms compare the success rate of individuals generated through knowledge transfer versus those generated within the same task, using this information to adaptively adjust the RMP value to promote positive transfer [23]. Other approaches employ more sophisticated mechanisms, such as ResNet-based dynamic skill factor assignment, which integrates high-dimensional residual information and task relationship learning to optimize individual adaptability across tasks [16].
Table 3: Comparative Analysis of RMP Strategies
| RMP Strategy | Mechanism | Advantages | Limitations |
|---|---|---|---|
| Fixed RMP | Uses a single, predetermined value for all task pairs [20] | Simple implementation, computationally efficient | Cannot adapt to varying task relatedness, high risk of negative transfer |
| Matrix RMP | Employs a matrix to capture different transfer intensities between each task pair [1] | Captures non-uniform inter-task synergies, reduces negative transfer | Increased complexity, requires sufficient population data for estimation |
| Success-Based Adaptive RMP | Adjusts RMP based on online measurement of transfer success rates [23] | Responsive to actual transfer effectiveness, promotes positive transfer | Success rate metrics may be noisy, delayed response to landscape changes |
| Prediction-Based RMP | Uses machine learning models (e.g., decision trees) to predict beneficial transfers [1] | Potentially more precise transfer control, can anticipate beneficial exchanges | High computational overhead, requires careful feature engineering |
The Interplay of Positive Transfer, Negative Transfer, and RMP
The relationship between positive transfer, negative transfer, and RMP forms the fundamental dynamic that governs knowledge exchange in EMTO. These three elements exist in a delicate balance where the RMP parameter serves as the primary regulator between the beneficial and detrimental effects of knowledge transfer.
When RMP is set too low, the algorithm restricts knowledge exchange between tasks, potentially missing opportunities for positive transfer and effectively reducing the optimization to parallel single-task evolution [20]. Conversely, when RMP is set too high, excessive cross-task mating increases the risk of negative transfer, particularly between unrelated or competing tasks [20] [1]. The optimal RMP setting therefore depends critically on the degree of relatedness between tasks and the complementarity of their fitness landscapes.
Figure 2: RMP Configuration Workflow for Balancing Knowledge Transfer
Advanced EMTO algorithms address this challenge through several sophisticated approaches:
Online similarity detection: Algorithms like MOMFEA-STT establish parameter sharing models between historical and target tasks, automatically identifying association degrees between different tasks to adjust cross-task knowledge transfer intensity [22].
Transfer ability prediction: The EMT-ADT algorithm defines an evaluation indicator to quantify the transfer ability of each individual and constructs a decision tree to predict this ability, selecting only promising positive-transferred individuals for knowledge exchange [1].
Domain adaptation: Techniques like MDS-based linear domain adaptation create low-dimensional subspaces for each task and learn mapping relationships between these subspaces, enhancing the potential for positive transfer even between tasks with differing dimensionalities [20].
Experimental Protocols and Assessment Methodologies
Standardized Benchmarking Approaches
Rigorous experimental evaluation is essential for assessing the effectiveness of knowledge transfer strategies in EMTO. Researchers have developed standardized benchmarking protocols to enable fair comparisons between algorithms.
For single-objective multitask optimization, the CEC2017 MFO benchmark problems provide a comprehensive test suite featuring tasks with varying degrees of relatedness, different dimensionalities, and diverse fitness landscape characteristics [1]. For multi-objective multitask optimization, the WCCI20-MTSO and WCCI20-MaTSO benchmark problems offer specialized testing environments [22] [1].
Performance assessment typically employs two complementary metrics: (1) convergence speed, measured by the number of function evaluations required to reach a target solution quality, and (2) solution accuracy, evaluated by the best objective value achieved within a fixed computational budget [20] [1]. For comprehensive assessment, these metrics are computed separately for each component task and aggregated to provide an overall performance measure.
Quantifying Knowledge Transfer Effects
Measuring the actual occurrence and impact of knowledge transfer requires specialized experimental designs:
Ablation studies: Researchers implement algorithm variants with specific transfer mechanisms disabled (e.g., setting RMP=0) to isolate the contribution of knowledge transfer to overall performance [20].
Success rate monitoring: Tracking the proportion of cross-task generated offspring that outperform their parents provides a direct measure of positive transfer effectiveness [23].
Population diversity metrics: Measuring genotypic and phenotypic diversity within task-specific subpopulations helps assess whether knowledge transfer is enhancing exploration or causing premature convergence [20].
Table 4: Research Reagent Solutions for EMTO Experiments
| Research Reagent | Function | Example Implementation |
|---|---|---|
| CEC2017-MTSO Benchmark | Standardized test problems for single-objective MTO [1] | Provides controlled environment with known task relatedness for algorithm comparison |
| WCCI20-MTSO/MaTSO Benchmark | Specialized test suites for multi-objective MTO [22] [1] | Enables evaluation of algorithms on complex multi-objective multitasking scenarios |
| Skill Factor Assignment | Mechanism for identifying an individual's specialized task [1] [21] | τᵢ = argmin{rij} where rij is the factorial rank of individual i on task j |
| Factorial Cost Calculation | Unified evaluation metric across tasks [21] | Ψⱼⁱ = γδⱼⁱ + Fⱼⁱ where Fⱼⁱ is objective value and δⱼⁱ is constraint violation |
| Scalar Fitness Computation | Cross-task performance measure for selection [1] [21] | φᵢ = 1/min{rij} enabling comparison of individuals across different tasks |
Positive transfer, negative transfer, and random mating probability represent three interconnected pillars that support the theoretical and practical framework of evolutionary multitasking optimization. The effective management of knowledge transfer through appropriate RMP strategies separates successful EMTO implementations from those that fail to realize the promised benefits of multitasking.
Future research directions in this domain include the development of more sophisticated transferability assessment mechanisms, potentially leveraging deep learning architectures like the VDSR model used in MFEA-RL for generating high-dimensional residual representations of individuals [16]. Additionally, the application of EMTO to complex real-world problems in drug development and personalized medicine presents promising opportunities for demonstrating the practical value of controlled knowledge transfer [2] [25].
As the field progresses, the balanced orchestration of positive and negative transfer through adaptive RMP mechanisms will continue to be essential for unlocking the full potential of evolutionary multitasking optimization across scientific and engineering domains.
MFEA Implementation Strategies and Real-World Applications in Biomedical Research
Multifactorial Evolutionary Algorithms (MFEAs) represent an advanced paradigm within evolutionary computation that enables the simultaneous solution of multiple optimization tasks in a single run. This innovative approach falls under the broader field of Evolutionary Multitasking (EMT), which leverages the implicit parallelism of population-based search to exploit potential synergies between different optimization tasks and problems [26]. Unlike traditional evolutionary algorithms that focus on solving a single problem, MFEAs are designed to handle multiple tasks concurrently, allowing for knowledge transfer and genetic exchange between populations evolving for different objectives [9]. The fundamental insight behind MFEAs is that the process of searching for optimal solutions to one task may contain valuable information that can assist in solving other related tasks, thereby accelerating convergence and improving solution quality across all optimization problems.
MFEAs have demonstrated remarkable success across diverse domains, particularly in complex industrial scenarios where multiple interrelated optimization problems must be addressed simultaneously [9]. The architectural foundation of MFEAs enables them to maintain distinct populations for different tasks while permitting controlled genetic exchange through carefully designed mechanisms. This multifactorial approach has proven especially valuable in data-rich environments where optimization tasks share common characteristics or underlying structures, allowing the algorithm to discover solutions that would be challenging to find when tasks are optimized in isolation [25].
Core Components of MFEA Architecture
Population Initialization Strategies
Population initialization in Multifactorial Evolutionary Algorithms establishes the foundation for effective evolutionary search across multiple tasks. Unlike single-task evolutionary algorithms, MFEA requires specialized initialization that considers the diverse characteristics of all tasks involved. The process typically begins with the creation of a unified search space that encompasses the solution domains of all tasks, allowing for seamless knowledge transfer during evolution [9].
Unified Genomic Representation: MFEAs employ a normalized encoding scheme that maps candidate solutions from different tasks into a common representational space. This unified approach enables direct comparison and genetic exchange between individuals from different tasks, facilitated by a multifactorial encoding that incorporates task-specific and shared genetic information [25].
Diversity-Aware Sampling: Effective initialization strategies prioritize population diversity to prevent premature convergence. This involves sophisticated sampling techniques that ensure adequate coverage of each task's search space while maintaining a balanced distribution of individuals across all tasks. Research has demonstrated that populations initialized with 30-50 individuals per task provide sufficient diversity without excessive computational overhead [25].
Knowledge-Informed Seeding: Advanced MFEA implementations may incorporate domain knowledge during initialization through heuristic seeding. This approach strategically positions initial individuals in promising regions of the search space based on prior knowledge or quick preliminary evaluations, significantly accelerating convergence for complex tasks [9].
Genetic Operators in MFEA
Genetic operators in MFEA must facilitate both task-specific optimization and cross-task knowledge transfer. These operators are carefully designed to balance exploitation within individual tasks and exploration across the unified search space.
Assortative Mating and Vertical Cultural Transmission: MFEA implements selective reproduction mechanisms where individuals are more likely to mate with others from the same task, while allowing controlled inter-task crossover. This assortative mating preserves task-specific schemata while permitting beneficial genetic exchange between tasks [9].
Multifactorial Inheritance: During reproduction, offspring inherit genetic material through a skill-factor based inheritance mechanism. This ensures that children receive appropriate genetic information relevant to their assigned tasks, maintaining solution feasibility and quality across the multifactorial environment [25].
Adaptive Mutation Strategies: MFEA employs task-aware mutation operators that apply appropriate perturbation strategies based on the characteristics of each task. These operators balance exploration and exploitation by adapting mutation rates and operators according to task complexity and convergence behavior [9].
Table 1: Key Genetic Operators in Multifactorial Evolutionary Algorithms
| Operator Type | Function | Key Parameters | Impact on Search |
|---|---|---|---|
| Assortative Mating | Controls reproduction between individuals | Random Mating Probability | Balances genetic transfer vs. task specificity |
| Cross-task Crossover | Enables knowledge transfer between tasks | Transfer Rate, Selectivity | Facilitates cross-task optimization synergy |
| Adaptive Mutation | Maintains diversity and enables exploration | Mutation Rate, Strategy | Prevents premature convergence |
| Skill-factor Inheritance | Assigns task affinity to offspring | Inheritance Mode | Preserves task-relevant genetic material |
Advanced Genetic Operator Mechanisms
Trait Segregation in Genetic Operations
The recently proposed Mutagenic Multifactorial Evolutionary Algorithm based on trait segregation (M-MFEA) introduces a biologically-inspired mechanism that naturally guides genetic exchanges without requiring manually predefined parameters [9]. This approach models dominant and recessive traits within the unified multitasking search space, enabling individuals to spontaneously guide evolution according to their trait expressions.
Trait segregation operates through three sophisticated mechanisms:
Trait Expression Classification: Each individual's genetic material is classified as either dominant or recessive based on its performance across different tasks. This classification enables the algorithm to prioritize the propagation of high-value genetic material while maintaining diversity through recessive traits [9].
Mutagenic Genetic Information Interaction: This strategy enhances information transfer within and across tasks by allowing individuals with dominant traits to influence the evolutionary direction. The system facilitates targeted knowledge exchange between individuals exhibiting complementary trait expressions, maximizing the beneficial aspects of genetic transfer [9].
Adaptive Mutagenic Gene Inheritance: This mechanism drives continuous task convergence by selectively promoting the inheritance of genetic material that demonstrates strong performance across multiple tasks. The system dynamically adjusts inheritance patterns based on real-time performance feedback, optimizing knowledge transfer throughout the evolutionary process [9].
Knowledge Transfer in Multitasking Environments
Effective knowledge transfer represents the cornerstone of successful multifactorial optimization. MFEAs implement sophisticated transfer adaptation mechanisms that dynamically regulate the flow of genetic information between tasks:
Online Transfer Parameter Estimation: Advanced MFEA variants continuously monitor the effectiveness of cross-task genetic transfers and automatically adjust transfer rates using fitness-based rules and diversity metrics. This approach maximizes positive transfer while minimizing negative interference between tasks [9].
Cross-Domain Knowledge Screening: MFEAs employ filtering mechanisms that identify and prioritize the most valuable genetic material for transfer between tasks. This screening process evaluates both genetic similarity and performance characteristics to determine the potential utility of candidate genetic material for different tasks [25].
Multi-Phase Transfer Operations: Sophisticated MFEA implementations utilize distinct transfer strategies during different evolutionary phases. Early phases emphasize exploratory transfer to broadly sample the search space, while later phases focus on exploitative transfer to refine promising solutions [25].
Diagram 1: Workflow of Multifactorial Evolutionary Algorithm with Trait Segregation
Experimental Protocols and Parameter Configuration
Standard Experimental Protocol for MFEA
Implementing a comprehensive experimental protocol for MFEA requires careful attention to parameter configuration, evaluation metrics, and termination criteria. The following protocol outlines the standard methodology for conducting MFEA experiments:
Population Initialization Protocol:
- Define unified search space encompassing all task domains
- Initialize population with 30-50 individuals per task to maintain diversity
- Apply domain-specific heuristics for seeding when available
- Evaluate initial fitness across all tasks
- Classify individuals based on skill factors and trait expressions [9] [25]
Evolutionary Cycle Configuration:
- Set maximum generations to 150-400 based on task complexity
- Configure assortative mating with random mating probability of 0.3-0.6
- Establish adaptive mutation rates starting at 0.1 and decreasing based on convergence
- Implement cross-over probability of 0.6 for genetic exchange
- Define selection pressure parameters to maintain elitism while preserving diversity [25]
Evaluation and Termination:
- Implement multifactorial fitness evaluation across all tasks
- Apply knowledge transfer effectiveness monitoring
- Track population diversity metrics
- Define convergence criteria based on fitness improvement thresholds
- Implement early termination for stalled optimization tasks [9]
Performance Evaluation Methodology
Rigorous performance evaluation is essential for validating MFEA effectiveness. The standard methodology incorporates both quantitative metrics and qualitative analysis:
Solution Quality Assessment:
Knowledge Transfer Effectiveness:
- Positive transfer quantification
- Negative interference measurement
- Genetic material utility analysis
- Cross-task synergy identification [25]
Table 2: Standard Parameter Configuration for MFEA Experiments
| Parameter Category | Specific Parameter | Recommended Value | Adjustment Guidelines |
|---|---|---|---|
| Population Settings | Population Size | 30-50 individuals/task | Increase for complex task sets |
| Initialization Method | Heuristic + Random | Domain knowledge dependent | |
| Evolutionary Operators | Crossover Probability | 0.6 | Reduce for highly dissimilar tasks |
| Mutation Probability | 0.1 | Increase for maintaining diversity | |
| Random Mating Probability | 0.3-0.6 | Task similarity dependent | |
| Knowledge Transfer | Transfer Rate | Adaptive | Based on online performance |
| Selectivity | High | Prefer high-performing individuals | |
| Termination Criteria | Maximum Generations | 150-400 | Task complexity dependent |
| Fitness Threshold | Task-specific | Based on problem domain |
The Scientist's Toolkit: Research Reagent Solutions
Implementing effective MFEA research requires both computational tools and methodological components. The following table outlines essential "research reagents" for conducting multifactorial evolutionary optimization experiments:
Table 3: Essential Research Reagents for MFEA Implementation
| Research Reagent | Function | Implementation Example |
|---|---|---|
| Unified Representation Schema | Encodes solutions from different tasks into common space | Normalized genomic representation supporting multiple data types |
| Trait Segregation Module | Classifies and manages dominant/recessive traits | Trait expression classifier based on cross-task performance |
| Adaptive Transfer Controller | Dynamically regulates knowledge transfer between tasks | Fuzzy rule-based system adjusting transfer rates |
| Multitasking Benchmark Suite | Evaluates algorithm performance across diverse tasks | Synthetic and real-world problem sets with known optima |
| Fitness Landscape Analyzer | Characterizes search space structure and difficulty | Ruggedness measurement via fitness-distance correlation |
| Negative Transfer Detector | Identifies and mitigates harmful knowledge exchange | Performance monitoring with rollback capability |
| Pareto Archive System | Maintains diverse non-dominated solutions for multi-objective tasks | Elite preservation with diversity mechanisms |
The architectural principles governing population initialization and genetic operators in Multifactorial Evolutionary Algorithms represent a significant advancement in evolutionary computation. Through sophisticated population initialization strategies that establish unified search spaces and maintain diversity, and advanced genetic operators that enable controlled knowledge transfer through mechanisms like trait segregation, MFEAs effectively leverage synergies between optimization tasks. The experimental protocols and parameter configurations outlined in this work provide researchers with practical guidelines for implementing these algorithms across diverse domains.
The continuing evolution of MFEA architectures, particularly through biologically-inspired mechanisms like trait segregation and adaptive knowledge transfer, promises to further enhance the capabilities of these algorithms for tackling complex, real-world optimization problems. As research in this field progresses, the refinement of population initialization techniques and genetic operators will undoubtedly lead to more efficient and effective multifactorial optimization across an expanding range of applications.
This whitepaper provides an in-depth technical examination of two fundamental knowledge transfer mechanisms—assortative mating and vertical cultural transmission—within the context of multifactorial evolutionary algorithm (MFEA) research. These biologically-inspired mechanisms enable efficient cross-task knowledge exchange, forming the cornerstone of evolutionary multitasking optimization. We present quantitative analyses of both biological foundations and algorithmic implementations, detailed experimental methodologies, and visual representations of core workflows. For researchers and drug development professionals, this guide offers both theoretical understanding and practical frameworks for implementing these advanced optimization techniques in complex problem domains.
Multifactorial evolutionary algorithms represent a paradigm shift in optimization by enabling concurrent solution of multiple tasks through implicit genetic transfer. The efficacy of MFEAs hinges critically on two biologically-inspired knowledge transfer mechanisms: assortative mating and vertical cultural transmission [15]. These mechanisms facilitate the exchange of valuable genetic material between optimization tasks, often leading to accelerated convergence and enhanced solution quality.
In biological systems, assortative mating refers to the non-random mating pattern where individuals with similar phenotypes mate more frequently than would be expected under random pairing [27]. The algorithmic equivalent enables individuals solving similar tasks to exchange genetic information, thereby transferring beneficial traits across task boundaries. Vertical cultural transmission, derived from cultural evolution theory, describes how knowledge, behaviors, and beliefs are passed from parents to offspring [28]. In MFEAs, this mechanism governs how offspring inherit and recombine parental genetic material across different optimization tasks.
The integration of these mechanisms within MFEA frameworks has demonstrated significant performance improvements across diverse applications including drug discovery, supply chain optimization, and industrial process control [9] [1]. By leveraging these natural paradigms, researchers can address increasingly complex optimization challenges in scientific and industrial domains.
Quantitative Foundations of Assortative Mating
Biological Evidence and Metrics
Assortative mating has been extensively studied in human populations for traits such as educational attainment and intelligence. Large-scale twin studies in Finland and the Netherlands provide robust quantitative evidence for this phenomenon, as summarized in Table 1.
Table 1: Quantitative Studies of Assortative Mating for Educational Attainment
| Country | Sample Size | Spousal Correlation | Phenotypic Assortment Contribution | Social Homogamy Contribution |
|---|---|---|---|---|
| Finland | 1,451 twin-spouse pairs | 0.51 | 0.35 | 0.16 |
| Netherlands | 1,616 twin-spouse pairs | 0.45 | 0.30 | 0.15 |
Data sourced from [27] reveals that assortative mating for educational attainment occurs through two primary mechanisms: phenotypic assortment (direct selection based on observable traits) and social homogamy (indirect selection through shared social environments). The spousal correlations of 0.51 (Finland) and 0.45 (Netherlands) significantly exceed what would be expected under random mating conditions, confirming strong assortative patterns [27].
For intelligence, studies controlling for assortative mating reveal different variance components than classical twin studies, with additive genetic factors accounting for 44%, non-additive genetic factors 27%, assortative mating 11%, and non-shared environment 18% of variance [29]. This highlights how unmodeled assortative mating can bias heritability estimates in traditional genetic studies.
Algorithmic Implementation and Parameters
In MFEA implementations, assortative mating is governed by the random mating probability (rmp) parameter, which controls the likelihood of cross-task reproduction [15] [1]. The fundamental algorithmic process can be represented as follows:
Table 2: Assortative Mating Parameters in MFEA
| Parameter | Standard Implementation | Adaptive Variants | Biological Analog |
|---|---|---|---|
| Random Mating Probability (rmp) | Fixed scalar value (typically 0.3-0.5) | Matrix-based adaptive estimation [1] | Mating preference strength |
| Skill Factor | Single task assignment per individual | Multi-task proficiency assessment | Phenotypic specialization |
| Factorial Rank | Performance ranking within task | Cross-task normalized ranking | Fitness-based selection |
Advanced implementations employ adaptive rmp strategies, such as the online transfer parameter estimation in MFEA-II, where rmp takes the form of a symmetric matrix capturing non-uniform inter-task synergies [1]. This allows the algorithm to dynamically adjust transfer intensities based on learned task relatedness throughout the optimization process.
Vertical Cultural Transmission Mechanisms
Biological and Cultural Foundations
Vertical cultural transmission represents the intergenerational transfer of information from parents to offspring [28]. In biological systems, this encompasses both genetic inheritance and the transfer of learned behaviors, strategies, and knowledge. Evolutionary models demonstrate that cultural transmission in the presence of natural selection may serve as an important mechanism for maintaining behavioral diversity in natural populations [28].
The dynamics of cultural transmission are governed by several key factors:
- Transmission fidelity: The accuracy with which information is transferred between generations
- Selective pressure: Environmental factors that favor certain cultural traits
- Transmission rate: The frequency of cultural exchange relative to genetic inheritance
In spatially structured environments, both vertical and oblique transmission (learning from non-parental individuals of the parental generation) can fluctuate, creating complex evolutionary dynamics that maintain cultural polymorphisms [30].
Algorithmic Implementation
Within MFEA frameworks, vertical cultural transmission manifests through the inheritance of genetic material and memetic information from parent solutions to offspring [15]. The key algorithmic components include:
- Skill factor inheritance: Offspring inherit task associations (skill factors) from parental solutions
- Genetic transfer: Chromosomal material is recombined from multiple parents potentially associated with different tasks
- Memetic learning: Successful solution strategies are transmitted across generations
The cultural transmission process in MFEA can be represented through the following workflow:
Diagram 1: Vertical Cultural Transmission in MFEA
This diagram illustrates how offspring solutions inherit and recombine genetic material from parents potentially associated with different optimization tasks, with skill factors assigned either through parental inheritance or random assignment.
Integrated Framework in Multifactorial Evolutionary Algorithms
The MFEA Architecture
The multifactorial evolutionary algorithm integrates both assortative mating and vertical cultural transmission within a unified optimization framework. The complete workflow combines these mechanisms as shown below:
Diagram 2: Integrated MFEA Workflow
This architecture enables multiple optimization tasks to be processed simultaneously within a single population, with knowledge transfer occurring through the coordinated operation of assortative mating and vertical cultural transmission.
Advanced Adaptive Transfer Strategies
Recent advances in MFEA research have introduced sophisticated transfer strategies to mitigate negative transfer between unrelated tasks:
Domain Adaptation Techniques: Methods like Linearized Domain Adaptation (LDA) transform search spaces to improve inter-task correlations [1], while Subdomain Evolutionary Trend Alignment (SETA) decomposes tasks into subdomains for more precise mapping [15].
Decision Tree Prediction: EMT-ADT uses decision trees to predict individual transfer ability, selecting only promising candidates for knowledge transfer [1].
Multi-Knowledge Transfer: Hybrid approaches combine individual-level and population-level learning strategies, adjusting based on task relatedness [1].
These advanced strategies demonstrate significantly improved performance on complex multitasking problems, particularly those with low inter-task relatedness.
Experimental Protocols and Methodologies
Benchmarking and Performance Evaluation
Robust experimental evaluation of MFEA performance employs standardized benchmark suites and evaluation metrics:
Table 3: Standard MFEA Benchmark Problems
| Benchmark Suite | Task Types | Evaluation Metrics | Key Parameters |
|---|---|---|---|
| CEC2017 MFO | Single-objective, multifactorial | Convergence speed, Solution accuracy | Success history, Population size |
| WCCI20-MTSO | Multi-task single-objective | Transfer efficiency, Negative transfer incidence | RMP matrix, Skill factor distribution |
| WCCI20-MaTSO | Many-task single-objective | Scalability, Computational efficiency | Migration interval, Topology |
Experimental protocols typically involve multiple independent runs with statistical significance testing (e.g., Wilcoxon signed-rank tests) to compare algorithm performance [1]. Performance is evaluated based on both solution quality (objective function values) and computational efficiency (function evaluations).
Biological Study Methodologies
The biological foundations of these mechanisms are established through rigorous experimental designs:
Twin-Spouse Studies: Comparing monozygotic and dizygotic twins and their spouses to disentangle genetic and environmental contributions to assortative mating [27]. Sample sizes typically exceed 1,000 twin-spouse pairs to ensure statistical power.
Extended Family Designs: Collecting psychometric data across multiple generations (parents, twins, siblings, spouses, offspring) to model cultural transmission pathways [29]. Sample sizes of approximately 1,300 individuals across 300+ families are common.
Longitudinal Assessments: Tracking phenotypic convergence over time to distinguish initial assortment from subsequent convergence [27].
These biological methodologies inform the algorithmic implementations by providing validated models of knowledge transfer mechanisms in natural systems.
Table 4: Essential Research Reagents and Computational Tools
| Resource | Function | Application Context |
|---|---|---|
| WAIS-IIIR Intelligence Test | Psychometric assessment of general intelligence | Quantifying phenotypic assortment for cognitive traits [29] |
| Dutch Twin Register (NTR) | Population cohort with genetic and phenotypic data | Large-scale studies of assortative mating and cultural transmission [27] |
| Finnish Twin Cohort (FTC) | Population-based twin registry with spouse data | Cross-cultural comparisons of assortative mating patterns [27] |
| Affinity Propagation Clustering | Density-based clustering algorithm | Task decomposition into subdomains in SETA-MFEA [15] |
| Decision Tree Classifier (Gini index) | Supervised machine learning model | Predicting individual transfer ability in EMT-ADT [1] |
| SHADE Algorithm | Success-history based parameter adaptation | Search engine for evolutionary multitasking optimization [1] |
These resources enable researchers to implement, validate, and extend the core mechanisms of assortative mating and vertical cultural transmission in both biological studies and algorithmic applications.
Assortative mating and vertical cultural transmission represent two fundamental knowledge transfer mechanisms with deep biological foundations and powerful algorithmic applications. The integration of these mechanisms within multifactorial evolutionary algorithms has created a robust framework for addressing complex optimization challenges across diverse domains. Future research directions include developing more sophisticated transfer ability prediction models, enhancing domain adaptation techniques for highly heterogeneous tasks, and expanding applications to emerging domains such as personalized medicine and drug discovery pipelines. As these mechanisms continue to evolve, they will undoubtedly unlock new capabilities in computational intelligence and optimization.
The process of drug discovery inherently involves the simultaneous optimization of multiple, often competing, objectives. A candidate molecule must demonstrate high target affinity, possess favorable pharmacokinetic properties (ADMET - Absorption, Distribution, Metabolism, Excretion, and Toxicity), and maintain synthetic accessibility. Traditional sequential optimization approaches struggle with this complexity, often leading to extensive timelines and high failure rates. Multifactorial Optimization (MFO) has emerged as a powerful computational paradigm that formally addresses this challenge by solving multiple distinct optimization tasks concurrently rather than sequentially [1].
Within evolutionary computation, Multifactorial Evolutionary Algorithms (MFEAs) leverage implicit genetic transfer mechanisms to enable knowledge transfer between related tasks. In the context of drug discovery, this translates to using insights gained from optimizing one molecular property to inform the optimization of another, thereby accelerating the overall design process. The core principle of "assortative mating" and "vertical cultural transmission" in MFEAs allows for a more efficient exploration of the vast chemical space by exploiting synergies between optimization objectives [1]. This review explores how de novo molecular design and multi-objective optimization are being integrated through advanced computational frameworks to transform modern drug discovery, with a specific focus on their foundations in multifactorial evolutionary algorithm research.
Core Computational Frameworks and Algorithms
Fundamentals of Multifactorial Evolutionary Algorithms
MFEAs represent a specialized class of evolutionary algorithms designed for concurrent optimization of multiple tasks. The algorithm maintains a single population of individuals, where each individual is evaluated against all tasks but possesses a specific "skill factor" indicating the task it performs best [1]. Key components include:
- Factorial Cost: The objective value of an individual for a specific task.
- Factorial Rank: The individual's performance ranking within the population for a given task.
- Scalar Fitness: A unified fitness measure derived from the best factorial rank across all tasks.
- Skill Factor: The index of the task at which the individual performs best.
Knowledge transfer between tasks is controlled by a key parameter called random mating probability (rmp), which determines the likelihood of cross-task crossover during reproduction. A critical challenge in MFEA implementation is managing negative transfer, where inappropriate knowledge exchange between unrelated tasks degrades performance. Advanced strategies like adaptive transfer based on decision trees (EMT-ADT) have been developed to quantify individual transfer ability and promote positive knowledge exchange [1].
Advanced Multi-Objective Optimization Frameworks
Recent research has produced sophisticated frameworks that address fundamental challenges in molecular optimization:
DyRAMO (Dynamic Reliability Adjustment for Multi-objective Optimization): This framework tackles reward hacking, where generative models exploit imperfections in predictive models to design molecules with falsely favorable predictions. DyRAMO dynamically adjusts reliability levels for each property prediction through Bayesian optimization, ensuring molecules are designed within the overlapping Applicability Domains (ADs) of all predictive models [31].
Uncertainty-Aware Reinforcement Learning: This approach integrates reinforcement learning with 3D molecular diffusion models while incorporating predictive uncertainty estimation. The framework balances multiple property objectives through a reward function that includes reward boosting, diversity penalty, and dynamic cutoff strategies, significantly improving the quality and drug-likeness of generated molecules [32].
The table below summarizes the core capabilities and applications of leading AI-driven drug discovery platforms that implement these advanced algorithms:
Table 1: Leading AI-Driven Drug Discovery Platforms and Their Clinical Progress (2025 Landscape)
| Platform/Company | Core AI Technology | Therapeutic Focus | Key Clinical Developments |
|---|---|---|---|
| Exscientia | Generative AI, Automated Precision Chemistry | Oncology, Immuno-oncology, Inflammation | CDK7 inhibitor (GTAEXS-617) in Phase I/II; LSD1 inhibitor (EXS-74539) Phase I initiated 2024 [33] |
| Insilico Medicine | Generative Chemistry, Deep Learning | Idiopathic Pulmonary Fibrosis, Oncology | ISM001-055 (TNIK inhibitor) showing positive Phase IIa results in IPF [33] |
| Schrödinger | Physics-Enabled Design, ML | Immunology, Oncology | TYK2 inhibitor (zasocitinib/TAK-279) advanced to Phase III trials [33] |
| Recursion | Phenomic Screening, AI | Multiple | Merged with Exscientia ($688M) to integrate phenomics with generative chemistry [33] |
| BenevolentAI | Knowledge-Graph Repurposing | Multiple | AI-driven target discovery and validation [33] |
Technical Methodologies and Experimental Protocols
De Novo Molecular Design with Deep Interactome Learning
The DRAGONFLY framework represents a significant advancement in de novo design by combining graph neural networks with chemical language models. This approach leverages a comprehensive drug-target interactome containing approximately 360,000 ligands, 2,989 targets, and 500,000 bioactivities [34]. The methodology involves:
Workflow Implementation:
- Interactome Construction: Create a bipartite graph connecting ligands to their macromolecular targets, with edges representing binding affinities ≤200 nM sourced from ChEMBL.
- Neural Network Architecture: Implement a graph-to-sequence model combining Graph Transformer Neural Networks (GTNN) with Long Short-Term Memory (LSTM) networks.
- Molecular Generation: Translate input graphs (2D for ligands, 3D for binding sites) into SMILES strings representing novel molecules with desired bioactivity and physicochemical properties.
- Property Optimization: Explicitly control for synthesizability (using Retrosynthetic Accessibility Score), novelty (scaffold and structural novelty metrics), and predicted bioactivity (QSAR models using ECFP4, CATS, and USRCAT descriptors) [34].
This framework operates without application-specific reinforcement or transfer learning, enabling "zero-shot" construction of targeted compound libraries. Prospective validation demonstrated successful generation of novel PPARγ partial agonists with confirmed binding modes through crystal structure determination [34].
DyRAMO Framework for Reliable Multi-Objective Optimization
The DyRAMO protocol addresses reward hacking through a structured three-step process:
Experimental Protocol:
Step 1: Reliability Level Setting
- Set reliability level ρi for each target property i
- Define Applicability Domains (ADs) using Maximum Tanimoto Similarity (MTS) threshold: a molecule enters the AD if its highest Tanimoto similarity to training set molecules exceeds ρi
Step 2: Molecular Design with AD Constraints
- Employ generative model (ChemTSv2 with RNN and Monte Carlo Tree Search)
- Define reward function: Reward = (Πvi^wi)^(1/Σwi) if si ≥ ρi for all properties, else Reward = 0
- Generate molecules maximizing reward while satisfying all AD constraints
Step 3: DSS Score Evaluation
- Calculate Degree of Simultaneous Satisfaction: DSS = (ΠScaleri(ρi))^(1/n) × RewardtopX%
- Use Bayesian Optimization to efficiently explore reliability level combinations
- Iterate until optimal balance between reliability and property optimization is achieved [31]
This framework successfully designed EGFR inhibitors with high reliability for three key properties: inhibitory activity, metabolic stability, and membrane permeability, including rediscovery of known approved drugs [31].
Uncertainty-Aware Reinforcement Learning for 3D Molecular Design
This methodology integrates diffusion models with multi-objective reinforcement learning for direct generation of 3D molecular structures:
Experimental Implementation:
Architecture Selection:
- Backbone: Equivariant Diffusion Model (EDM) maintaining E(3) equivariance for molecular geometries
- Forward Process: Add Gaussian noise to atomic coordinates and features: zt = αtx + σtε
- Reverse Process: Parameterized denoising: p(zt-1|zt,c) = N(zt-1; μθ(zt,t,c), σt²I)
Surrogate Model Integration:
- Train property predictors with uncertainty quantification for QED, SAS, and binding affinity
- Implement uncertainty-aware reward function with three auxiliary components:
- Reward boosting for objectives far from targets
- Diversity penalty to prevent mode collapse
- Dynamic cutoff strategy for sparse rewards
Training Protocol:
- Utilize three benchmark datasets: QM9, ZINC15, and PubChem Compound Database
- Compare against state-of-the-art baselines across multiple diffusion architectures
- Validate through Molecular Dynamics simulations and ADMET profiling
- Benchmark generated EGFR inhibitors against known inhibitors [32]
This approach has demonstrated superior performance in generating 3D molecules with optimal drug-like properties and binding stability comparable to known EGFR inhibitors.
Essential Research Reagents and Computational Tools
Successful implementation of de novo molecular design and multi-objective optimization requires specialized computational tools and platforms. The table below details key resources that form the foundation of modern AI-driven drug discovery research:
Table 2: Essential Research Reagent Solutions for AI-Driven Molecular Design
| Tool/Platform | Type | Primary Function | Key Features |
|---|---|---|---|
| CDD Vault | Scientific Data Management Platform | Structured data capture for AI workflows | RESTful API, structured assay data, bioisosteric suggestions, role-based permissions [35] |
| Dotmatics | Life Sciences R&D Software | Comprehensive research data management | Chemical registration, assay data management, integration with analytics tools [36] [35] |
| DRAGONFLY | Deep Learning Framework | De novo molecular design | Interactome-based learning, combines GTNN and LSTM, zero-shot library generation [34] |
| DyRAMO | Optimization Framework | Reliable multi-objective optimization | Dynamic reliability adjustment, Bayesian optimization, prevention of reward hacking [31] |
| ChemTSv2 | Generative Modeling Tool | Molecular design with constraints | RNN + Monte Carlo Tree Search, multi-objective optimization, AD integration [31] |
| DELi Platform | DNA-Encoded Library Informatics | Analysis of DEL data | Open-source, extensive documentation, academic accessibility [37] |
| AlphaFold 3 | Protein Structure Prediction | Protein-ligand interaction modeling | Improved accuracy for complex interactions, targeted therapeutic design [36] |
Integration Pathways and Future Directions
The integration of de novo molecular design with multifactorial optimization frameworks represents a paradigm shift in drug discovery. The convergence of these technologies enables:
- Accelerated Discovery Timelines: Exemplified by Insilico Medicine's progression of an idiopathic pulmonary fibrosis drug from target discovery to Phase I trials in just 18 months, compared to the traditional 5-year timeline [33].
- Enhanced Predictive Accuracy: Uncertainty-aware frameworks address the critical challenge of reward hacking, ensuring computational predictions translate to real-world efficacy [32] [31].
- Democratization of AI Tools: Open-source platforms like DELi increase accessibility to cutting-edge methodologies for academic researchers [37].
Future developments will likely focus on the synthesis of generative AI with closed-loop automation systems, increased incorporation of quantum computing for molecular simulations, and enhanced multi-modal integration of omics-derived features for precision therapeutics [38]. As these computational frameworks continue to mature, they will fundamentally reshape the pharmaceutical development landscape, enabling more efficient exploration of chemical space and higher success rates in clinical translation.
In the field of computer-aided drug discovery and materials science, the translation of molecular structures into a computer-readable format is a fundamental prerequisite for the application of artificial intelligence (AI). Molecular representation serves as the critical bridge between chemical structures and their predicted biological, chemical, or physical properties, forming the cornerstone of computational chemistry and drug design [39]. For decades, the Simplified Molecular Input Line Entry System (SMILES) has dominated as the primary string-based representation, providing a compact and efficient method to encode chemical structures as text strings [40] [39]. However, SMILES carries significant limitations that impede its effectiveness in AI-driven discovery pipelines, most notably its inability to guarantee molecular validity in generated strings [40] [41].
To address these shortcomings, Self-Referencing Embedded Strings (SELFIES) was introduced in 2020 as a robust alternative that ensures 100% syntactic and valency validity [40] [41]. This technical guide provides an in-depth comparison of these competing representation schemes, examining their technical foundations, performance characteristics, and implications for evolutionary algorithms in molecular optimization. Within the context of multifactorial evolutionary algorithm research, the choice of molecular representation directly influences the efficiency of chemical space exploration and the validity of generated structures, making this comparison particularly relevant for researchers developing next-generation molecular design systems [42].
Technical Foundations: SMILES and SELFIES Under the Hood
SMILES: Syntax and Limitations
SMILES represents molecular structures using ASCII characters to depict atoms, bonds, branches, and ring structures through a linear notation system [40]. The grammar utilizes atomic symbols (C, O, N, etc.), bond symbols (-, =, #), parentheses for branching, and numbers for ring closure points [43]. While widely adopted due to its human-readability and extensive support in cheminformatics tools, SMILES exhibits several critical limitations:
- Validity Issues: SMILES strings generated by AI models often produce semantically invalid structures due to syntax errors or valency violations [40] [41].
- Representational Ambiguity: A single molecule can have multiple valid SMILES representations, while different strings may correspond to the same molecule, creating inconsistency in database searches and comparative studies [40].
- Limited Robustness: The complex grammar for handling rings and branches is not locally represented, making SMILES particularly fragile in generative applications [43].
SELFIES: A Guaranteed-Validity Approach
SELFIES addresses SMILES' limitations through a novel grammar that ensures every possible string represents a valid molecular structure [40] [43]. Key innovations include:
- Symbolic Representation of Spatial Features: Instead of complex grammar, SELFIES uses single symbols to represent structural elements like rings and branches, with explicitly encoded lengths for these features [43].
- Validity Guarantee: Through its self-referencing grammar, SELFIES ensures 100% robustness, eliminating invalid outputs in generative models [41].
- Enhanced Exploration: The latent space of SELFIES-based variational autoencoders has been shown to be denser than that of SMILES by two orders of magnitude, enabling more comprehensive exploration of chemical space [40].
Table 1: Technical Comparison of SMILES and SELFIES Representations
| Feature | SMILES | SELFIES |
|---|---|---|
| Validity Guarantee | No | Yes (100% robust) |
| Multiple Representations per Molecule | Yes | Yes |
| Human Readability | High | Moderate |
| Representation of Rings | Numbers for closure | Dedicated symbols with size encoding |
| Representation of Branches | Parentheses | Dedicated symbols with length encoding |
| Adequacy for Generative AI | Limited due to validity issues | Excellent (guaranteed valid structures) |
| Chemical Space Coverage | Complete but with invalid regions | Complete without invalid regions |
| Required Token Vocabulary Size | Smaller | Larger due to specialized symbols |
Quantitative Performance Comparison in AI Applications
Performance in Molecular Property Prediction
Empirical evaluations demonstrate that the choice of molecular representation significantly impacts model performance in downstream prediction tasks. Recent studies have systematically compared SMILES and SELFIES across standardized benchmarks:
Table 2: Performance Comparison in Classification Tasks (ROC-AUC Scores)
| Dataset | Representation | Tokenization | Model Architecture | ROC-AUC | Reference |
|---|---|---|---|---|---|
| HIV | SMILES | Atom Pair Encoding (APE) | BERT-based | 0.817 | [40] |
| HIV | SMILES | Byte Pair Encoding (BPE) | BERT-based | 0.784 | [40] |
| Toxicology | SMILES | Atom Pair Encoding (APE) | BERT-based | 0.912 | [40] |
| Toxicology | SMILES | Byte Pair Encoding (BPE) | BERT-based | 0.861 | [40] |
| BBBP | SELFIES | Domain-Adapted Pretraining | Transformer | 0.901 | [44] |
| BACE | SELFIES | Domain-Adapted Pretraining | Transformer | 0.862 | [44] |
Table 3: Performance Comparison in Regression Tasks (RMSE Scores)
| Dataset | Representation | Model Type | RMSE | Reference |
|---|---|---|---|---|
| ESOL | SELFIES | SELFormer | 0.944 | [44] |
| ESOL | SMILES | ChemBERTa-77M | 1.081 | [44] |
| FreeSolv | SELFIES | Domain-Adapted | 2.511 | [44] |
| FreeSolv | SMILES | ChemBERTa-77M | 2.742 | [44] |
| Lipophilicity | SELFIES | Domain-Adapted | 0.746 | [44] |
| Lipophilicity | SMILES | Graph Neural Network | 0.795 | [44] |
Tokenization Strategy Interactions
The effectiveness of molecular representations is intricately connected to tokenization strategies. Recent research has revealed that Atom Pair Encoding (APE), specifically designed for chemical languages, significantly outperforms traditional Byte Pair Encoding (BPE) when applied to SMILES representations [40]. APE preserves the integrity and contextual relationships among chemical elements, thereby enhancing classification accuracy in BERT-based models [40]. For SELFIES, studies indicate that domain-adaptive pretraining of SMILES-pretrained transformers can achieve competitive performance without modifying the tokenizer or model architecture, demonstrating the adaptability of existing infrastructures to this robust representation [44].
Experimental Protocols and Methodologies
Domain Adaptation Protocol
A key experimental approach for comparing representations involves adapting SMILES-pretrained models to SELFIES. The following protocol outlines this process:
Objective: To investigate whether a SMILES-pretrained transformer can be adapted to SELFIES using domain-adaptive pretraining without architectural modifications [44].
Materials:
- Base Model: ChemBERTa-zinc-base-v1 (pretrained on SMILES)
- Dataset: 700,000 molecules from PubChem converted to SELFIES
- Computational Resources: Single NVIDIA A100 GPU (12-hour training time)
- Tokenizer: Original ChemBERTa tokenizer without vocabulary modification
Procedure:
- Tokenizer Compatibility Check: Verify that the SMILES-trained tokenizer can process SELFIES strings without excessive unknown tokens ([UNK]) or sequence truncation.
- Domain-Adaptive Pretraining: Employ masked language modeling on SELFIES-formatted molecules using the original tokenizer vocabulary.
- Embedding-Level Evaluation:
- Apply t-distributed stochastic neighbor embedding (t-SNE) for visualization
- Compute cosine similarity between molecular embeddings
- Perform regression on QM9 properties using frozen embeddings
- Downstream Fine-tuning: End-to-end model training on ESOL, FreeSolv, and Lipophilicity datasets with scaffold splitting.
Results Interpretation: The domain-adapted model achieved ROC-AUC scores of 0.901 (BBBP) and 0.862 (BACE), demonstrating that SELFIES adaptation can match or exceed SMILES baselines despite a 100-fold difference in pretraining data size [44].
Data Augmentation Protocol for Generative Tasks
Augmentation strategies differentially affect SMILES and SELFIES due to their structural differences:
Objective: To evaluate the impact of various augmentation techniques on molecular generation quality [45].
Materials:
- Dataset: ChEMBL molecules (1000 to 10000 compounds)
- Model: Recurrent Neural Network with LSTM
- Augmentation Techniques:
- SMILES enumeration (baseline)
- Token deletion (random, validity-enforced, protected)
- Atom masking (random, functional group-targeted)
- Bioisosteric substitution
- Self-training
Procedure:
- Augmentation Application: Apply each augmentation technique with varying perturbation probabilities (p = 0.05, 0.15, 0.30).
- Model Training: Train chemical language models on augmented datasets.
- Generation and Evaluation: Sample 1000 SMILES from each trained model and evaluate:
- Validity: Percentage of strings mapping to chemically valid molecules
- Uniqueness: Percentage of non-duplicated molecules
- Novelty: Percentage of generated molecules not in training set
Results Interpretation: Atom masking showed particular promise for learning physicochemical properties in low-data regimes, while token deletion enhanced scaffold diversity [45]. For SELFIES specifically, augmentation studies revealed a 5.97% improvement in classical models and 5.91% in hybrid quantum-classical models compared to SMILES [43].
Integration with Multifactorial Evolutionary Algorithms
Representation Implications for Evolutionary Search
Within multifactorial evolutionary algorithm research, molecular representation directly influences exploration efficiency and solution quality. Evolutionary algorithms for molecular generation, such as EvoMol, sequentially build molecular graphs through mutation operations [42]. The choice between SMILES and SELFIES representations carries significant implications:
- Search Space Structure: SELFIES eliminates invalid regions of the chemical space, creating a smoother fitness landscape for evolutionary optimization [42].
- Mutation Operator Design: SMILES requires validity checks after each mutation, while SELFIES guarantees valid offspring, reducing computational overhead [42].
- Diversity Maintenance: The inherent robustness of SELFIES enables more aggressive mutation strategies without generating invalid structures, enhancing exploration capabilities [41] [42].
Experimental Evidence in Evolutionary Contexts
Studies implementing evolutionary algorithms with different representations demonstrate distinct performance characteristics:
EvoMol Implementation:
- Representation: Molecular graphs with implicit hydrogens
- Mutation Set: 7 generic atomic-level mutations
- Validity Control: Canonical SMILES comparison for duplicate detection
- Performance: Excellent results on QED, penalized logP, and GuacaMol benchmarks, with competitive performance in organic materials optimization [42]
The interpretability of evolutionary algorithms combined with SELFIES' validity guarantee creates a powerful framework for de novo molecular design, particularly for exploring unfamiliar regions of chemical space [42].
Table 4: Essential Resources for SMILES/SELFIES Research
| Resource | Type | Function | Availability |
|---|---|---|---|
| RDKit | Cheminformatics Library | Molecular manipulation, canonicalization, descriptor calculation | Open Source |
| SELFIES Python Library | Specialized Library | Conversion between SMILES and SELFIES, validity-guaranteed generation | Open Source |
| Hugging Face Transformers | NLP Library | Transformer model implementation for chemical language models | Open Source |
| PubChem Database | Molecular Database | Large-scale source of molecular structures for training | Public |
| MoleculeNet | Benchmark Suite | Standardized datasets for performance evaluation | Open Source |
| ChemBERTa | Pretrained Model | SMILES-pretrained transformer for domain adaptation | Open Source |
| SELFormer | Pretrained Model | SELFIES-optimized transformer for property prediction | Open Source |
| Google Colab Pro | Computational Platform | GPU-accelerated model training and experimentation | Commercial |
| QM9 Dataset | Quantum Properties Dataset | Benchmark for quantum chemical property prediction | Public |
| ChEMBL | Bioactivity Database | Curated bioactivity data for drug discovery applications | Public |
The comparative analysis of SMILES and SELFIES representations reveals a nuanced landscape where performance advantages are context-dependent. While SELFIES provides crucial validity guarantees that enhance robustness in generative applications, SMILES maintains strong performance in property prediction tasks, particularly when paired with advanced tokenization strategies like Atom Pair Encoding [40] [46].
For multifactorial evolutionary algorithm research, SELFIES offers significant advantages by eliminating invalid regions from the search space, enabling more efficient exploration of chemical diversity [42]. The guaranteed validity reduces the need for expensive validity checks after each mutation operation, potentially accelerating evolutionary search. However, the optimal choice depends on specific research objectives: SMILES may suffice for predictive modeling with established architectures, while SELFIES excels in generative tasks and exploration of novel chemical spaces.
Future research directions include developing specialized tokenizers for SELFIES, exploring hybrid representation models, and creating unified frameworks that leverage the strengths of both representations across different stages of the molecular optimization pipeline [41]. As evolutionary algorithms continue to evolve for molecular design, the integration of robust representations like SELFIES will play a crucial role in enabling efficient exploration of the vast chemical space while ensuring the validity and synthesizability of discovered compounds.
In the analysis and optimization of complex networks, Influence Maximization (IM) represents a fundamental combinatorial problem focused on identifying a set of seed nodes that can maximize the spread of information or influence through a network [25] [47]. The practical application of IM spans critical domains including viral marketing, rumor control, public health initiatives, and infrastructure resilience planning [25] [48]. Traditional IM approaches often operate under the assumption of stable network conditions; however, real-world networks are consistently vulnerable to structural disruptions including link-based failures, targeted attacks, and random component failures [25].
The extension of IM to Robust Influence Maximization (RIM) specifically addresses the challenge of maintaining influence spread under such uncertain or adverse conditions [25] [47]. When multiple competing entities or propagation groups exist within a network, the problem further evolves into the Robust Competitive Influence Maximization (RCIM) problem [25]. Solving these robust variants requires methodologies that can effectively navigate multiple potential damage scenarios and identify seed sets that perform consistently well across various network conditions.
This technical guide explores the application of Multifactorial Evolutionary Algorithms (MFEAs) as an advanced computational framework for addressing these robust influence maximization challenges. MFEAs belong to the class of multitasking optimization paradigms that enable the simultaneous optimization of multiple tasks or scenarios, leveraging potential synergies and shared information between them to achieve superior overall performance [25] [2]. By formulating robust influence maximization under multiple scenarios as a multitasking optimization problem, MFEAs can exploit the implicit correlations between different damage scenarios to identify solutions with enhanced stability and influential capability [25].
Theoretical Foundations
Influence Maximization in Complex Networks
The Influence Maximization problem is formally defined as identifying a set of k seed nodes within a network G = (V, E) that maximizes the expected number of activated nodes under a specific diffusion model [47]. The fundamental IM problem is classified as NP-hard, creating significant computational challenges for exact solution methods, especially in large-scale networks [47]. Basic IM approaches typically consider a single diffusion scenario with stable network topology.
The Competitive Influence Maximization (CIM) extension addresses environments where multiple propagative groups compete for influence within the same network [25]. This scenario mirrors real-world contexts such as competing marketing campaigns or ideological propagation. In CIM problems, the objective shifts to identifying seeds that can maximize influence for a specific group while considering the opposing influence from competitor groups [25].
Robustness in Network Optimization
Network robustness refers to a network's ability to maintain its structural integrity and functional performance when facing component failures or targeted attacks [25]. Common metrics for evaluating network robustness include:
- Structural integrity measured through connectivity changes during attacks
- Spectral metrics derived from graph eigenvalues
- Percolation-based metrics assessing connectivity under node or link removal [25]
For influence maximization, robustness extends beyond mere connectivity to encompass the preservation of influence propagation capability under structural damage. This introduces the Robust Influence Maximization (RIM) problem, which seeks seed sets that maintain high influence spread across multiple potential damage scenarios [25].
From Single-Objective to Multitasking Optimization
Traditional approaches to RIM often aggregate multiple scenarios into a single objective function, potentially obscuring scenario-specific optima [25]. The multitasking optimization paradigm represents a paradigm shift by simultaneously addressing multiple optimization tasks within a unified search process [25] [2].
Multitasking optimization exploits the genetic complementarity between tasks, allowing knowledge gained from optimizing one scenario to inform and enhance the optimization of other related scenarios [25]. This approach has demonstrated significant improvements in solution quality and search efficiency for complex, high-dimensional optimization problems [2].
Table 1: Evolution of Influence Maximization Problem Formulations
| Problem Formulation | Key Characteristics | Solution Approaches | Limitations |
|---|---|---|---|
| Basic IM | Single diffusion process, stable network topology | Greedy algorithms, heuristic methods, metaheuristics | Assumes ideal network conditions |
| Competitive IM (CIM) | Multiple competing diffusion processes | Game-theoretic approaches, extended greedy algorithms | Does not account for structural damage |
| Robust IM (RIM) | Single diffusion with multiple failure scenarios | Scenario aggregation, single-objective EAs | May lose scenario-specific optima |
| Robust CIM (RCIM) | Multiple competitors with multiple failure scenarios | Multitasking optimization, MFEAs | High computational complexity |
Multifactorial Evolutionary Algorithms
Fundamental Principles
Multifactorial Evolutionary Algorithms (MFEAs) represent a specialized class of evolutionary algorithms designed for simultaneous optimization of multiple tasks [2]. The core innovation in MFEAs lies in their ability to effectively transfer knowledge between related optimization tasks through a unified search process, leveraging potential genetic complementarity between tasks to accelerate convergence and improve solution quality [25] [2].
The MFEA framework introduces several key concepts:
- Multifactorial Optimization: Simultaneously solves multiple optimization tasks, each with potentially different objective functions and constraints
- Skill Factor: Assigns each individual in the population to a specific task based on its performance
- Factorial Cost: Evaluates each individual's performance across all tasks
- Cultural Transmission: Enables knowledge transfer between tasks through crossover operations [2]
In the context of robust influence maximization, each damage scenario or network condition can be treated as a distinct optimization task within the MFEA framework, allowing the algorithm to discover seed sets that perform robustly across multiple scenarios [25].
Algorithmic Framework for Robust Influence Maximization
The MFEA-RCIMMD (Multifactorial Evolutionary Algorithm for Robust Competitive Influence Maximization under Multiple Damage scenarios) represents a specialized implementation for robust influence maximization problems [25]. The algorithm incorporates several problem-specific components:
- Numerical Metric for Link Importance: A specially designed metric (Com-InfL) quantifies the importance of links in competitive networks, considering nodes' status in competitive environments [25]
- Multi-phase Transfer Operation: Facilitates knowledge transfer across different tasks (damage scenarios) while balancing cooperation and competition between potential rivals in the propagation process [25]
- Adaptive Genetic Operators: Modified crossover and mutation operators that consider diverse information from both genetic and fitness domains [25]
Table 2: Key Components of MFEA-RCIMMD for Robust Influence Maximization
| Component | Function | Implementation in RCIM Context |
|---|---|---|
| Unified Population | Maintains genetic material for all tasks | Single population containing solutions for multiple damage scenarios |
| Skill Factorization | Assigns individuals to specific tasks | Each solution evaluated on specific damage scenario |
| Assortative Mating | Controls crossover between individuals | Allows knowledge transfer between different scenario optimizations |
| Adaptive Genetic Operators | Maintain diversity and search efficiency | Problem-specific initialization, crossover, and mutation for network seeds |
| Multi-phase Transfer | Manages knowledge migration between tasks | Transfers influential seed patterns between damage scenarios |
Workflow and Implementation
The following diagram illustrates the complete MFEA-RCIMMD workflow for robust influence maximization:
Experimental Design and Methodologies
Network Datasets and Damage Scenarios
Comprehensive evaluation of robust influence maximization algorithms requires diverse network datasets with varying topological properties:
- Synthetic Networks: Generated using established models (e.g., Barabási-Albert for scale-free networks, Erdős-Rényi for random networks) with controlled parameters to test specific algorithmic aspects [25]
- Real-World Networks: Collected from actual social platforms, collaboration networks, communication networks, and biological systems to validate practical performance [25] [47]
Damage scenarios typically involve link-based failures with different removal percentages, simulating various attack intensities or failure rates [25]. The correlation between optimization processes directed at different damage scenarios should be analyzed to validate potential synergies that can be exploited by multitasking optimization [25].
Algorithm Configuration and Parameter Settings
The MFEA-RCIMMD requires careful parameter configuration to balance exploration and exploitation across multiple tasks:
- Population Size: Typically ranges from 30-100 individuals, with an initial population (Ω₀) of 30 and total population (Ω) of 50 [25]
- Genetic Operators: Crossover probability (pc) = 0.6, mutation probability (pm) = 0.1, local search probability (p_l) = 0.5 [25]
- Termination Criteria: Maximum generations (MaxGen) = 150 or computational budget-based stopping conditions [25]
- Task-Specific Parameters: Damage percentages, influence propagation models, and competitive parameters must be defined for each scenario [25]
Evaluation Metrics and Performance Assessment
Robust influence maximization algorithms require multi-faceted evaluation metrics:
- Influence Spread: Expected number of activated nodes under each damage scenario
- Robustness Stability: Consistency of influence spread across multiple damage scenarios
- Competitive Performance: Influence ratio compared to competing groups in competitive environments [25]
- Computational Efficiency: Runtime and scalability measurements, particularly important for large networks [48]
Experimental protocols should include comparisons with established baseline methods:
- Single-objective evolutionary algorithms solving each scenario independently
- Greedy algorithms with robustness modifications
- Heuristic methods based on network centrality measures [25] [48] [47]
Table 3: Experimental Configuration for Robust Influence Maximization
| Experimental Component | Configuration Parameters | Evaluation Metrics |
|---|---|---|
| Network Datasets | Synthetic networks (scale-free, small-world), Real-world networks (social, collaboration) | Number of nodes and edges, degree distribution, clustering coefficient |
| Damage Scenarios | Link removal percentages (10%, 20%, 30%), Random and targeted attacks | Correlation between scenarios, destruction severity |
| Algorithm Parameters | Population size: 50, Generations: 150, Crossover rate: 0.6, Mutation rate: 0.1 | Convergence behavior, parameter sensitivity |
| Influence Model | Competitive Independent Cascade Model, Weighted Propagation | Expected influence spread, competitive ratio |
| Comparison Methods | Single-objective EA, Greedy algorithms, Centrality heuristics | Influence spread, robustness, computational time |
Implementing multifactorial evolutionary approaches for robust influence maximization requires specific computational tools and analytical resources:
Table 4: Essential Research Tools for Robust Influence Maximization
| Tool/Resource | Function | Application in Robust IM |
|---|---|---|
| Network Analysis Libraries | Network manipulation and metric calculation | Python (NetworkX, igraph), MATLAB for network preprocessing and analysis |
| Evolutionary Algorithm Frameworks | Implementation of optimization algorithms | Custom MFEA implementations, PlatEMO, DEAP for evolutionary operations |
| Influence Propagation Simulators | Simulation of information diffusion | Custom cascade model implementations for competitive environments |
| High-Per Computing Resources | Parallel processing of multiple scenarios | Cloud computing, cluster computing for large-scale network experiments |
| Visualization Tools | Result analysis and interpretation | Gephi, Matplotlib, Graphviz for network and result visualization |
Advanced Applications and Future Directions
Interdisciplinary Applications
The MFEA framework for robust influence maximization extends beyond social network analysis to several interdisciplinary domains:
- Drug Design and Development: Multi-objective evolutionary algorithms optimize multiple molecular properties simultaneously, balancing efficacy, safety, and synthesizability in de novo drug design [49] [50] [51]
- RNA Sequence Design: Multiobjective evolutionary algorithms address the RNA inverse folding problem, optimizing multiple conflicting objective functions including partition function, ensemble diversity, and nucleotide composition [52]
- Personalized Recommendation Systems: Interactive multifactorial optimization with multidimensional preference surrogate models enhances recommendation diversity and novelty by transferring knowledge between different user preference models [2]
Emerging Methodological Innovations
Recent advances in computational intelligence continue to enhance multifactorial optimization capabilities:
- Hybrid Evolutionary Approaches: Combining MFEAs with local search, gravitational search algorithms, or invasive weed optimization to improve convergence and solution quality [48]
- Multimodal Large Language Model Integration: Leveraging MLLMs as evolutionary operators through visual encoding of network solutions, enabling human-like reasoning about network structures and solution quality [53]
- Deep Learning Enhancement: Utilizing recurrent neural networks and deep neural networks as decoders and property predictors in evolutionary molecular design, ensuring chemical validity while optimizing for target properties [51]
The following diagram illustrates the interdisciplinary applications and methodological innovations in multifactorial evolutionary optimization:
Multifactorial Evolutionary Algorithms represent a transformative approach for addressing Robust Influence Maximization under multiple scenarios. By formulating multiple damage scenarios as simultaneous optimization tasks, MFEAs effectively exploit correlations and synergies between scenarios to identify seed sets with enhanced robustness and influential capability. The MFEA-RCIMMD framework demonstrates significant performance improvements over traditional single-objective approaches while maintaining computational efficiency.
The principles and methodologies outlined in this technical guide provide researchers and practitioners with comprehensive foundation for implementing multifactorial optimization in complex network analysis. As evolutionary computation continues to integrate with emerging artificial intelligence paradigms including deep learning and large language models, the capabilities for solving robust optimization problems in networks will further expand, enabling more resilient and adaptive network-based systems across scientific and engineering domains.
The interdisciplinary applications of multifactorial optimization—from drug design to recommendation systems—highlight the versatility of this paradigm and its potential to address complex real-world problems requiring robust solutions under multiple competing scenarios and objectives.
The digital landscape is characterized by information overload, where users face an overwhelming abundance of choices across platforms including e-commerce, streaming services, and social media. Personalized recommendation systems have emerged as essential tools to mitigate this problem by filtering content and predicting user preferences. However, traditional approaches often rely on limited dimensions of user-item interactions, facing significant challenges including data sparsity and the cold start problem for new users or items with minimal interaction history [54]. These limitations have driven research toward more sophisticated modeling techniques capable of capturing the complex, multifaceted nature of human preferences.
Within this context, multifactorial evolutionary algorithms (MFEAs) present a transformative framework for advancing recommendation systems. Originally developed for evolutionary computation, MFEAs excel at solving multiple optimization tasks simultaneously by transferring knowledge between related problems [13] [9]. When applied to recommendation systems, this paradigm enables modeling of multidimensional user preferences by treating various preference dimensions—such as entity interactions, semantic preferences, and contextual factors—as interconnected optimization tasks. The fundamental advantage lies in the algorithm's ability to leverage implicit knowledge transfer between these preference dimensions, leading to more robust and accurate user representations that address the sparsity and cold start problems inherent in traditional approaches [13] [55].
Theoretical Foundations: From Evolutionary Computation to Multidimensional Preference Modeling
Core Principles of Multifactorial Evolutionary Algorithms
Multifactorial Evolutionary Algorithms represent a specialized class of evolutionary computation designed for multitask optimization problems. Unlike traditional evolutionary algorithms that address single tasks in isolation, MFEAs simultaneously solve multiple optimization tasks while facilitating implicit genetic transfer between them [9]. The foundational MFEA framework incorporates several key mechanisms:
Unified Genomic Representation: MFEAs employ a unified search space where a single chromosome representation can be decoded into task-specific solutions across multiple optimization problems. This encoding allows for knowledge transfer at the genetic level [13].
Implicit Genetic Transfer: Through crossover operations between individuals from different tasks, MFEAs enable the transfer of beneficial genetic material across tasks, allowing promising solution features discovered for one task to enhance performance in other related tasks [13] [9].
Skill Factor and Scalability Factor: These algorithmic components determine how individuals are assigned to specific tasks and how their fitness is evaluated across multiple tasks, ensuring balanced optimization across all problem domains [13].
Recent advances in MFEA research have introduced more sophisticated mechanisms. The Mutagenic MFEA based on trait segregation (M-MFEA) incorporates biological inspiration from trait expression patterns, defining dominant and recessive traits within the unified search space to guide evolutionary exchanges without manually predefined parameters [9]. This approach enables more natural information transfer within and across tasks, with an adaptive gene inheritance mechanism that drives continuous task convergence.
The Multidimensional Preference Modeling Paradigm
Multidimensional preference modeling represents a significant advancement beyond traditional collaborative filtering approaches by simultaneously considering multiple aspects of user preferences and contextual factors. This paradigm recognizes that user decision-making is influenced by interconnected preference dimensions that collectively determine item relevance [56] [55].
The multidimensional framework incorporates several critical preference types:
Entity Preferences: Direct user interactions with specific items or content, typically represented as historical ratings, clicks, or purchases [55].
Semantic Preferences: Latent preferences derived from the semantic content of user interactions, such as thematic interests extracted from conversation history or item descriptions [55].
Attribute Preferences: Preferences for specific item characteristics or features, such as product categories, directors, actors, or price ranges [56] [55].
Contextual Preferences: Situation-dependent factors including time, location, device type, and social context that influence user preferences dynamically [56].
Temporal Preferences: Evolution of user interests over time, capturing both long-term preference patterns and short-term interest shifts [57].
The integration of MFEAs with multidimensional preference modeling creates a powerful synergy where each preference dimension can be treated as an interrelated optimization task, enabling the system to leverage cross-dimensional knowledge transfer for enhanced recommendation accuracy and personalization.
Technical Implementation: Architecting MFEA-Driven Recommendation Systems
System Architecture and Workflow
The implementation of an MFEA-driven recommendation system follows a structured workflow that integrates multidimensional preference modeling with evolutionary optimization. The architecture comprises several interconnected components that collectively enable sophisticated recommendation generation.
Figure 1: MFEA-Driven Recommendation System Architecture
The workflow begins with multidimensional data collection from various sources including user interactions, item metadata, contextual information, and external knowledge graphs [54] [55]. This data undergoes preprocessing and feature extraction to construct comprehensive preference representations across multiple dimensions. The core MFEA optimization engine then processes these feature vectors through an evolutionary cycle of population initialization, skill factor assignment, multitask crossover, knowledge-guided mutation, and fitness evaluation [13] [9]. The output consists of optimized recommendation sets that balance multiple preference dimensions simultaneously.
Knowledge-Enhanced Preference Modeling
Advanced MFEA-driven recommendation systems incorporate structured knowledge sources to enhance preference modeling and address data sparsity challenges. The MPKE (Multi-Preference Modelling and Knowledge-Enhanced) framework demonstrates this approach through several innovative components [55]:
Domain-Specific Knowledge Graph Construction: Creating lightweight, domain-specific knowledge graphs (e.g., LMKG for movie recommendations) with higher coverage and lower noise compared to general-purpose knowledge bases like DBpedia [55].
Semantic Fusion Module: A cross-interaction mechanism that aligns the semantic spaces of external knowledge and dialogue text, mitigating semantic differences between diverse data signals [55].
Two-Stage Recommendation Mechanism: An exploration stage that identifies relevant attributes using semantic and entity preferences, followed by an integration stage that fuses semantic, entity, and attribute preferences for final recommendation generation [55].
This knowledge-enhanced approach enables the system to infer implicit user preferences even from sparse interaction data by leveraging the rich relational information embedded in structured knowledge sources.
Experimental Protocols and Evaluation Metrics
Rigorous experimental protocols are essential for validating MFEA-driven recommendation systems. Standard evaluation methodologies include:
Offline Evaluation: Using historical datasets with temporal splitting to assess predictive accuracy on past user interactions.
Online Evaluation: Deploying systems in controlled environments (A/B testing) to measure real-world performance metrics.
User Studies: Collecting qualitative feedback through controlled experiments with human participants to assess subjective satisfaction.
Table 1: Standard Evaluation Metrics for Recommendation Systems
| Metric Category | Specific Metrics | Interpretation | Use Cases |
|---|---|---|---|
| Predictive Accuracy | Root Mean Square Error (RMSE), Mean Absolute Error (MAE) | Measures how well predicted ratings match actual ratings | Evaluating rating prediction quality |
| Ranking Accuracy | Precision@K, Recall@K, Normalized Discounted Cumulative Gain (NDCG) | Measures the quality of the recommended item ranking | Top-N recommendation scenarios |
| Diversity and Coverage | Catalog Coverage, Personalization, Novelty | Measures the variety and novelty of recommendations | Assessing recommendation breadth |
| Business Metrics | Click-Through Rate (CTR), Conversion Rate, Retention | Measures real-world business impact | Online evaluation and A/B testing |
For MFEA-specific evaluation, additional metrics include:
Knowledge Transfer Efficiency: Measuring how effectively information is shared across preference dimension tasks.
Multitask Performance: Assessing whether simultaneous optimization of multiple preference dimensions outperforms isolated single-dimension optimization.
Convergence Behavior: Analyzing how quickly the algorithm reaches optimal solutions across tasks.
Comparative Analysis: MFEA-Driven Approaches vs. Traditional Methods
The integration of MFEA principles with recommendation systems demonstrates distinct advantages over traditional approaches across multiple performance dimensions.
Table 2: Comparison of Recommendation System Approaches
| Characteristic | Traditional Collaborative Filtering | Content-Based Methods | MFEA-Driven Multidimensional Approach |
|---|---|---|---|
| Preference Modeling | Single-dimensional (user-item interactions) | Multi-attribute (item features) | Multidimensional (entity, semantic, contextual) |
| Knowledge Transfer | Limited to similar user/item patterns | No transfer between domains | Explicit knowledge transfer between preference dimensions |
| Cold Start Performance | Poor for new users/items | Moderate for new users, good for new items | Enhanced through cross-dimensional knowledge transfer |
| Data Sparsity Handling | Limited, suffers from sparse interactions | Moderate, uses content features | Robust, leverages multiple data sources |
| Personalization Granularity | User and item level | Attribute and feature level | Multidimensional user preference profiling |
| Computational Complexity | Low to moderate | Moderate | Higher, but with superior optimization capabilities |
Empirical results demonstrate that MFEA-driven approaches achieve significant improvements over traditional methods. The Node-depth based Multifactorial Evolutionary Algorithm (NDE-MFEA) shows performance gains of up to 8.2% improvement in prediction accuracy compared to conventional collaborative filtering methods [13] [58]. The UITrust model, which incorporates entropy and classification information, demonstrates superior performance across multiple real-world datasets while reducing computational complexity compared to traditional k-nearest neighbor methods [58].
Implementing MFEA-driven recommendation systems requires specialized computational resources and frameworks. The following toolkit outlines essential components for research and development in this domain.
Table 3: Research Reagent Solutions for MFEA-Driven Recommendation Systems
| Resource Category | Specific Tools/Frameworks | Function/Purpose | Implementation Considerations |
|---|---|---|---|
| Evolutionary Computation Frameworks | DEAP, Platypus, PyGMO | Provide foundational evolutionary algorithms and optimization utilities | Custom MFEA extensions required for multitask optimization |
| Deep Learning Integration | TensorFlow, PyTorch, RecBole | Enable neural representation learning and hybrid model architectures | Essential for knowledge graph embeddings and semantic fusion |
| Knowledge Graph Management | Neo4j, Apache Jena, DGL-KE | Store and process structured knowledge for enhanced semantics | Domain-specific graph construction improves relevance |
| Vector Similarity Search | FAISS, Annoy, Milvus | Enable efficient nearest neighbor searches in embedding spaces | Critical for candidate generation in large item catalogs |
| Feature Processing & Storage | Feast, Hopsworks, Apache Hive | Manage feature engineering and ensure online-offline parity | Maintains consistency between training and serving environments |
| Evaluation Frameworks | RecList, Elliot, Cornac | Standardize experimental protocols and metric calculation | Ensures reproducible evaluation across studies |
Advanced Applications and Case Studies
Conversational Recommendation Systems
MFEA-driven multidimensional preference modeling demonstrates particular effectiveness in conversational recommendation systems (CRS), where systems must capture user preferences through natural language dialogues and provide high-quality recommendations with limited interaction history [55]. The MPKE framework exemplifies this application through:
Multi-preference Modeling: Simultaneously modeling entity preferences (mentioned items), semantic preferences (hidden intents in conversation), and attribute preferences (item characteristics) [55].
Dynamic Preference Updates: Adjusting preference weights based on real-time conversation flow and user feedback.
Explanation Generation: Utilizing word-level knowledge graphs (e.g., ConceptNet) to enhance keyword representation and construct explanation templates for diverse, descriptive system responses [55].
Experimental results demonstrate that this approach outperforms state-of-the-art methods in both recommendation accuracy and response quality, particularly in cold-start scenarios with limited initial user information.
Context-Aware Multidimensional Recommendation
Contextual information represents a critical dimension in personalized recommendation systems. MFEA-enabled approaches excel at integrating multiple contextual factors into the recommendation process:
Figure 2: Context-Aware Multidimensional Recommendation Framework
The Restaurant Recommendation Case Study illustrates this approach, where the system integrates user preferences (cuisine, budget, smoking preferences) with contextual factors (location, time, ambience) to provide highly personalized recommendations [56]. By treating each contextual dimension as a separate optimization task within the MFEA framework, the system efficiently balances multiple constraints and preferences to generate optimal recommendations for specific situational contexts.
Robust Influence Maximization in Social Networks
Beyond traditional recommendation scenarios, MFEA methodologies demonstrate effectiveness in robust influence maximization problems within social networks. The MFEA-RCIMMD algorithm addresses the challenge of identifying influential seed nodes in competitive networks under multiple potential damage scenarios [25]:
Multi-Scenario Optimization: Simultaneously optimizing seed sets for different network damage scenarios (link-based failures at various removal percentages).
Competitive Influence Modeling: Evaluating node importance in environments with multiple propagative groups having competing interests.
Knowledge Transfer Between Scenarios: Leveraging synergistic information across different damage scenarios to enhance solution quality and computational efficiency.
This application demonstrates the versatility of MFEA approaches beyond conventional recommendation tasks, extending to social network analysis and information diffusion optimization.
Future Research Directions and Challenges
Despite significant advances, MFEA-driven multidimensional recommendation systems face several challenges that present opportunities for future research:
Negative Transfer Mitigation: Developing more sophisticated mechanisms to prevent detrimental knowledge transfer between unrelated or conflicting preference dimensions [9] [25].
Computational Efficiency: Addressing the increased computational requirements of MFEA approaches while maintaining practical performance for real-time recommendation scenarios.
Dynamic Preference Evolution: Enhancing adaptability to evolving user preferences over time, particularly in environments with rapidly changing content and user interests.
Explainability and Transparency: Developing techniques to explain recommendations derived from complex multidimensional preference models, crucial for user trust and regulatory compliance.
Cross-Domain Recommendation: Extending MFEA methodologies to leverage knowledge transfer not just between preference dimensions but across entirely different recommendation domains.
The integration of MFEA principles with emerging artificial intelligence techniques—including large language models, neuromorphic computing, and federated learning—represents a promising trajectory for advancing the capabilities of personalized recommendation systems while addressing current limitations.
Multidimensional preference modeling represents a paradigm shift in personalized recommendation systems, moving beyond traditional single-dimensional approaches to capture the complex, multifaceted nature of user preferences. The integration of multifactorial evolutionary algorithms with this modeling framework enables sophisticated knowledge transfer between preference dimensions, leading to significant improvements in recommendation accuracy, personalization granularity, and performance in challenging scenarios including cold start and data sparsity.
As the digital landscape continues to evolve, MFEA-driven recommendation systems offer a powerful framework for addressing the growing complexity of user preference modeling while providing the computational foundation for next-generation personalized experiences across diverse domains including e-commerce, content streaming, social platforms, and conversational AI systems.
Advanced Optimization Techniques and Negative Transfer Mitigation Strategies
Multifactorial Evolutionary Algorithms (MFEAs) represent a paradigm shift in evolutionary computation, enabling the concurrent solution of multiple distinct optimization tasks within a single algorithmic run. This approach, known as Evolutionary Multi-Task Optimization (EMTO), leverages the implicit parallelism of population-based search to exploit potential synergies between tasks [1]. In practical applications, such as optimizing a complex supply chain, an MFEA can simultaneously handle shop scheduling (production optimization) and vehicle routing (logistics optimization) rather than treating them as separate, isolated problems [1]. The core mechanism enabling this efficiency is knowledge transfer between tasks, where genetic information from individuals solving one task is used to influence the population searching for solutions to another task.
However, the effectiveness of MFEA is critically dependent on the quality of this knowledge transfer. When tasks are related, transfer can lead to positive transfer, accelerating convergence and improving solution quality. Conversely, when unrelated tasks exchange information, negative transfer occurs, degrading performance and potentially causing search stagnation [1] [59]. Traditional MFEAs often use a fixed parameter, the random mating probability (rmp), to control transfer frequency without discerning the quality or relevance of the genetic material being transferred [1] [59]. This lack of discrimination is a significant limitation, as it permits individuals with little useful knowledge for other tasks to participate in crossover, wasting computational resources and hampering performance [1]. This paper focuses on an advanced strategy to overcome this precise challenge: using decision trees to intelligently select individuals for cross-task knowledge transfer, thereby promoting positive transfer and mitigating negative effects.
Decision Tree-Based Selection: Core Methodology
Quantifying Transfer Potential: The Foundation for Selection
The first step in a decision tree-based adaptive transfer strategy is to define and quantify the potential value an individual possesses for cross-task knowledge transfer. This is formalized through the concept of individual transfer ability.
In the MFEA context, an individual's fitness is evaluated across all tasks. Key properties used to assess individuals include [1]:
- Factorial Cost (( \Psij^i )): The raw objective function value of individual ( pi ) on task ( T_j ).
- Factorial Rank (( rj^i )): The rank of individual ( pi ) within the population when sorted ascendingly by its factorial cost on task ( T_j ).
- Skill Factor (( \taui )): The task index on which individual ( pi ) performs best (has the highest factorial rank).
An individual's transfer ability is then defined as an evaluation metric that quantifies the amount of useful knowledge it contains for other tasks [1]. While specific formulas can vary, this metric typically derives from the individual's performance profile across the multitasking environment. Individuals exhibiting high performance on their primary task (low factorial rank) while also demonstrating strong genetic building blocks that could benefit other tasks are assigned a high transfer ability score. This score serves as the target label for the supervised learning model in the subsequent step.
Constructing the Decision Tree Predictor
With a quantifiable measure of transfer ability, a decision tree model can be constructed to predict this value for new candidate individuals. A decision tree is a supervised machine learning method used for multi-stage decision-making, ideal for this task due to its interpretability and efficiency [1] [60].
The process for building the transfer ability prediction model is as follows [1] [61]:
Feature Selection: For each individual in the population, a set of descriptive features is extracted. These features can include:
- The individual's genotype (decision variable values).
- Its factorial costs and factorial ranks on all tasks.
- Its skill factor.
- Historical performance metrics.
- Measures of its genetic diversity relative to the population. Feature selection criteria, such as information gain, gain ratio, or the Gini index, are used to identify the most informative features for predicting transfer ability at each node in the tree [60].
Tree Generation: The dataset of individuals, described by their features and labeled with their pre-calculated transfer ability, is used to train the tree. The algorithm recursively splits the data based on the feature that best separates individuals with high and low transfer ability, forming a hierarchical structure of nodes and branches [1] [60].
Tree Pruning: To prevent overfitting and ensure the model generalizes well to new populations, the fully grown tree may be pruned. This involves removing branches that have negligible power in predicting transfer ability, simplifying the model without significantly sacrificing accuracy [60].
The Gini impurity index is a commonly used metric for determining the optimal splits during tree construction [1]. A pure node (Gini index = 0) contains only individuals belonging to a single class of transfer ability, while an impure node contains a mix.
Diagram 1: Decision Tree-based Individual Selection Workflow. This diagram visualizes the logical flow of an individual being evaluated by the decision tree model for transfer selection, based on features like its performance and genetic makeup.
Integration into the MFEA Cycle
The trained decision tree model is integrated into the MFEA's main evolutionary loop to act as an intelligent filter during the crossover phase. The modified algorithm, often referred to as EMT-ADT (Evolutionary Multi-Tasking with Adaptive Decision Tree), operates as shown in the workflow below [1].
Diagram 2: High-level Workflow of MFEA with Integrated Decision Tree. The diagram illustrates the four-phase cyclic process of the MFEA, highlighting the integration of the decision tree for selective mating in Phase 2.
This integration ensures that only individuals predicted to be valuable sources of knowledge are allowed to transfer their genetic material across tasks, thereby enhancing the probability of positive transfer and improving the overall robustness and efficiency of the optimization process.
Experimental Validation and Protocol
Benchmarking and Performance Metrics
The efficacy of the Decision Tree-based adaptive transfer strategy (EMT-ADT) is typically validated against state-of-the-art EMT algorithms on standardized benchmark problems. Commonly used benchmarks include the CEC2017 MFO problems, WCCI20-MTSO, and WCCI20-MaTSO benchmark sets, which provide a range of multi-task optimization environments with varying degrees of inter-task relatedness [1].
To quantitatively compare performance, the following metrics are employed in experimental protocols [1]:
- Solution Precision (Accuracy): The average objective function value of the best-found solution for each task at the end of the optimization run. Lower values indicate better performance for minimization problems.
- Convergence Speed: The number of generations or function evaluations required for the algorithm to reach a pre-defined solution quality threshold.
- Positive Transfer Rate: An indirect measure of the frequency with which cross-task crossover leads to an improvement in offspring quality compared to within-task crossover.
The performance of the decision tree model itself is also assessed using standard machine learning metrics, particularly when the prediction of transfer ability is treated as a classification problem (e.g., "High" or "Low" transfer ability) [60]. Key metrics include:
- Accuracy: The proportion of correct predictions over total predictions.
- Precision: The ratio of true positives (correctly identified high-transfer individuals) to all predicted positives.
- Recall: The ratio of true positives to all actual positives in the population.
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure.
Table 1: Key Metrics for Evaluating Decision Tree Model Performance in EMT-ADT
| Metric | Description | Role in Evaluating Transfer Strategy |
|---|---|---|
| Accuracy | Proportion of correct transfer ability predictions | Measures the model's overall correctness in selecting individuals. |
| Precision | Ratio of true high-ability to all predicted high-ability | Evaluates the reliability of the selection; high precision minimizes false positives (negative transfer). |
| Recall | Ratio of predicted high-ability to all actual high-ability | Assesses the model's ability to identify all promising individuals for transfer. |
| F1-Score | Harmonic mean of Precision and Recall | Balances precision and recall for a comprehensive performance evaluation. |
Comparative Performance Analysis
Experiments comparing EMT-ADT with other MFEAs demonstrate its competitiveness. The core advantage lies in its targeted approach to knowledge transfer. For instance, the proposed EMT-ADT has been shown to be highly competitive compared to other state-of-the-art algorithms like MFEA-II and MFEA-DGD across various benchmark problems [1]. The success is attributed to the decision tree's ability to act as an effective filter.
The search results indicate that other advanced MFEAs have achieved performance improvements through different transfer strategies. For example, one study reported that a novel adaptive incremental transfer learning approach led to an average improvement of up to 31% over state-of-the-art methods in a different domain (big data workload performance modeling) [62]. Another MFEA based on diffusion gradient descent (MFEA-DGD) demonstrated faster convergence to competitive results by providing theoretical guarantees and explaining the benefits of knowledge transfer through task convexity [63]. These results from related adaptive strategies underscore the potential performance gains that well-designed transfer mechanisms like the decision tree approach can unlock.
Table 2: Summary of Algorithm Performance on Benchmark Problems
| Algorithm | Key Mechanism | Reported Performance | Key Advantage |
|---|---|---|---|
| EMT-ADT [1] | Decision Tree-based individual selection | Highly competitive on CEC2017, WCCI20-MTSO, WCCI20-MaTSO | Explicit prediction and selection of high-transfer-ability individuals |
| MFEA-II [1] | Online learning of RMP matrix | State-of-the-art benchmark for comparison | Captures non-uniform inter-task synergies |
| MFEA-DGD [63] | Diffusion Gradient Descent | Faster convergence, provable convergence | Theoretical guarantees on convergence |
| SA-MFEA [59] | Self-adaptive RMP based on online similarity measurement | Improved efficacy on synthetic and production problems | Boosts positive transfer and curbs negative transfer automatically |
| Group-based MFEA [64] | Task grouping and selective intra-group transfer | Improved performance in cross/intra-domain problems | Reduces negative transfer by restricting transfer to similar tasks |
Implementing and experimenting with a Decision Tree-based MFEA requires a suite of computational tools and resources. The following table details key components.
Table 3: Essential Computational Tools for Algorithm Implementation and Testing
| Tool/Resource | Function | Application in EMT-ADT Research |
|---|---|---|
| Benchmark Suites (CEC2017 MFO, WCCI20-MTSO/MaTSO) | Standardized problem sets | Provides a common ground for fair and reproducible comparison of algorithm performance [1]. |
| SHADE (Success-History based Adaptive DE) | Search engine / optimizer | Serves as a powerful and generic search engine within the MFEA paradigm, demonstrating its flexibility [1]. |
| Gini Index / Information Gain | Node splitting criterion | Used as the core metric within the decision tree algorithm to determine the most informative features for splitting data at each node [1] [61]. |
| Boruta Algorithm | Feature selection wrapper | A robust method for identifying all relevant features in a dataset, which can be used to pre-select the most informative features for the decision tree model [61]. |
| Random Forest / XGBoost | Ensemble learning methods | While a single decision tree is often used for interpretability, ensemble methods like these can potentially create more powerful transfer ability predictors [61] [65]. |
| Gradient Boosting Decision Trees (GBDT) | Advanced tree-based model | A sophisticated boosting algorithm that builds trees sequentially to correct errors, suitable for complex learning tasks like transfer ability regression [65]. |
The integration of decision tree models into Multifactorial Evolutionary Algorithms represents a significant advancement in the pursuit of efficient and robust evolutionary multitasking. By moving beyond a one-size-fits-all transfer parameter (rmp) and introducing an intelligent, predictive model for individual selection, the EMT-ADT framework directly addresses the core challenge of negative knowledge transfer. This approach allows for an online, adaptive selection process where only individuals deemed to be rich sources of useful knowledge are permitted to engage in cross-task crossover.
The experimental results on established benchmarks confirm that this strategy is highly competitive, enabling the algorithm to maintain high solution precision, particularly in complex multitasking environments with low inter-task relatedness. For researchers and practitioners in fields like drug development, where in-silico optimization often involves multiple related but distinct tasks, this methodology offers a principled path to harnessing the latent synergies between tasks, potentially accelerating discovery and improving outcomes. Future work may explore the use of more complex ensemble tree models, deeper integration of the predictor with other adaptive mechanisms, and applications to a wider range of real-world, large-scale multidisciplinary optimization problems.
Within the rapidly evolving field of evolutionary computation, Multifactorial Evolutionary Algorithms (MFEAs) have emerged as a powerful paradigm for solving multiple optimization tasks simultaneously. A core component enabling this concurrent optimization is the random mating probability (rmp) parameter, which crucially controls the transfer of genetic information between tasks. This technical guide delves into the advanced methods for online parameter estimation of the rmp, framing this discussion within the broader thesis that effective knowledge transfer is the cornerstone of successful multifactorial optimization. For researchers and scientists, particularly those in drug development where related optimization tasks are common, mastering these adaptive techniques is essential for developing more robust, efficient, and intelligent evolutionary computing systems.
Foundations of Multifactorial Optimization
Core Principles of MFEAs
Multifactorial Optimization (MFO) represents a shift from traditional evolutionary algorithms by evolving a single unified population of individuals to address multiple optimization tasks, or "factors," at once [66]. Each individual in the population possesses a skill factor, indicating the task on which it performs best. The fundamental hypothesis is that by leveraging potential genetic interdependencies between tasks, the search process can be accelerated, and solution quality improved for some or all of the constituent problems.
- Unified Search Space: MFEAs create a unified representation space encompassing all tasks, allowing for direct comparison and crossover between individuals from different task domains.
- Implicit Genetic Transfer: The primary mechanism for knowledge sharing is through crossover operations between parents from different tasks, governed probabilistically by the random mating probability.
- Assortative Mating: The classic MFEA implements a form of assortative mating where individuals are more likely to mate with others sharing the same skill factor unless the rmp allows for cross-task crossover.
The Central Role of Random Mating Probability (rmp)
The random mating probability (rmp) is a critical control parameter in classical MFEAs, typically set by the user to a fixed value between 0 and 1. It defines the probability that two parents from different tasks will produce an offspring through crossover.
- High rmp (e.g., 0.8-1.0): Promotes extensive genetic transfer between tasks, which can be beneficial if the tasks are related and share useful genetic building blocks.
- Low rmp (e.g., 0.0-0.2): Restricts crossover mostly to within the same task, preventing potentially harmful cross-task transfers, which is safer when tasks are unrelated.
However, the performance of the MFEA is highly sensitive to the rmp value, and its optimal setting is problem-dependent and may even change during the evolutionary process. This limitation of static parameter setting has motivated the development of online estimation methods that dynamically adapt the rmp based on the evolving search.
Online Parameter Estimation Methods
Moving beyond static parameter tuning, online estimation methods adapt the rmp in real-time based on feedback from the optimization process. These methods align with the broader thesis that MFEAs must be self-configuring systems capable of autonomously discovering and exploiting synergies between tasks.
Trait Segregation in M-MFEA
The Mutagenic Multifactorial Evolutionary Algorithm (M-MFEA) introduces a novel approach inspired by biological trait segregation [9]. This method eliminates the need for a manually predefined rmp by allowing the evolutionary process to be naturally guided by the expression of traits (dominant or recessive) in individuals.
Table: Key Components of the Trait Segregation Approach in M-MFEA
| Component | Function | Biological Inspiration |
|---|---|---|
| Trait Expression | Defines whether an individual's traits are dominant or recessive within the unified search space. | Mendelian genetics |
| Mutagenic Genetic Interaction Strategy | Enhances information transfer within and across tasks based on spontaneous trait expressions. | Genetic mutation and recombination |
| Adaptive Mutagenic Gene Inheritance | Drives continuous task convergence by controlling how genetic material is passed to offspring. | Natural selection and heredity |
The workflow of this method can be visualized as follows, illustrating how trait segregation naturally guides mating without a predefined rmp:
Dynamic Resource Allocation in MFEA/D-DRA
The MFEA/D-DRA algorithm incorporates a dynamic resource allocation strategy that implicitly manages cross-task interactions by allocating computational resources based on how quickly subproblems are evolving [66]. While not directly estimating an rmp value, it achieves a similar outcome by controlling the opportunity for genetic transfer.
- Decomposition: Each multiobjective task is decomposed into numerous single-objective subproblems using a set of weight vectors.
- Utility Function: The evolution rate of each subproblem is periodically measured by a utility function.
- Resource Reward: Subproblems demonstrating faster improvement rates are rewarded with more computational resources (e.g., more function evaluations), thereby influencing which individuals and traits are propagated.
Online Transfer Parameter Estimation in MFEA-II
The MFEA-II algorithm explicitly addresses online parameter estimation through a methodology that automatically infers the relationships between tasks and adjusts the degree of genetic transfer accordingly [66]. This represents a direct implementation of online rmp estimation.
- Online Transfer Parameter Estimation: The algorithm automatically estimates the similarity between tasks during the early stages of evolution.
- Adaptive rmp: Based on the estimated inter-task relationships, the rmp matrix is adaptively tuned to promote useful genetic transfers and suppress deleterious ones.
- Data-Driven Convergence: This data-driven approach leads to more robust performance across various multitasking scenarios without requiring extensive pre-tuning.
Table: Comparison of Online Parameter Estimation Methods in MFEAs
| Method | Core Mechanism | Key Advantage | Reported Performance |
|---|---|---|---|
| M-MFEA (Trait Segregation) [9] | Biological trait expression | Eliminates need for manually predefined rmp | Significant competitive advantages in industrial planar kinematic arm control |
| MFEA/D-DRA (Dynamic Resource Allocation) [66] | Utility-based computing resource allocation | Allocates resources according to subproblem difficulty | Superior performance on benchmark MO-MFO problems |
| MFEA-II (Online Transfer Parameter Estimation) [66] | Automatic inference of inter-task relationships | Directly estimates and adapts rmp values | Enhanced robustness across diverse multitasking scenarios |
Experimental Protocols and Validation
Validating the efficacy of online parameter estimation methods requires rigorous experimental protocols using standardized benchmarks and real-world problems.
Benchmark Suites for Performance Evaluation
Researchers typically employ benchmark suites from IEEE Congress on Evolutionary Computation (CEC) competitions to ensure objective comparisons.
- CEC 2014 Benchmark Suite: Used for single-objective numerical optimization validation [67].
- CEC 2017 Benchmark Suite: Provides more challenging test functions for advanced algorithm validation [67].
- Multiobjective Multitasking Benchmark Problems: Custom-designed problems that test both convergence and diversity maintenance in multiobjective MFO scenarios [66].
Industrial Application Validation
Beyond benchmarks, algorithms must be validated on complex real-world problems to demonstrate practical utility.
- Planar Kinematic Arm Control: The M-MFEA was validated on an industrial planar kinematic arm control problem, showing "significant competitive advantages over state-of-the-art methods" [9].
- Continuous Annealing Process Optimization: The MFEA/D-DRA was applied to the multiobjective multifactorial operation optimization of a continuous annealing process based on data analytics, demonstrating superior practical performance [66].
Statistical Validation Methods
Robust experimental protocols employ statistical tests to ensure the significance of performance improvements.
- Wilcoxon Rank-Sum Test: A non-parametric statistical test used to determine if the performance differences between algorithms are statistically significant [68].
- Friedman Rank Test: Used for multiple comparison analysis to rank algorithms across multiple problems or benchmarks [68].
- Repeated Time-Series Cross-Validation (RTS-CV): Particularly important for research cases requiring immediate action and decision-making, such as pandemic forecasting, where traditional data splitting ratios (e.g., 80:20) may be unsuitable [69].
Implementation Guide
The Scientist's Toolkit
Implementing online parameter estimation requires specific computational tools and resources.
Table: Essential Research Reagent Solutions for MFEA Development
| Tool/Resource | Function/Purpose | Application Context |
|---|---|---|
| CEC Benchmark Suites | Standardized test functions for algorithm validation | Performance comparison and benchmarking |
| Jeffreys Divergence (JPTI) [70] | Quantifies information gain from non-random mating patterns | Analyzing and validating mating patterns in populations |
| Repeated Time-Series Cross-Validation (RTS-CV) [69] | Robust model validation technique | Scenarios requiring immediate action and decision-making |
| Statistical Test Suites (Wilcoxon, Friedman) [68] | Determines statistical significance of results | Validating performance improvements in experimental studies |
Workflow for Implementing Online rmp Estimation
A generalized workflow for implementing an online rmp estimation strategy in MFEA research is outlined below, synthesizing elements from the various methods discussed:
This workflow emphasizes the continuous feedback loop where the success of knowledge transfer is constantly monitored and used to refine the rmp parameter, enabling the algorithm to self-adapt to the characteristics of the specific problems being solved.
The development of online parameter estimation methods for random mating probability represents a significant advancement within the broader thesis of multifactorial evolutionary algorithm research. By transitioning from static, user-defined parameters to adaptive, self-configuring systems, MFEAs become more robust, generalizable, and effective at discovering and exploiting synergies between optimization tasks. Methods based on trait segregation, dynamic resource allocation, and explicit online estimation have all demonstrated superior performance compared to traditional approaches across various benchmarks and real-world applications.
Future research directions in this domain include developing more sophisticated similarity measures for inter-task relationships, creating hybrid approaches that combine the strengths of multiple estimation strategies, and extending these concepts to emerging areas such as many-task optimization and expensive multifactorial optimization where function evaluations are computationally prohibitive. Furthermore, the application of these advanced MFEAs to complex problems in drug development, such as multi-target therapeutic design and polypharmacology, presents a promising frontier for both evolutionary computation and pharmaceutical research.
In the domain of evolutionary computation, Multifactorial Evolutionary Algorithms (MFEAs) represent a paradigm shift from traditional single-task optimization by enabling the simultaneous solution of multiple optimization tasks within a single algorithmic framework [71]. This approach, known as Evolutionary Multitasking Optimization (EMTO), mimics the human ability to leverage knowledge across related tasks, where useful information gained while solving one task can potentially accelerate the finding of solutions to another related task [71] [21]. The fundamental insight driving MFEAs is that many real-world optimization scenarios involve multiple interrelated problems whose solutions may share common characteristics or underlying structures.
When these multitasking environments incorporate constraints—conditions that must be satisfied for solutions to be valid—the complexity of optimization increases significantly. Constrained Multi-Objective Optimization Problems (CMOPs) require simultaneously optimizing multiple conflicting objectives while satisfying various constraints [72]. In such problems, constraints typically divide the search space into feasible regions (where all constraints are satisfied) and infeasible regions (where at least one constraint is violated) [72]. The mathematical formulation of a CMOP can be represented as: Find ⃗x which optimizes ⃗F(⃗x) = (f₁(⃗x), f₂(⃗x), …, fₘ(⃗x))ᵀ subject to gᵢ(⃗x) ≤ 0, i = 1, …, n hⱼ(⃗x) = 0, j = 1, …, p where ⃗x = [x₁, x₂, …, x_D]ᵀ ∈ ℝ [72]
Within this framework, feasibility priority rules emerge as crucial mechanisms for guiding the search process toward regions of the solution space that satisfy all constraints while maintaining strong objective performance. These rules help balance the often competing goals of constraint satisfaction and objective optimization, particularly when handling multiple tasks with potentially conflicting constraints [72] [73].
Table 1: Key Terminology in Constrained Multitasking Optimization
| Term | Definition |
|---|---|
| Feasible Solution | A solution that satisfies all constraints [72] |
| Infeasible Solution | A solution that violates at least one constraint [72] |
| Constraint Violation | A measure of how severely a solution violates constraints [72] |
| Skill Factor | The task on which an individual solution performs best [13] |
| Factorial Cost | A combined measure of objective value and constraint violation [21] |
Feasibility Priority Rules: Core Principles and Mechanisms
Feasibility priority rules form the decision-making backbone of constraint handling in evolutionary multitasking environments. These rules establish a hierarchy that guides selection, reproduction, and knowledge transfer processes toward maintaining and improving feasibility across all tasks.
Fundamental Rule: Superiority of Feasible Points
The most fundamental feasibility priority rule states that feasible solutions strictly dominate infeasible solutions, regardless of their objective performance [73]. This principle ensures that the search process prioritizes constraint satisfaction over objective optimization when comparing feasible and infeasible solutions. The implementation of this rule varies across different algorithms, but the core concept remains consistent: when comparing two solutions where one is feasible and the other is infeasible, the feasible solution is always preferred.
This seemingly simple rule has profound implications for population dynamics in MFEAs. By giving selection priority to feasible individuals, the algorithm progressively steers the entire population toward feasible regions of the search space. This approach prevents the wasteful computational effort that might otherwise be expended on refining solutions that violate critical constraints.
Constraint Violation-Based Prioritization
When comparing two infeasible solutions, feasibility priority rules typically employ constraint violation quantification to determine superiority [72]. The total constraint violation for a solution ⃗x is calculated as: CV(⃗x) = Σ cvᵢ(⃗x) where cvᵢ(⃗x) = max(0, gᵢ(⃗x)) for inequality constraints cvᵢ(⃗x) = max(0, |hᵢ(⃗x)| - δ) for equality constraints [72]
Here, δ is a small positive value used to relax the strictness of equality constraints. When both solutions being compared are infeasible, the solution with lower total constraint violation receives priority [72]. This mechanism creates a gradient that guides infeasible solutions toward feasibility, even when no feasible solutions exist in the current population.
Feasibility-Cognizant Skill Factor Assignment
In multifactorial evolutionary environments, each individual solution receives a skill factor identifying the task on which it performs best [13] [21]. Feasibility priority rules extend this concept by incorporating constraint satisfaction into skill factor determination. Specifically, the factorial cost of an individual pᵢ on task Tⱼ is defined as: αᵢⱼ = γ·δᵢⱼ + Fᵢⱼ where δᵢⱼ is the total constraint violation of individual pᵢ on task Tⱼ, Fᵢⱼ is the objective value, and γ is a large penalizing multiplier [21]
This formulation ensures that constraint violation heavily penalizes the factorial cost, making feasible solutions likely to achieve better skill factors than infeasible solutions with superior objective values.
Diagram 1: Feasibility Priority Decision Flow. This diagram illustrates the hierarchical decision process for comparing two solutions under feasibility priority rules.
Implementation in Multifactorial Evolutionary Algorithms
Knowledge Transfer with Feasibility Preservation
A significant challenge in MFEA design is facilitating knowledge transfer between tasks while respecting constraint boundaries. The standard MFEA implements knowledge transfer through assortative mating and vertical cultural transmission [21]. However, these mechanisms must be augmented with feasibility priority rules to prevent the transfer of problematic genetic material that could lead to constraint violations.
Advanced implementations, such as the Mutagenic Multifactorial Evolutionary Algorithm based on Trait Segregation (M-MFEA), introduce specialized mechanisms for feasibility-preserving knowledge transfer [9]. This algorithm employs a mutagenic genetic information interaction strategy based on trait segregation, which naturally guides the exchange of genetic information without manually predefined parameters [9]. The trait expression (dominant or recessive) of individuals in a unified multitasking search space determines how genetic information is transferred, with feasibility acting as a dominant trait that takes precedence in inheritance patterns.
Adaptive Resource Allocation Based on Feasibility
Feasibility priority rules also influence how computational resources are allocated across different tasks and individuals. The Two-Level Transfer Learning Algorithm (TLTLA) introduces an upper-level inter-task transfer learning and a lower-level intra-task transfer learning [21]. This dual approach enables more efficient resource allocation by:
- Using inter-task commonalities and similarities to improve cross-task optimization efficiency
- Transmitting information from one dimension to other dimensions within the same task to accelerate convergence [21]
In this framework, feasibility metrics determine the intensity and direction of knowledge transfer, with higher-feasibility solutions serving as more frequent donors of genetic material.
Table 2: Feasibility Priority Mechanisms in Advanced MFEA Variants
| Algorithm | Feasibility Handling Mechanism | Key Innovation |
|---|---|---|
| MFEA with Node-depth Encoding (NDE-MFEA) [13] | Domain uniqueness constraints encoded in tree representation | Makes solution construction more practical while adhering to domain constraints |
| Mutagenic MFEA (M-MFEA) [9] | Trait segregation guiding genetic exchange | Eliminates need for manually set parameters for evolutionary exchanges |
| Two-Level Transfer Learning Algorithm [21] | Upper-level inter-task and lower-level intra-task learning | Reduces randomness in knowledge transfer through elite individual learning |
| MFEA for Robust Competitive Influence Maximization (MFEA-RCIMMD) [25] | Multi-phase transfer operation considering genetic and fitness domains | Leverages knowledge across different damage scenarios in network problems |
Experimental Protocols and Evaluation Metrics
Benchmarking Constrained Multitasking Problems
Evaluating the performance of feasibility priority rules requires specialized benchmark problems that incorporate multiple tasks with various constraint types. The IDPC-NDU dataset (Inter-Domain Path Computation with Node-Defined Domain Uniqueness Constraint) provides such a benchmark, categorizing problems by size (50-2000 vertices for small instances and ≥2000 vertices for large instances) [13]. These problems require identifying the shortest path between two designated nodes while ensuring each domain is visited no more than once, representing a classic NP-hard constrained multitasking problem [13].
Additional benchmarks include problems from the CMOP benchmark suite, which features different constraint characteristics such as linear, non-linear, equality, and inequality constraints across multiple tasks [72]. These benchmarks enable researchers to evaluate how feasibility priority rules perform across diverse problem types and constraint configurations.
Performance Metrics for Feasibility Handling
The effectiveness of feasibility priority rules is quantified using specific performance metrics:
- Feasibility Ratio: The proportion of feasible solutions in the final population [72]
- Constraint Violation Progression: The rate at which average constraint violation decreases across generations [72]
- Relative Percentage Deviation (RPD): Measures solution quality relative to known optimal solutions or best-found solutions [13]
RPD is calculated as: RPD = (Solution - Best) / Best × 100 [13]
Experimental protocols typically involve multiple independent runs (e.g., 30 runs as in [13]) to ensure statistical significance, with results reported as averages across these runs.
Diagram 2: Experimental Workflow for Evaluating Feasibility Priority Rules. This diagram outlines the standard experimental procedure for assessing constraint handling performance in multitasking environments.
Case Study: Node-Depth Encoding MFEA for Inter-Domain Path Computation
A concrete implementation of feasibility priority rules can be observed in the Node-Depth Encoding MFEA (NDE-MFEA) applied to the Inter-Domain Path Computation problem with Node-defined Domain Uniqueness Constraint (IDPC-NDU) [13]. This case study illustrates how domain-specific constraints can be integrated into the MFEA framework through specialized encoding and feasibility preservation mechanisms.
The IDPC-NDU problem involves finding the shortest path between two nodes in a multi-domain network while ensuring that each domain is visited at most once [13]. The domain uniqueness constraint represents a challenging combinatorial restriction that must be satisfied for solutions to be valid.
NDE-MFEA addresses this challenge through several key innovations:
- Node-Depth Encoding: Solutions are represented using a tree encoding that inherently respects domain constraints, making solution construction more practical [13]
- Domain-Uniqueness Preserving Operators: Evolutionary operators are designed to maintain domain uniqueness throughout the search process
- Implicit Knowledge Transfer: The algorithm leverages the multifactorial optimization framework to transfer knowledge between related path computation tasks [13]
Experimental results demonstrate that NDE-MFEA significantly outperforms existing methods in terms of solution quality, convergence trends, and computational efficiency [13]. The success of this approach underscores the importance of integrating domain-specific constraint handling directly into the representation and operators of the MFEA, rather than treating constraints as external penalties.
Research Reagent Solutions: Essential Components for Experimental Studies
Table 3: Essential Research Components for Constrained Multitasking Experiments
| Component | Function | Examples |
|---|---|---|
| Benchmark Problems | Provide standardized test cases | IDPC-NDU datasets [13], CMOP benchmarks [72] |
| Performance Metrics | Quantify algorithm performance | Feasibility Ratio [72], RPD [13], Convergence Metrics |
| Algorithm Frameworks | Enable algorithm development and comparison | MFEA base code [71], NDE extensions [13] |
| Visualization Tools | Illustrate algorithm behavior and results | Pareto front plots [72], Convergence graphs [13] |
| Statistical Analysis Packages | Ensure result significance | Statistical test suites (e.g., for comparing multiple algorithms) [13] |
Feasibility priority rules represent a crucial component of effective constraint handling in multifactorial evolutionary algorithms. By establishing a clear hierarchy that prioritizes constraint satisfaction while maintaining selection pressure toward optimal solutions, these rules enable MFEAs to navigate complex constrained search spaces across multiple simultaneous tasks.
The continuing evolution of MFEA frameworks—from the basic MFEA to sophisticated variants like M-MFEA and NDE-MFEA—demonstrates the importance of tailoring feasibility handling mechanisms to specific problem characteristics [13] [9]. As multifactorial optimization approaches continue to mature, several promising research directions emerge:
- Dynamic Feasibility Rules: Adaptive mechanisms that adjust feasibility prioritization based on search progress and problem characteristics
- Transfer Learning for Feasibility: Explicit learning of feasibility patterns across tasks to accelerate constraint satisfaction
- High-Dimensional Constraint Handling: Scalable approaches for problems with large numbers of constraints and decision variables
- Theoretical Foundations: Formal analysis of convergence properties for MFEAs with feasibility priority rules
As these research directions are pursued, feasibility priority rules will continue to play a fundamental role in enabling multifactorial evolutionary algorithms to solve increasingly complex constrained optimization problems across diverse application domains.
Domain adaptation (DA) has emerged as a critical technique in machine learning and evolutionary computation for addressing the challenge of distribution shifts between training (source) and test (target) domains. Within multifactorial evolutionary algorithm (MFEA) research, DA plays a pivotal role in enabling effective knowledge transfer across optimization tasks by aligning their search spaces [74]. MFEAs are designed to solve multiple optimization tasks simultaneously by leveraging implicit genetic transfer between tasks, with DA techniques helping to align disparate search spaces to facilitate this knowledge exchange [74] [13].
This technical guide focuses on two fundamental approaches to domain adaptation in evolutionary multitasking: affine transformation, which applies linear transformations to align feature representations, and search space alignment, which directly modifies the optimization landscape to enable more effective knowledge transfer. These techniques are particularly valuable in complex real-world applications such as drug development and industrial optimization, where multiple related problems must be solved concurrently despite differences in their problem characteristics [74] [9].
Domain Adaptation in Multifactorial Evolutionary Computation
Evolutionary Multi-Task Optimization (EMTO) Framework
Evolutionary multi-task optimization (EMTO) represents a paradigm shift in evolutionary computation, enabling the simultaneous solution of multiple optimization tasks through knowledge transfer [74]. The fundamental advantage of EMTO lies in its ability to use shared knowledge across different tasks to boost optimization performance, making it particularly valuable for complex real-world problems in domains such as production scheduling, energy management, and evolutionary machine learning [74].
MFEA implementations generally follow two main frameworks:
- Multi-factorial framework: Utilizes a unified population for all tasks, enabling implicit genetic information exchange [74]
- Multi-population framework: Maintains separate populations for each task, enabling explicit collaboration through structured knowledge transfer mechanisms [74]
The effectiveness of both frameworks depends heavily on proper domain alignment to prevent negative transfer—where inappropriate knowledge exchange degrades performance—while promoting positive transfer that accelerates convergence and improves solution quality [74] [13].
The Role of Domain Adaptation in EMTO
Domain adaptation techniques in EMTO primarily address the challenge of distribution mismatch between tasks, which can manifest as differences in search space characteristics, objective function landscapes, or constraint structures [74]. When tasks exhibit significant dissimilarity, direct knowledge transfer becomes challenging and can lead to performance degradation without proper alignment mechanisms [74].
Advanced DA approaches in EMTO have evolved beyond static pre-training or periodic re-matching mechanisms toward continuous adaptation throughout the evolutionary process [74]. This progression recognizes that populations dynamically change during optimization, requiring adaptation techniques that can evolve alongside the search process to maintain effective alignment between domains.
Table 1: Domain Adaptation Challenges in Evolutionary Multi-Task Optimization
| Challenge | Impact on EMTO | Common Solutions |
|---|---|---|
| Distribution Shift | Prevents effective knowledge transfer between tasks | Affine transformations, moment matching |
| Search Space Misalignment | Limits applicability of transferred solutions | Progressive auto-encoding, space unification |
| Negative Transfer | Degrades optimization performance | Transfer adaptation, knowledge screening |
| Dynamic Populations | Reduces alignment effectiveness over time | Continuous adaptation, online learning |
Affine Transformation Techniques
Geometric Moment Alignment
Geometric moment alignment represents an advanced approach that leverages the intrinsic geometry of probability distributions for domain adaptation. Unlike traditional methods that use ad-hoc Euclidean distances, this technique employs Riemannian geometry to better capture the structural relationships between domains [75]. The key innovation lies in expressing first- and second-order moments as a single symmetric positive definite (SPD) matrix through Siegel embeddings, enabling simultaneous adaptation of both moments using the natural geometric distance on the shared manifold of SPD matrices [75].
The mathematical foundation of this approach preserves the mean and covariance structure of source and target distributions, yielding a more faithful metric for cross-domain comparison. By mapping latent representations of both domains using a diffeomorphic transformation into the SPD manifold, the method captures the first two moments into a single SPD matrix, then exploits the Riemannian structure to measure distances using geometrically inspired metrics such as Affine-Invariant Riemannian and Hilbert projective distance [75]. This approach has demonstrated effectiveness in both supervised tasks (e.g., classification) and unsupervised tasks (e.g., denoising) under covariate shift conditions [75].
Moment Matching Methodologies
Traditional moment matching techniques in domain adaptation have primarily focused on aligning low-order statistical moments between source and target distributions:
- First-order moment alignment: Early methods minimized discrepancy in first-order statistics using maximum mean discrepancy (MMD) with extensions exploring class-aware or joint variants [75]
- Second-order moment alignment: Improved alignment through matching covariance using linear (CORAL) or non-linear transformations, with extensions accounting for feature discriminability [75] [76]
- Higher-order moments: Some approaches have considered higher-order moments or cumulants to capture richer dependencies between domains [75]
A significant limitation of these conventional approaches is their reliance on heuristic similarity measures, most commonly Euclidean distance, which fails to capture the true geometric relationships between probability distributions [75]. The incorporation of Riemannian geometric principles addresses this limitation by providing a principled framework for measuring distribution discrepancies that respect the underlying manifold structure.
Table 2: Affine Transformation Techniques for Domain Adaptation
| Technique | Mathematical Foundation | Alignment Strategy |
|---|---|---|
| Geometric Moment Alignment | Siegel embeddings, SPD manifolds | Riemannian distance on moment matrices |
| Maximum Mean Discrepancy (MMD) | Reproducing Kernel Hilbert Space | Mean feature distribution matching |
| CORAL | Linear transformation | Second-order statistic alignment |
| Deep CORAL | Deep neural networks | Non-linear covariance matching |
Experimental Protocol for Geometric Moment Alignment
Implementation Framework: The geometric moment alignment protocol involves these key steps:
- Feature Extraction: Process source and target domain data through a shared feature encoder ( e_{\theta} ) to obtain latent representations [75]
- Moment Calculation: Compute first-order (mean) and second-order (covariance) moments for both domains in the latent space
- Siegel Embedding: Transform the calculated moments into SPD matrices using the diffeomorphic transformation ( \phi: \mathbb{R}^d \times \mathbb{R}^{d\times d} \rightarrow \mathcal{S}_{++}^{d+1} ) [75]
- Distance Computation: Calculate the Hilbert projective distance between source and target SPD matrices
- Optimization: Minimize the Riemannian distance with respect to encoder parameters using gradient-based optimization
Key Mathematical Formulations: The Siegel embedding function combines first and second-order moments: [ \phi(\mu, \Sigma) = \begin{bmatrix} \Sigma + \mu\mu^T & \mu \ \mu^T & 1 \end{bmatrix} ] where ( \mu ) represents the mean vector and ( \Sigma ) the covariance matrix.
The Hilbert projective distance between two SPD matrices ( P ) and ( Q ) is computed as: [ d_H(P, Q) = \|\log(\lambda(P^{-1}Q))\|_\infty ] where ( \lambda(\cdot) ) denotes the eigenvalues of the matrix [75].
Search Space Alignment Methods
Progressive Auto-Encoding (PAE)
Progressive auto-encoding represents a significant advancement in domain adaptation for evolutionary multi-task optimization by enabling continuous domain adaptation throughout the evolutionary process [74]. Unlike static pre-trained models or periodic re-matching mechanisms, PAE dynamically updates domain representations to accommodate the changing nature of evolving populations [74].
The PAE framework incorporates two complementary adaptation strategies:
- Segmented PAE: Employs staged training of auto-encoders to achieve effective domain alignment across different optimization phases, providing structured adaptation aligned with evolutionary progress [74]
- Smooth PAE: Utilizes eliminated solutions from the evolutionary process to facilitate more gradual and refined domain adaptation, enabling continuous refinement of domain representations [74]
When integrated into both single-objective and multi-objective multi-task evolutionary algorithms (as MTEA-PAE and MO-MTEA-PAE respectively), this approach has demonstrated superior performance across six benchmark suites and five real-world applications, validating its effectiveness in enhancing domain adaptation capabilities within EMTO [74].
Node-Depth Encoding for Complex Constraints
Node-depth encoding (NDE) provides an effective solution for search space alignment in problems with complex structural constraints, such as the Inter-Domain Path Computation problem with Node-defined Domain Uniqueness Constraint (IDPC-NDU) [13]. This approach represents solutions using tree representations that inherently adhere to domain constraints, making solution construction more practical for problems with complex feasibility requirements [13].
The NDE-MFEA algorithm leverages implicit knowledge transfer in multifactorial optimization to improve exploitation ability in promising solution spaces [13]. By developing specialized evolutionary operators for applying node-depth encoding to directed graph problems, this approach significantly outperforms existing methods in terms of solution quality, convergence trends, and computational efficiency for constrained optimization problems [13].
Experimental Protocol for Progressive Auto-Encoding
Implementation Framework: The progressive auto-encoding methodology involves these key components:
- Architecture Setup: Initialize auto-encoder networks for each task with tied encoder-decoder weights [74]
- Segmented Training: Divide the evolutionary process into distinct phases, with auto-encoder retraining triggered at phase boundaries [74]
- Smooth Adaptation: Incorporate eliminated solutions from environmental selection into the training dataset for continuous model refinement [74]
- Knowledge Transfer: Use the aligned latent representations to facilitate cross-task solution transfer through specialized genetic operators
- Convergence Monitoring: Track population diversity and convergence metrics to guide adaptation scheduling
Integration with MFEA: The PAE technique integrates with multifactorial evolutionary algorithms through these modifications:
- Encoded Solution Representation: Solutions are represented in a unified latent space learned by the auto-encoders [74]
- Transferable Crossover: Genetic operators leverage the aligned representations to enable meaningful cross-task solution recombination [74]
- Dynamic Adaptation: The adaptation mechanism continuously refines domain alignment based on both active and eliminated solutions [74]
Comparative Analysis and Performance Metrics
Quantitative Performance Evaluation
Domain adaptation techniques in evolutionary multi-task optimization have been extensively evaluated across diverse benchmark problems and real-world applications. The progressive auto-encoding (PAE) approach has demonstrated significant competitive advantages over state-of-the-art algorithms, establishing a novel paradigm for collaboratively solving multitasking optimization problems in complex industrial scenarios [74] [9].
In remote sensing image classification, domain adaptation methods incorporating optimized loss functions and self-attention mechanisms have shown substantial improvements in handling domain shifts caused by variations in sensor characteristics, geographical regions, or atmospheric conditions [76]. These approaches systematically combine primary losses (center and triplet losses), secondary losses (MMD, CORAL, and entropy), and attention mechanisms within a unified framework to achieve more robust adaptation performance [76].
Table 3: Performance Comparison of Domain Adaptation Techniques
| Method | Application Domain | Key Metrics | Performance Advantage |
|---|---|---|---|
| MTEA-PAE | Multi-task optimization | Convergence efficiency, Solution quality | Outperforms state-of-the-art algorithms on benchmarks and real-world applications [74] |
| NDE-MFEA | Inter-domain path computation | Solution quality, Computational efficiency | Significant outperformance over competitive algorithms [13] |
| Geometric Moment Alignment | Image classification, Denoising | Target domain accuracy | Superior to heuristic moment matching approaches [75] |
| Optimized Loss with Self-Attention | Remote sensing classification | Adaptation accuracy, Robustness | Effectively reduces domain gap across multiple datasets [76] |
The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential Computational Resources for Domain Adaptation Research
| Research Reagent | Function | Implementation Examples |
|---|---|---|
| Benchmark Suites | Algorithm validation and comparison | MToP benchmarking platform for EMTO [74], IDPC-NDU datasets [13] |
| Domain Adaptation Metrics | Quantitative performance assessment | RPD (Relative Percentage Deviation) [13], Target domain accuracy [75] |
| Auto-encoder Architectures | Latent space learning and alignment | Segmented PAE, Smooth PAE for continuous adaptation [74] |
| Riemannian Optimization Frameworks | Geometric moment alignment | SPD manifold optimization, Siegel embeddings [75] |
| Loss Function Combinations | Multi-objective alignment optimization | Triplet + MMD + CORAL + entropy losses [76] |
Visualization of Methodologies
Workflow of Progressive Auto-Encoding in EMTO
Progressive Auto-Encoding Workflow in EMTO
Geometric Moment Alignment via Siegel Embeddings
Geometric Moment Alignment Framework
Domain adaptation through affine transformation and search space alignment represents a critical enabling technology for advancing multifactorial evolutionary algorithm research. The techniques discussed in this guide—from progressive auto-encoding and node-depth encoding to geometric moment alignment—provide powerful mechanisms for addressing the fundamental challenge of distribution shift in multi-task optimization.
As MFEA applications expand into increasingly complex domains such as drug development, industrial optimization, and aerospace engineering, the continued refinement of these domain adaptation approaches will be essential for achieving robust knowledge transfer across related but distinct optimization tasks. Future research directions likely include the development of more sophisticated geometric alignment techniques, automated adaptation scheduling, and integration with emerging foundation models to further enhance the capabilities of evolutionary multi-task optimization systems.
Multifactorial Evolutionary Algorithm (MFEA) research represents a paradigm shift in evolutionary computation, moving from solving optimization problems in isolation to addressing multiple tasks simultaneously within a single algorithmic run [77] [78]. This emerging paradigm, known as Evolutionary Multitasking Optimization (EMTO), leverages the implicit parallelism of population-based search to exploit synergies between related tasks. The fundamental premise is that concurrently solving multiple optimization problems can yield performance improvements over independent optimization through the transfer of valuable knowledge across tasks [1]. This knowledge transfer mechanism is the cornerstone of MFEA, enabling cultural effects through assortative mating and vertical cultural transmission that mimics human evolutionary processes [1].
The efficacy of MFEA critically depends on the design of its knowledge transfer mechanisms, which can be broadly categorized into individual-level and population-level strategies [1]. At the individual level, transfer mechanisms focus on evaluating and selecting promising candidate solutions for cross-task knowledge exchange, often employing machine learning techniques to predict transfer potential [1] [79]. Population-level strategies, conversely, operate at a higher abstraction, managing resource allocation, task similarity learning, and evolutionary trajectory coordination across entire populations [77] [80]. The growing sophistication of these mechanisms represents a key research direction within the field, with applications spanning drug development, supply chain optimization, and complex engineering design [81] [1].
Individual-Level Knowledge Transfer Strategies
Individual-level knowledge transfer mechanisms focus on the evaluation, selection, and transformation of specific candidate solutions for cross-task exchange. These strategies aim to identify individuals with high transfer potential while mitigating the risk of negative transfer—where inappropriate knowledge exchange deteriorates optimization performance [78].
Transfer Ability Quantification and Prediction
A fundamental challenge in individual-level transfer is quantifying the "transfer ability" of candidate solutions—the amount of useful knowledge an individual contains for other tasks. The Evolutionary Multitasking optimization algorithm with Adaptive Transfer strategy based on the Decision Tree (EMT-ADT) defines transfer ability through factorial cost and factorial rank evaluations [1]. For an individual ( p_i ) in a multitasking environment with ( n ) tasks:
- The factorial cost ( \Psij^i ) represents the objective value of individual ( pi ) on task ( T_j ) [1].
- The factorial rank ( rj^i ) denotes the index of ( pi ) when the population is sorted ascendingly according to ( \Psi_j ) [1].
- The skill factor ( \taui = \text{argmin}{j \in {1,\dots,n}} { rj^i } ) indicates the task on which individual ( pi ) performs best [1].
EMT-ADT employs a decision tree model, constructed using the Gini impurity measure, to predict the transfer ability of individuals before actual transfer occurs [1]. This supervised learning approach uses historical transfer success/failure data as training samples, with features derived from individual solution characteristics and inter-task relationships.
Classifier-Assisted Individual Selection
For expensive multitasking problems where fitness evaluations are computationally costly, classifier-assisted approaches provide an alternative to regression surrogates. The Classifier-Assisted Multitasking Optimization (CA-MTO) algorithm employs Support Vector Classifiers (SVC) to distinguish the relative merits of candidate solutions without predicting exact fitness values [79]. This approach implicitly reflects evolutionary direction while reducing model construction difficulty, enhancing algorithm robustness and scalability under limited computational resources [79].
The knowledge transfer strategy in CA-MTO enriches training samples for each task-oriented classifier by sharing high-quality solutions among different tasks, utilizing Principal Component Analysis (PCA)-based subspace alignment to transform and aggregate labeled samples across tasks [79]. This domain adaptation technique mitigates data sparseness issues common in expensive optimization problems.
Table 1: Individual-Level Knowledge Transfer Mechanisms
| Mechanism | Key Methodology | Advantages | Limitations |
|---|---|---|---|
| Decision Tree Prediction (EMT-ADT) | Uses Gini coefficient-based decision tree to predict individual transfer ability | Reduces negative transfer; Improves solution precision | Requires sufficient historical data for tree construction |
| Classifier Assistance (CA-MTO) | Employs SVC with PCA-based subspace alignment | Handles expensive problems; Robust to data sparseness | Increased complexity for simple problems |
| Affine Transformation (AT-MFEA) | Applies rank loss function to learn inter-task mapping | Bridges different problem domains; Enhances transferability | Computationally intensive for high dimensions |
| Linearized Domain Adaptation (LDA-MFEA) | Transforms search space to improve inter-task correlation | Effective for heterogeneous tasks; Provides transfer platform | May oversimplify complex task relationships |
Experimental Protocol for Individual-Level Transfer Evaluation
To evaluate individual-level transfer strategies, researchers employ standardized benchmark problems and performance metrics. The experimental protocol typically includes:
- Benchmark Selection: Utilizing CEC2017 MFO benchmark problems, WCCI20-MTSO, and WCCI20-MaTSO test suites containing tasks with varying degrees of relatedness [1].
- Algorithm Configuration: Implementing MFEA with random mating probability (rmp) as the baseline, compared against specialized transfer mechanisms.
- Performance Metrics: Measuring solution precision (best/mean objective values), convergence speed (number of generations to threshold), and success rate of positive transfers [1].
- Statistical Validation: Applying Wilcoxon signed-rank tests with significance level ( p < 0.05 ) to confirm performance differences [1].
For the EMT-ADT algorithm, the decision tree is trained using features including individual factorial ranks, objective function landscape characteristics, and inter-task similarity estimates. The target variable is binary, indicating whether a transfer operation would produce an offspring that dominates its parent [1].
Population-Level Knowledge Transfer Strategies
Population-level knowledge transfer strategies operate at a higher abstraction, managing the flow of information between entire task populations rather than individual solutions. These mechanisms coordinate evolutionary trajectories, allocate computational resources, and learn inter-task relationships across the optimization process.
Multi-Role Reinforcement Learning System
The MetaMTO framework introduces a sophisticated population-level transfer approach through a multi-role Reinforcement Learning (RL) system that simultaneously addresses three fundamental questions of knowledge transfer: where to transfer, what to transfer, and how to transfer [77]. This system deploys three specialized agent types:
- Task Routing (TR) Agent: Processes status features from all sub-tasks using an attention-based architecture to compute pairwise similarity scores, determining optimal source-target transfer pairs [77].
- Knowledge Control (KC) Agent: For each source-target pair identified by the TR agent, the KC agent determines the quantity of knowledge to transfer by selecting the proportion of elite solutions from the source task's population [77].
- Transfer Strategy Adaptation (TSA) Agent Group: Controls transfer strength by dynamically adjusting hyper-parameters in the underlying EMT framework for each source-target pair [77].
This multi-role system is pre-trained end-to-end over an augmented multitask problem distribution, producing a generalizable meta-policy that achieves state-of-the-art performance against representative baselines [77].
Bidirectional Coevolutionary Frameworks
The Knowledge Transfer-based Constrained Multiobjective Optimization (KTCMO) algorithm exemplifies population-level transfer through a bidirectional coevolutionary framework [80]. This approach derives the original constrained multiobjective optimization problem into two complementary problems:
- Dynamic Selection Preference (DSP) Problem: Gradually switches search priority from objective optimization to constraint satisfaction, achieving global search from unconstrained Pareto front to feasible regions [80].
- Constraint Relaxation (CR) Problem: Progressively reduces constraint boundaries, enabling local search from relaxed feasible regions toward original feasible regions [80].
The knowledge transfer strategy in KTCMO implements two distinct mechanisms. Offspring knowledge transfer facilitates complementation for unexplored search regions through cooperation between populations, enhancing diversity and assisting escape from local optima [80]. Elite-driven knowledge transfer introduces feasible individuals with superior objective function values from the CR parent population into the DSP population, guiding convergence toward optimal feasible regions [80].
Table 2: Population-Level Knowledge Transfer Mechanisms
| Mechanism | Key Methodology | Advantages | Limitations |
|---|---|---|---|
| Multi-Role RL (MetaMTO) | Three specialized agents control transfer routing, content, and strategy | Comprehensive transfer control; State-of-the-art performance | Complex training process; Computational overhead |
| Bidirectional Coevolution (KTCMO) | Derives CMOP into DSP and CR problems with knowledge exchange | Handles disconnected Pareto fronts; Maintains diversity | Specialized for constrained problems |
| Self-Regulated Transfer (SREMTO) | Creates task groups based on ability vectors; transfer through overlap | Adapts to task relatedness; Dynamic transfer intensity | May underutilize weak relationships |
| Explicit Multipopulation (MPEF) | Adjusts rmp based on population evolution status | Improves transfer effects; Online parameter adaptation | Reactive rather than predictive |
Experimental Protocol for Population-Level Transfer Evaluation
Evaluating population-level transfer strategies requires specialized experimental designs that measure both optimization performance and transfer effectiveness:
- Test Problem Design: Employing constrained multiobjective optimization problems (CMOPs) with disconnected Pareto fronts, such as the CF benchmark suite with 56 functions featuring complex constraints and discrete PFs [80].
- Performance Indicators: Utilizing Inverted Generational Distance (IGD) and Hypervolume (HV) metrics to assess convergence and diversity [80].
- Comparative Baselines: Benchmarking against 11 state-of-the-art algorithms, including IMTCMO, CMOEA-CD, and CMOEMT [80].
- Ablation Studies: Isolating components like coevolutionary mechanisms, knowledge transfer strategies, and differential evolution parameters to quantify individual contributions [80].
For KTCMO, experiments on CF benchmarks demonstrate superior performance, particularly for problems with large infeasible regions and discrete PFs, highlighting the effectiveness of its bidirectional knowledge transfer strategy [80].
Integration in Drug Development Applications
Multi-knowledge transfer mechanisms find particularly valuable applications in drug development, where multiple prediction tasks share underlying biological principles yet suffer from data scarcity. The Multi-task Graph Prompt (MGPT) learning framework addresses few-shot drug association prediction by constructing a heterogeneous graph where nodes represent concatenated entity pairs (e.g., drug-protein, drug-disease) [81].
MGPT employs self-supervised contrastive learning to pre-train graph nodes based on structural and semantic similarities [81]. For downstream tasks, it utilizes learnable prompt vectors that incorporate pre-trained knowledge to semantically represent tasks, enabling effective knowledge transfer across drug-target interaction prediction, drug side effect association, and drug-disease relationship inference [81]. Experimental results show MGPT outperforming the strongest baseline (GraphControl) by over 8% in average accuracy under few-shot conditions [81].
Table 3: Performance Comparison on Drug Association Tasks (Accuracy %)
| Method | Drug-Target Interaction | Drug-Side Effect | Drug-Disease | Average |
|---|---|---|---|---|
| MGPT | 92.3 | 88.7 | 85.4 | 88.8 |
| GraphControl | 84.1 | 82.5 | 79.2 | 82.0 |
| GCN | 79.8 | 76.3 | 74.1 | 76.7 |
| GAT | 81.2 | 77.9 | 75.6 | 78.2 |
| GraphSAGE | 78.5 | 75.2 | 72.8 | 75.5 |
Visualizing Knowledge Transfer Workflows
The following diagrams illustrate key workflows and architectural components of multi-knowledge transfer mechanisms, created using Graphviz DOT language with adherence to specified color contrast and palette requirements.
Individual-Level Transfer Evaluation Workflow
Population-Level Multi-Role RL Architecture
Bidirectional Coevolutionary Framework
Table 4: Essential Research Reagents for Multi-Knowledge Transfer Experiments
| Research Reagent | Function/Purpose | Example Implementation |
|---|---|---|
| CEC2017 MFO Benchmark | Standardized test problems for algorithm validation | 12 multifactorial optimization problems with varying inter-task relatedness [1] |
| WCCI20-MTSO/MaTSO | Benchmark suites for multitasking single-objective and many-task single-objective optimization | Composition of multiple optimization tasks with known properties [1] |
| CF Test Suite | Constrained multiobjective optimization problems with disconnected Pareto fronts | 56 benchmark functions featuring complex constraints and discrete PFs [80] |
| Drug Association Datasets | Real-world biological data for validation in practical applications | Fdataset, Cdataset, Ydataset for drug-target, drug-disease predictions [81] [82] |
| Decision Tree Framework | Supervised learning for transfer ability prediction | Gini coefficient-based splitting with historical transfer success data [1] |
| Support Vector Classifier | Classification surrogate for expensive optimization problems | PCA-based subspace alignment for cross-task sample enrichment [79] |
| Attention Mechanism | Similarity recognition for task routing | Compute pairwise task similarity scores in MetaMTO [77] |
| Domain Adaptation Techniques | Enhance transfer between heterogeneous tasks | Linear transformation (LDA), autoencoders, affine transformations [1] [79] |
Multi-knowledge transfer mechanisms represent a significant advancement within multifactorial evolutionary algorithm research, providing sophisticated methodologies for leveraging synergies across concurrent optimization tasks. Individual-level strategies, exemplified by decision tree prediction and classifier-assisted selection, focus on evaluating and selecting promising candidate solutions for cross-task exchange. Population-level approaches, including multi-role reinforcement learning systems and bidirectional coevolutionary frameworks, coordinate evolutionary trajectories and resource allocation across entire task populations.
The integration of these mechanisms in drug development applications demonstrates their practical utility in addressing data scarcity challenges through effective knowledge transfer. As MFEA research continues to evolve, the refinement of multi-knowledge transfer mechanisms will likely focus on adaptive learning of inter-task relationships, automated transfer policy generation, and specialized applications in computationally expensive domains. These advancements hold particular promise for biomedical research, where multiple related prediction tasks share underlying biological principles yet suffer from limited labeled data.
Within the burgeoning field of evolutionary computation, Multifactorial Optimization (MFO) has emerged as a powerful paradigm for solving multiple optimization tasks simultaneously [23]. This approach, often operationalized through Multifactorial Evolutionary Algorithms (MFEAs), exploits the implicit parallelism of populations to facilitate knowledge transfer between related tasks, potentially accelerating convergence and improving solution quality for complex problems [23]. However, a significant challenge arises when these optimization tasks are subject to real-world limitations, giving rise to Constrained Multitasking Optimization Problems (CMTOPs). Traditional evolutionary algorithms often struggle with constraints, typically discarding infeasible solutions—solutions that violate one or more constraints—despite the valuable information they may contain about the problem landscape. This article explores cutting-edge archive-based approaches within multifactorial evolutionary algorithms that strategically preserve and utilize high-quality infeasible solutions to enhance convergence performance and facilitate more effective knowledge transfer across tasks.
The Challenge of Constrained Multitasking Optimization
In practical applications, from drug development to industrial design, optimization problems rarely exist without constraints. These constraints can include physical limitations, resource budgets, or safety requirements, making Constrained Multitasking Optimization a critical area of research [23]. Traditional constraint-handling techniques in evolutionary computation, such as the feasibility priority rule (also known as the feasibility-first rule), prioritize feasible solutions over infeasible ones. While effective for quickly locating feasible regions, this method can cause populations to converge to local optima, particularly when feasible regions are discontinuous or multiple isolated feasible regions exist [23].
The fundamental challenge in CMTOPs lies in balancing two competing objectives: (1) satisfying all problem constraints, and (2) optimizing the objective function(s). Within the MFO context, an additional layer of complexity is added by the need to manage knowledge transfer between tasks, where solutions from one task can inform the search process in another. When this transfer involves constrained problems, the potential for negative transfer—where information exchange hinders rather than helps convergence—increases substantially. This necessitates sophisticated mechanisms that not only handle constraints effectively but also curate the information shared between tasks.
Archive-Based Mechanisms for Exploiting Infeasible Solutions
Core Archiving Strategy
The adaptive archive-based multifactorial evolutionary algorithm (A-CMFEA) introduces a sophisticated archiving strategy designed to harness the potential of infeasible solutions [23]. This approach operates on the principle that some infeasible solutions may possess excellent objective function values and reside near feasible regions, making them valuable for guiding the search process. The archiving mechanism works as follows:
- Selection for Archiving: During population evolution, the objective function values of offspring are compared with those of their parents. If offspring demonstrate superior objective function values but remain infeasible, they are candidates for archiving [23].
- Information Exploitation: The archived infeasible solutions are not merely stored but actively utilized in subsequent generations. By maintaining these solutions, the algorithm preserves genetic material that can help the population traverse infeasible regions to reach promising feasible areas [23].
- Convergence Promotion: The strategic use of archived solutions provides a mechanism for preserving building blocks (high-quality genetic material) that might otherwise be lost through strict feasibility-based selection, thereby promoting faster convergence to high-quality feasible regions.
This archiving strategy represents a significant departure from conventional approaches that discard all infeasible solutions, recognizing that the path to optimal feasible solutions may sometimes travel through infeasible regions of the search space.
Synergistic Algorithmic Components
The archive-based approach does not operate in isolation but functions as part of an integrated system with other adaptive mechanisms:
- Adaptive Random Mating Probability: The A-CMFEA incorporates an adaptive strategy that dynamically adjusts the random mating probability (rmp), a key parameter controlling knowledge transfer between tasks. This adjustment is based on comparing the success rates of individuals generated through cross-task knowledge transfer versus those generated within the same task. By promoting positive knowledge transfer and mitigating negative transfer, this adaptive mechanism enhances the overall efficacy of the multitasking environment [23].
- Mutation with Replacement: A novel mutation strategy further promotes convergence by targeting the most challenging individuals in the population. At each iteration's conclusion, the algorithm identifies the individual with the largest constraint violation and replaces it with a mutant individual generated by mutating a random population member. This replacement occurs only if the mutant individual demonstrates a better objective function value, ensuring progressive improvement while addressing constraint violations [23].
Table 1: Core Components of the Archive-Based MFEA and Their Functions
| Component | Primary Function | Mechanism of Action |
|---|---|---|
| Archiving Strategy | Preserve valuable genetic material | Stores infeasible solutions with superior objective function values for future exploitation |
| Adaptive RMP | Optimize knowledge transfer | Dynamically adjusts cross-task mating probability based on transfer success rates |
| Mutation with Replacement | Escape local optima | Replaces high-constraint-violation individuals with better-performing mutants |
Experimental Framework and Performance Evaluation
Experimental Design and Benchmarking
The performance of archive-based approaches is typically validated through extensive numerical experiments using established benchmark suites for constrained multitasking optimization [23]. The standard experimental protocol involves:
- Algorithm Implementation: Implementing the A-CMFEA by incorporating the feasibility priority rule into an existing MFEA framework (e.g., AT-MFEA) and enhancing it with the three core strategies: archiving, adaptive rmp adjustment, and mutation with replacement [23].
- Comparative Analysis: Comparing performance against both constrained multitasking evolutionary algorithms and advanced constrained single-task evolutionary algorithms to evaluate both multitasking efficacy and constraint-handling capability [23].
- Performance Metrics: Employing appropriate quantitative metrics to evaluate algorithm performance, including convergence speed, solution quality, and feasibility rates.
Quantitative Performance Analysis
Experimental results demonstrate the superiority of archive-based approaches over alternative methods. The A-CMFEA has shown significant performance improvements across various constrained multitasking scenarios, confirming the value of leveraging infeasible solutions through archiving mechanisms [23].
Table 2: Comparative Performance of Constrained Optimization Algorithms
| Algorithm Type | Example Algorithms | Key Strengths | Limitations in CMTOPs |
|---|---|---|---|
| Archive-Based MFEA | A-CMFEA | Exploits infeasible solutions; Adaptive knowledge transfer; Promotes convergence through targeted mutation | Increased computational complexity due to archiving |
| Constrained Single-Task EA | FP-GA (Feasibility Priority Genetic Algorithm) | Effective for single constrained tasks | No knowledge transfer between tasks; Misses synergies in multitasking environments |
| Basic Constrained MFEA | FP-MFEA, FP-AT-MFEA | Enables knowledge transfer between constrained tasks | May discard valuable infeasible solutions; Limited adaptive mechanisms |
The quantitative analyses reveal that the archiving strategy specifically contributes to accelerated convergence rates by preserving genetic diversity and maintaining promising search directions that might otherwise be abandoned in strictly feasibility-based approaches [23].
Implementation Considerations for Research and Development
Research Reagent Solutions and Computational Tools
Implementing archive-based MFEAs requires both theoretical understanding and appropriate computational tools. The following table outlines essential components for experimental implementation:
Table 3: Essential Research Reagents and Computational Tools for Algorithm Implementation
| Tool/Category | Specific Examples | Function in Algorithm Implementation |
|---|---|---|
| Programming Languages | Python, R, C++ | Provides the computational environment for algorithm coding and execution |
| Statistical Analysis Tools | SPSS, R Programming | Enables advanced statistical modeling and analysis of experimental results |
| Data Visualization Platforms | ChartExpo, Microsoft Excel | Facilitates creation of charts and graphs for interpreting complex result datasets |
| Optimization Toolkits | XLMiner ToolPak (Google Sheets), Analysis ToolPak (Microsoft Excel) | Offers statistical functions for preliminary testing and hypothesis validation |
Workflow and System Architecture
The overall workflow of an archive-based MFEA can be visualized through the following logical diagram, which illustrates the key processes and their relationships:
Diagram 1: Workflow of Archive-Based MFEA
Knowledge Transfer Mechanism
The adaptive knowledge transfer process, a critical component of effective multitasking optimization, operates through a carefully designed mechanism for managing solution exchange between tasks:
Diagram 2: Adaptive Knowledge Transfer Process
Archive-based approaches represent a significant advancement in multifactorial evolutionary algorithm research, particularly for addressing the challenges of constrained multitasking optimization. By strategically preserving and exploiting high-quality infeasible solutions through intelligent archiving mechanisms, these algorithms demonstrate improved convergence performance and more effective knowledge transfer between related tasks. The synergistic combination of archiving strategies with adaptive mating probability adjustment and targeted mutation operators creates a robust framework for solving complex real-world optimization problems with constraints. For researchers and drug development professionals, these methodologies offer promising avenues for tackling multifaceted optimization challenges where constraints are inherent and tasks are interrelated. Future research directions may include extending these principles to multiobjective constrained multitasking problems and developing more sophisticated criteria for curating archive contents to further enhance algorithmic performance and efficiency.
Performance Validation, Benchmark Testing, and Comparative Algorithm Analysis
Evolutionary Multitask Optimization (EMTO) represents a paradigm shift within evolutionary computation, moving beyond traditional single-task optimization to address multiple optimization tasks simultaneously. Inspired by the concept of transfer learning in machine learning, EMTO algorithms leverage implicit parallelism to exploit synergies between related tasks, often leading to accelerated convergence and superior solution quality compared to isolated optimization approaches [83] [78]. The foundational algorithm in this field is the Multifactorial Evolutionary Algorithm (MFEA), which introduces a unified search space where a single population evolves solutions for all tasks concurrently. The core innovation lies in its knowledge transfer mechanism, which allows genetic material from one task to potentially enhance the search process for another task through specialized crossover operations [1]. This bidirectional knowledge transfer distinguishes EMTO from sequential transfer optimization and enables mutual enhancement between tasks.
The performance of EMTO algorithms is critically dependent on the effectiveness of knowledge transfer between tasks. When tasks are related, knowledge transfer can lead to positive transfer, significantly improving optimization performance. However, when tasks are unrelated or negatively correlated, negative transfer can occur, where inappropriate genetic exchange deteriorates performance [1] [78]. The challenge of mitigating negative transfer while promoting positive exchange has driven extensive research into adaptive transfer strategies, similarity measurement between tasks, and specialized benchmark problems for proper algorithmic evaluation. Within this context, standardized benchmark problems have become essential for rigorous comparison and advancement of EMTO methodologies, with the CEC2017 MFO and WCCI20 test suites emerging as pivotal standards in the field.
The CEC2017 Multifactorial Optimization Benchmark Suite
The CEC2017 Multifactorial Optimization (MFO) benchmark suite was specifically designed for the Competition on Evolutionary Multitask Optimization held at the IEEE Congress on Evolutionary Computation (CEC) in 2017. This comprehensive suite provides a standardized framework for evaluating and comparing the performance of EMTO algorithms across diverse problem characteristics and inter-task relationships [1] [84].
Structural Framework and Mathematical Formulation
The CEC2017 MFO benchmark employs a rigorous mathematical structure where all test functions are systematically shifted and rotated to create varied fitness landscapes with controlled properties. Each function in the suite follows the general formulation:
Fi = fi(Mi(x - oi)) + F_i*
Where:
- x represents the decision vector in the unified search space
- o_i is the shift vector for task i, which translates the optimum to different locations
- M_i is the rotation matrix for task i, which introduces variable interactions and non-separability
- f_i(·) is the base function defining the core landscape characteristics
- F_i* is the known global optimum value used for performance measurement [85]
The search space for all functions is defined within [-100, 100]^D, where D represents the dimensionality of the problem. This consistent boundary condition ensures fair comparison across different algorithms [85].
Benchmark Composition and Task Relationships
The CEC2017 suite encompasses a diverse collection of optimization tasks with carefully designed inter-task relationships that mimic real-world scenarios. The complete benchmark includes problems with varying degrees of task relatedness, from highly similar tasks that benefit significantly from knowledge transfer to dissimilar tasks where transfer may be detrimental [1]. This diversity enables comprehensive evaluation of an algorithm's ability to identify and exploit beneficial transfer opportunities while minimizing negative transfer.
Table 1: Key Characteristics of CEC2017 MFO Benchmark Problems
| Problem Type | Task Relationships | Landscape Features | Key Challenges |
|---|---|---|---|
| Complete Overlap | Identical global optima positions | Different local landscapes around optimum | Maintaining convergence while avoiding premature convergence |
| Partial Overlap | Similar but not identical optima | Shared basin of attraction with offset optima | Identifying useful genetic material for transfer |
| No Overlap | Completely different optima | Distinct and potentially competing basins | Preventing negative transfer between unrelated tasks |
| Negative Transfer | Misleading similarities | Deceptive gradients between tasks | Recognizing and blocking detrimental knowledge exchange |
The benchmark problems are derived from classical optimization functions including Zakharov, Cigar, and Rosenbrock functions, which are transformed through shifting and rotation to create sophisticated test scenarios with properties such as multimodality, non-separability, and ill-conditioning [85]. These characteristics pose significant challenges for optimization algorithms and provide meaningful assessment of EMTO performance in handling complex, real-world inspired scenarios.
WCCI20-MTSO and WCCI20-MaTSO Benchmark Suites
The WCCI20 benchmark suites were introduced for the Competition on Multitask Optimization at the 2020 IEEE World Congress on Computational Intelligence (WCCI). These suites represent significant advancements over previous benchmarks, offering more sophisticated problem structures and specialized challenges for emerging EMTO methodologies [1].
WCCI20-MTSO: Multitask Single-Objective Problems
The WCCI20-MTSO benchmark focuses exclusively on single-objective multitask optimization problems with enhanced complexity and realism. Key innovations in this suite include:
- Asymmetric task dimensionalities: Tasks within the same multitask environment may have different search space dimensionalities, requiring specialized encoding/decoding strategies
- Heterogeneous function pairs: Combinations of different base functions (e.g., Sphere-Rastrigin, Rosenbrock-Ackley) with controlled overlap in their global basins
- Controlled inter-task relationships: Precisely calibrated similarity measures between tasks to facilitate systematic study of transfer effectiveness
- Large-scale instances: Problems with high dimensionality to evaluate scalability of EMTO algorithms [1]
WCCI20-MaTSO: Many-Task Single-Objective Problems
The WCCI20-MaTSO benchmark extends the concept to "many-task" optimization, featuring environments with larger numbers of concurrent tasks (typically more than two). This suite addresses the emerging challenge of optimizing numerous related tasks simultaneously, which presents unique algorithmic difficulties:
- Cross-task interference management: Preventing performance degradation as the number of tasks increases
- Selective transfer mechanisms: Identifying the most beneficial transfer pairs among many possibilities
- Computational resource allocation: Distributing limited computational budget across multiple tasks
- Task grouping and clustering: Automatically discovering groups of highly related tasks for efficient knowledge sharing [1]
Methodological Framework for Benchmark Evaluation
Rigorous experimental methodology is essential for meaningful evaluation of EMTO algorithms on these benchmark suites. The following protocols establish standardized procedures for obtaining comparable, statistically sound performance assessments.
Algorithm Implementation Specifications
Diagram: MFEA Workflow with Knowledge Transfer
The MFEA framework employs specific mechanisms for handling multiple tasks simultaneously. The core process begins with population initialization in a unified search space, followed by skill factor assignment where each individual is evaluated on all tasks but assigned to the task where it performs best [1]. Key algorithmic components include:
- Assortative mating: A controlled crossover mechanism where individuals with the same skill factor mate freely, while those with different skill factors mate probabilistically based on the Random Mating Probability (RMP) parameter
- Vertical cultural transmission: Offspring inherit the skill factor of whichever parent they more closely resemble genetically
- Scalar fitness: A unified fitness measure enables direct comparison of individuals optimized for different tasks, calculated as φi = 1/min{j∈{1,...,n}}{rj^i} where rj^i is the factorial rank [1]
- Factorial cost: The raw objective value Ψ_j^i of individual i on task j [1]
Performance Metrics and Evaluation Criteria
Comprehensive evaluation requires multiple performance metrics to capture different aspects of algorithmic effectiveness:
- Convergence accuracy: Measured as the error from known global optima (Fi - Fi^*) across all tasks
- Convergence speed: Number of function evaluations or generations required to reach target solution quality
- Transfer effectiveness: Ratio of positive to negative transfers, measured by performance improvement or degradation relative to single-task optimization
- Statistical significance: Non-parametric tests like Wilcoxon signed-rank test for paired comparisons and Friedman test for multiple algorithm rankings [1] [86]
Table 2: Standard Experimental Configuration for Benchmark Evaluation
| Parameter | CEC2017 Recommendation | WCCI20 Recommendation | Purpose |
|---|---|---|---|
| Population Size | 60 per task | 30-100 per task | Balance exploration and computational efficiency |
| Maximum Generations | 100-500 (depending on dimensionality) | 200-1000 (depending on complexity) | Ensure sufficient convergence time |
| Independent Runs | 30 | 25 | Statistical reliability of results |
| RMP Settings | 0.3 for fixed, adaptive for advanced algorithms | Fully adaptive strategies | Control inter-task knowledge transfer |
| Search Space | [-100, 100]^D | Task-specific dimensionalities | Standardized boundary conditions |
Advanced Analysis Techniques
Beyond basic performance metrics, sophisticated analysis methods provide deeper insights into algorithmic behavior:
- Search trajectory visualization: Projecting population movement through generations to understand exploration-exploitation balance
- Transfer footprint analysis: Quantifying the direction and magnitude of knowledge exchange between specific task pairs
- Computational complexity profiling: Measuring runtime and memory requirements as functions of problem dimensionality and task count
- Sensitivity analysis: Assessing parameter robustness across different benchmark categories [1] [86]
Knowledge Transfer Mechanisms and Adaptive Strategies
The core challenge in EMTO is designing effective knowledge transfer mechanisms that maximize positive transfer while minimizing negative transfer. Recent research has developed sophisticated strategies to address this challenge.
Categorization of Transfer Approaches
Diagram: Knowledge Transfer Taxonomy in EMTO
Knowledge transfer methods in EMTO can be systematically categorized based on when transfer occurs and how it is implemented [78]:
When to Transfer:
- Online similarity estimation: Continuously monitoring and quantifying inter-task relationships during evolution
- Success-history based adaptation: Adjusting transfer probabilities based on recent success rates of cross-task operations
- Fixed schedule approaches: Predetermined transfer patterns based on problem-specific knowledge
How to Transfer:
- Implicit methods: Leveraging standard genetic operators with minimal modification for cross-task exchange
- Explicit methods: Constructing direct mappings between task search spaces using domain adaptation techniques
- Multi-knowledge approaches: Combining individual-level and population-level transfer strategies [1] [78]
Innovative Transfer Strategies
Recent algorithms have introduced sophisticated transfer mechanisms that demonstrate state-of-the-art performance on the benchmark suites:
- EMT-ADT (Adaptive Transfer Strategy based on Decision Tree): Defines individual transfer ability and uses decision tree models to predict promising transfer candidates, significantly improving positive transfer rates [1]
- MFEA-II (with online transfer parameter estimation): Replaces scalar RMP with an adaptive RMP matrix that captures non-uniform inter-task synergies and continuously updates transfer probabilities based on evolutionary progress [1]
- M-MFEA (Mutagenic MFEA based on trait segregation): Incorporates biological inspiration from trait segregation to naturally guide genetic exchange without manually predefined parameters [9]
- Domain adaptation techniques: Employ affine transformations and autoencoders to bridge gaps between distinct problem domains, enabling more effective knowledge transfer [1]
The Scientist's Toolkit: Essential Research Reagents
Table 3: Essential Research Tools for EMTO Benchmark Evaluation
| Tool Category | Specific Implementation | Function in Research | Application Example |
|---|---|---|---|
| Benchmark Suites | CEC2017 MFO, WCCI20-MTSO, WCCI20-MaTSO | Standardized problem sets for algorithmic comparison | Base performance evaluation across diverse task relationships |
| Algorithm Frameworks | MFEA, MFEA-II, EMT-ADT, M-MFEA | Reference implementations with modular components | Prototyping new transfer strategies |
| Performance Analysis | PlatEMO, NEORL | Comprehensive evaluation metrics and statistical testing | Automated performance profiling and visualization |
| Search Engines | SHADE, DE, PSO | Foundation for building EMTO variants | Demonstrating generality of MFO paradigm [1] |
| Similarity Measures | Task-relatedness metrics, Transfer ability indicators | Quantifying inter-task relationships | Predicting beneficial transfer opportunities [1] |
The CEC2017 MFO and WCCI20 test suites represent critical infrastructure for advancing evolutionary multitask optimization research. These standardized benchmarks enable rigorous comparison of emerging algorithms and provide controlled environments for studying fundamental aspects of knowledge transfer in optimization. The continued development and refinement of EMTO methodologies on these benchmarks has led to significant insights into managing complex multitask environments, particularly through adaptive transfer strategies that dynamically respond to inter-task relationships.
Future research directions include expanding benchmark complexity to better mirror real-world scenarios, developing more sophisticated transferability assessment techniques, and creating specialized benchmarks for emerging EMTO subfields such as many-task optimization and heterogeneous task representations. As noted in recent surveys, the integration of EMTO with other AI paradigms such as large language models presents promising opportunities for automated algorithm design and enhanced problem-solving capabilities [87]. The continued evolution of benchmark suites will play a vital role in guiding and evaluating these advancements, ultimately strengthening the theoretical foundations and practical applications of multifactorial evolutionary computation.
In the domain of evolutionary computation, Multifactorial Evolutionary Algorithms (MFEAs) represent a paradigm shift towards multitask optimization, enabling the simultaneous solution of multiple, potentially distinct, optimization problems by leveraging their underlying synergies. The core principle of MFEAs involves the implicit transfer of knowledge across tasks, which can lead to accelerated convergence and the discovery of superior solutions. Within this context, the rigorous assessment of algorithm performance becomes paramount. The trio of solution precision, convergence speed, and computational efficiency serves as the foundational criteria for evaluating and advancing MFEA research, providing quantifiable measures to gauge the effectiveness of knowledge transfer and search capabilities in both benchmark and real-world problems [13] [88].
Solution precision refers to the accuracy and quality of the solution obtained by the algorithm, typically measured by its proximity to a known global optimum or its performance against established benchmarks. Convergence speed quantifies the rate at which an algorithm approaches a high-quality solution, directly impacting its practicality for time-sensitive applications. Computational efficiency is a broader metric that encompasses the resources consumed, including runtime, memory usage, and computational overhead (e.g., FLOPs), which is critical for deploying algorithms on large-scale or resource-constrained platforms [13] [89] [90]. For MFEAs, these metrics are not only assessed per task but also in the aggregate, evaluating the algorithm's overall multitasking prowess.
Quantifying Performance: Metrics and Mathematical Formulations
Core Metrics and Their Calculations
The evaluation of MFEA performance relies on a set of well-defined quantitative metrics. The following table summarizes the key metrics, their definitions, and typical formulations used in empirical studies.
Table 1: Core Performance Metrics for Multifactorial Evolutionary Algorithms
| Metric | Definition | Typical Formulation/Description |
|---|---|---|
| Solution Precision | The quality or accuracy of the best-found solution. | Often measured as the objective function value of the final solution. For comparison, Relative Percentage Difference (RPD) is used: RPD = (Solution - Best) / Best * 100, where "Best" is the best-known solution [13]. |
| Convergence Speed | The rate at which the algorithm converges to a high-quality solution. | Measured by the number of iterations (generations) or function evaluations required to reach a pre-defined solution quality threshold [91]. |
| Computational Efficiency | The computational resources required by the algorithm. | Includes Runtime (e.g., in milliseconds), Parameter Count, and FLOPs (Floating Point Operations) for a given problem size [13] [89]. |
| Robustness/Stability | The consistency of performance across multiple independent runs. | Often reported as the standard deviation or variance of solution quality metrics (e.g., PSNR, RPD) over 30 or more test runs [13]. |
Domain-Specific Adaptation of Metrics
While the core metrics are universal, their specific instantiation can vary by application domain. In network robustness optimization, solution precision may be quantified using a robustness metric R that measures the residual connectivity of a network under sequential node removal, calculated as ( R = \frac{1}{N} \sum{i=0}^{N-1} \frac{N{LCC}(i)}{N-i} ), where ( N_{LCC}(i) ) is the size of the largest connected component after i node removals [90]. In contrast, for image super-resolution tasks, precision is frequently measured using the Peak Signal-to-Noise Ratio (PSNR) in decibels (dB), where a higher value indicates a reconstruction closer to the original high-resolution image [89].
Experimental Protocols for Performance Evaluation
A standardized experimental protocol is essential for the fair and reproducible comparison of MFEAs. The following workflow outlines the key stages in a comprehensive performance evaluation, from problem selection to data analysis.
Figure 1: Workflow for MFEA Performance Evaluation
Benchmark Selection and Problem Instantiation
The first step involves selecting appropriate benchmark problems. Research indicates a strong preference for standardized test suites like IEEE CEC 2017 and IEEE CEC 2022, which provide a range of constrained and unconstrained optimization problems of varying complexity and modality [91]. For domain-specific evaluations, established datasets are crucial. For instance:
- Inter-Domain Path Computation (IDPC-NDU): Uses specific datasets categorized by network size (e.g., small: 50-2000 vertices; large: ≥2000 vertices) [13].
- Efficient Super-Resolution: Relies on standard image datasets like DIV2K and LSDIR, with Low-Resolution (LR) images generated via bicubic downsampling [89].
Algorithm Configuration and Experimental Execution
To ensure a fair comparison, algorithms are typically implemented using a common programming framework and evaluated on identical hardware. A standard practice is to execute each algorithm over a significant number of independent runs (e.g., 30 independent runs) to account for stochastic variations [13]. Key configuration aspects include:
- Population Size: Determined by problem complexity.
- Termination Condition: A maximum number of generations or function evaluations.
- Constraint Handling: Techniques like dynamic, tolerance-based methods are employed for constrained problems [91].
Runtime is often measured on a standardized platform, for example, an Intel Core i7 CPU with a single NVIDIA RTX A6000 GPU for tasks involving deep learning models, ensuring that computational efficiency metrics are consistent and comparable [13] [89].
The Scientist's Toolkit: Essential Research Reagents
The following table catalogues the key computational "reagents" and resources essential for conducting MFEA research and performance benchmarking.
Table 2: Essential Research Reagents for MFEA Performance Analysis
| Tool/Resource | Type | Function in Research |
|---|---|---|
| IEEE CEC Benchmark Suites (e.g., 2017, 2022) | Software/Dataset | Provides a standardized set of optimization problems for rigorously testing algorithm performance, generality, and scalability [91]. |
| Domain-Specific Datasets (e.g., DIV2K, LSDIR, IDPC-NDU instances) | Dataset | Enables domain-specific validation (e.g., for image processing or network routing) and ensures relevance to real-world applications [13] [89]. |
| Graph Isomorphism Network (GIN) | Software Model | A type of Graph Neural Network (GNN) used as a surrogate model to approximate expensive objective functions (e.g., network robustness evaluation), drastically reducing computational cost [90]. |
| Node-Depth Encoding (NDE) | Algorithmic Operator | A solution representation scheme that allows for efficient and constraint-satisfying evolutionary operators (crossover, mutation) on tree and graph structures, improving solution construction and search efficiency [13]. |
| Reinforcement Convergence Mechanism | Algorithmic Strategy | An adaptive method embedded within an algorithm (e.g., the KING algorithm) to systematically balance global exploration and local exploitation, leading to faster and more stable convergence [91]. |
Case Studies in Performance Optimization
Case Study 1: Network Robustness Optimization with Surrogate Models
A significant challenge in network robustness optimization is the high computational cost of a posteriori robustness evaluation, which involves simulating numerous attack sequences. To address this, MOEA-GIN leverages a Graph Isomorphism Network (GIN) as a surrogate model. The GIN model learns to map network structures directly to their robustness evaluation, bypassing the need for expensive simulations during the majority of the evolutionary search [90].
- Performance Gain: This approach reduced the computational cost of robustness evaluation by approximately 65% while achieving comparable or superior solution precision compared to traditional methods. This demonstrates a direct trade-off where a gain in computational efficiency does not necessarily come at the cost of solution quality [90].
Case Study 2: KING Algorithm's Convergence Mechanism
The Three Kingdoms Optimization Algorithm (KING) incorporates a reinforcement convergence mechanism inspired by historical dynamics. This mechanism systematically guides the search process by dynamically adjusting the balance between exploration and exploitation across four phases: Ascent of the Might, Joint Confrontation, Three-Legged Tripod, and Whole Country United [91].
- Performance Gain: When benchmarked on IEEE CEC 2017/2022 test suites, KING demonstrated superior convergence speed and solution accuracy against classical and state-of-the-art peers. The explicit design for balancing search phases resulted in more efficient convergence, validating the importance of such mechanisms for performance [91].
Case Study 3: MFEA for Inter-Domain Path Computation
The NDE-MFEA was developed to solve the NP-Hard Inter-Domain Path Computation problem. It introduced a novel node-depth encoding for solution representation and leveraged the MFEA's inherent capability for implicit knowledge transfer between related tasks [13].
- Performance Gain: Extensive experiments showed that NDE-MFEA significantly outperformed existing competitive algorithms in terms of solution quality, convergence trends, and computational efficiency. The knowledge transfer in the multitasking environment directly contributed to improved exploitation in promising regions of the search space, enhancing both precision and convergence speed [13].
Analysis of Performance Trade-offs and Synergies
The case studies reveal that performance metrics in MFEA are often interconnected. The relationship between these metrics can be visualized as a dynamic system of trade-offs and synergies, which algorithm designers must navigate.
Figure 2: Trade-offs and Synergies Between Core Performance Metrics
- Synergies between Solution Precision and Convergence Speed: Effective knowledge transfer (a core facet of MFEA) and sophisticated reinforcement convergence mechanisms can create a virtuous cycle. By efficiently leveraging learned patterns across tasks (knowledge transfer) or dynamically focusing search effort (convergence mechanisms), MFEAs can find better solutions in fewer generations, enhancing both precision and speed [13] [91].
- Trade-off between Precision and Computational Efficiency: The use of surrogate models (like GIN) primarily boosts computational efficiency by reducing the cost of each evaluation. However, an inaccurate surrogate model can misguide the search, potentially leading to a reduction in final solution precision. This establishes a classic trade-off that must be carefully managed [90].
- Achieving Holistic Performance: The most advanced MFEAs, such as those cited, aim to simultaneously optimize all three metrics. This is achieved not by treating them in isolation, but by integrating strategies like knowledge transfer, efficient encoding schemes, and adaptive convergence controls, which collectively push the Pareto front of performance outward [13] [91] [90].
Evolutionary algorithms (EAs) are population-based metaheuristics inspired by the principle of "survival of the fittest" that have been successfully applied to complex optimization problems [11]. Traditionally, these algorithms tackle problems in isolation under the assumption of zero prior knowledge. However, this approach fails to leverage potential synergies when multiple related optimization tasks exist. Multifactorial Evolutionary Algorithm (MFEA) represents a paradigm shift from this conventional single-task evolutionary optimization by enabling simultaneous optimization of multiple tasks with knowledge transfer between them [71]. EMTO works on the principle that if common useful knowledge exists among tasks, then knowledge gained while solving one task may help solve another related task [11]. For drug development professionals, this approach mirrors how historical research data and experiences can inform new drug discovery efforts, potentially reducing failure rates and accelerating development timelines [92].
Theoretical Foundations
Single-Task Evolutionary Algorithms (STEAs)
Single-task evolutionary algorithms operate on the fundamental principle of maintaining a population of candidate solutions that undergo selection, recombination, and mutation to progressively improve fitness toward a single objective function. These algorithms—including Genetic Algorithms (GAs), Differential Evolution (DE), and Particle Swarm Optimization (PSO)—treat each optimization problem as an independent process without leveraging potential correlations with other tasks [71]. In pharmaceutical contexts, this would equate to optimizing drug formulations or clinical trial designs without transferring insights from related previous development projects.
The limitation of STEAs lies in their "greedy search" approach that begins from scratch for each new problem, potentially overlooking valuable information from previously solved related tasks. This becomes particularly inefficient in business and research environments where optimization tasks often share underlying patterns or characteristics [71].
Multifactorial Evolutionary Algorithm (MFEA)
MFEA introduces a revolutionary framework that creates a multi-task environment where a single population evolves to solve multiple tasks simultaneously [71]. The algorithm treats each task as a unique "cultural factor" influencing the population's evolution, with knowledge transfer occurring through two core mechanisms:
- Assortative Mating: Allows individuals with different skill factors (representing different tasks) to mate with a specified probability, controlled by the random mating probability (rmp) parameter [71] [1].
- Selective Imitation: Enables offspring to inherit genetic material from parents specialized in different tasks [71].
The population is divided into non-overlapping task groups based on skill factors, with each group focusing on a specific task. MFEA employs specialized definitions for comparing individuals in multitasking environments, including factorial cost, factorial rank, scalar fitness, and skill factor [1].
Figure 1: MFEA Architecture with Knowledge Transfer
Knowledge Transfer Mechanisms and Advancements
The Challenge of Negative Transfer
A critical challenge in MFEA implementation is "negative transfer"—when knowledge shared between unrelated or low-similarity tasks deteriorates optimization performance rather than enhancing it [1]. This phenomenon is analogous to applying insights from unrelated drug development projects, which could lead to misguided decisions and wasted resources. In early MFEA implementations, negative transfer frequently occurred when the random mating probability (rmp) parameter was improperly set without prior knowledge of inter-task similarity [1].
Advanced Transfer Strategies
Recent research has developed sophisticated strategies to mitigate negative transfer:
- Adaptive Parameter Control: MFEA-II replaces the scalar rmp with a symmetric matrix that captures non-uniform inter-task synergies and continuously adapts during the search process [1].
- Domain Adaptation Techniques: Linearized Domain Adaptation (LDA) transforms search spaces to improve correlations between representative spaces and their constitutive tasks [1].
- Probabilistic Modeling: Approaches like AMTEA construct probabilistic models from elite solution distributions to provide promising search directions for related target tasks [1].
- Gaussian Mixture Models (GMM): MFDE-AMKT uses GMM to capture subpopulation distributions for each task, with mixture weights adaptively adjusted based on probability density overlap [11].
- Decision Tree Prediction: EMT-ADT implements a decision tree to predict individual transfer ability, selectively promoting positive-transferred individuals [1].
Figure 2: Advanced Knowledge Transfer Strategies in MFEA
Quantitative Performance Comparison
Convergence Speed and Solution Quality
Experimental studies across single-objective and multi-objective multi-task test suites demonstrate that MFEA variants consistently outperform single-task EAs in both convergence speed and solution quality when tasks exhibit sufficient relatedness [11].
Table 1: Performance Comparison on Benchmark Problems
| Algorithm | Convergence Speed | Solution Quality | Robustness to Negative Transfer | Computational Efficiency |
|---|---|---|---|---|
| Single-Task EA | Baseline | Baseline | Not Applicable | High for single problems |
| Basic MFEA | 20-40% faster [71] | Comparable | Low | Moderate |
| MFEA-II | 30-50% faster [1] | 5-15% better | Medium | Moderate |
| MFDE-AMKT | 45-60% faster [11] | 10-20% better | High | Moderate to High |
| EMT-ADT | 40-55% faster [1] | 8-18% better | High | Moderate |
Multi-Objective Performance
For multi-objective problems, MOMFEA-STT incorporates a source task transfer strategy that establishes parameter sharing models between historical and target tasks, dynamically adjusting knowledge transfer intensity based on association strength [22]. This approach demonstrates superior performance compared to NSGA-II and MOMFEA on multi-task optimization benchmarks, particularly when dealing with complex interactions between multiple optimization goals [22].
Table 2: Multi-Objective Algorithm Comparison
| Algorithm | Pareto Front Coverage | Solution Diversity | Inter-Task Knowledge Utilization | Application Complexity |
|---|---|---|---|---|
| NSGA-II | High | High | None | Low |
| MOMFEA | Medium | Medium | Basic | Medium |
| MOMFEA-II | High | Medium-High | Adaptive | Medium-High |
| MOMFEA-STT | High | High | Historical Task Learning | High |
Pharmaceutical and Drug Development Applications
Drug Discovery Optimization
In pharmaceutical research, MFEA approaches show significant promise for optimizing multiple aspects of drug discovery simultaneously. Potential applications include:
- Target Validation and Identification: Simultaneously evaluating multiple potential drug targets while sharing knowledge about biological pathways and structure-activity relationships [92].
- Compound Design and Optimization: Conducting multi-task optimization of compound properties including efficacy, toxicity, and pharmacokinetics while leveraging common molecular patterns [92].
- Biomarker Development: Identifying prognostic biomarkers and analyzing digital pathology data across multiple related clinical trials [92].
The business case for applying MFEA in drug development is compelling, given the notoriously low success rates (approximately 6.2%) in pharmaceutical development and the tremendous costs associated with late-stage failures [92].
Clinical Trial Optimization
MFEA can enhance clinical trial design through:
- Dose-Response Optimization: Implementing model-based meta-analysis (MBMA) that incorporates longitudinal data and dose-response relationships across multiple studies [93].
- Competitive Benchmarking: Comparing investigational drugs against established treatments using network meta-analysis extended through evolutionary multitasking [93].
- Patient Stratification: Simultaneously optimizing trial parameters for different patient subgroups while sharing insights across populations.
Implementation Methodologies
Experimental Protocol for Algorithm Comparison
To conduct a rigorous comparison between MFEA and single-task EAs, researchers should implement the following experimental protocol:
- Benchmark Selection: Utilize established multi-task test suites such as CEC2017 MFO benchmark problems, WCCI20-MTSO, and WCCI20-MaTSO [1].
- Algorithm Configuration:
- Implement single-task EA controls using Differential Evolution (DE) or Genetic Algorithms (GA)
- Configure basic MFEA with assortative mating and vertical cultural transmission
- Implement advanced MFEA variants (MFEA-II, MFDE-AMKT) with adaptive transfer mechanisms
- Performance Metrics:
- Convergence speed: iterations to reach target solution quality
- Solution quality: objective function values at termination
- Success rate: proportion of runs finding acceptable solutions
- Computational efficiency: function evaluations and wall-clock time
Research Reagent Solutions
Table 3: Essential Research Components for MFEA Implementation
| Component | Function | Implementation Examples |
|---|---|---|
| Optimization Engine | Core evolutionary search mechanism | Differential Evolution, Genetic Algorithm, Particle Swarm Optimization |
| Knowledge Transfer Controller | Manage inter-task information flow | Random Mating Probability (RMP) matrix, Gaussian Mixture Models, Decision Trees |
| Similarity Metrics | Quantify inter-task relationships | Wasserstein distance, Probability density overlap, Cosine similarity [11] |
| Adaptive Mechanisms | Dynamically adjust transfer parameters | Success-history based adaptation, Q-learning rewards, Online similarity learning [22] |
| Benchmark Problems | Algorithm validation | CEC2017 MFO, WCCI20-MTSO, WCCI20-MaTSO test suites [1] |
MFEA represents a significant advancement over single-task evolutionary algorithms by leveraging implicit parallelism and knowledge transfer between related optimization tasks. For drug development professionals, these algorithms offer a methodological framework that mirrors the cumulative nature of scientific research, where insights from previous experiments inform new investigations. While challenges remain—particularly regarding negative transfer between unrelated tasks—advanced MFEA variants with adaptive knowledge transfer mechanisms have demonstrated robust performance improvements across diverse benchmark problems and practical applications. As pharmaceutical research continues to grapple with complex, multi-faceted optimization challenges, MFEA approaches provide a powerful tool for accelerating discovery while efficiently utilizing accumulated research knowledge. Future research directions should focus on enhancing task-relatedness detection, developing more efficient transfer mechanisms, and expanding applications to emerging pharmaceutical challenges such as personalized medicine and real-world evidence integration.
Multifactorial Evolutionary Algorithm (MFEA) research represents a significant advancement within the field of evolutionary multitasking (EMT), which aims to solve multiple optimization tasks simultaneously. The core principle behind MFEA is the implicit transfer of knowledge across tasks, allowing for the concurrent optimization of several problems with the potential for accelerated convergence and improved solution quality. Within this broader context, a critical research direction focuses on establishing robust theoretical foundations for these algorithms, particularly concerning their convergence behavior and the strategic integration of gradient-based methods. For the drug development community, where in silico optimization of molecular properties is both computationally expensive and critically important, these advancements promise more reliable and efficient computational tools. This guide provides an in-depth technical examination of the convergence guarantees now being established for MFEAs and the methodologies for hybridizing them with gradient descent, complete with experimental protocols and practical resources for implementation.
Convergence Analysis in Multifactorial Evolutionary Algorithms
The canonical MFEA implements knowledge transfer among optimization tasks via its unique crossover and mutation operators, which allow genetic material to be exchanged between individuals representing solutions to different tasks. Despite its empirical success, a significant theoretical limitation has been the lack of formal convergence guarantees for the population, as well as a clear explanation of how exactly knowledge transfer bolsters algorithmic performance [94]. This gap has prompted the development of new algorithms with provable convergence properties.
MFEA with Diffusion Gradient Descent (MFEA-DGD)
A pivotal development is the MFEA based on Diffusion Gradient Descent (MFEA-DGD). This algorithm is designed to endow the evolutionary population with a dynamic equation analogous to DGD, thereby providing a mathematical framework for analysis.
- Theoretical Foundation: The convergence of the DGD process for multiple similar tasks has been formally proven. A key insight from this analysis is that the local convexity of a subset of tasks can assist other tasks in escaping from local optima through the mechanism of knowledge transfer [94]. This provides a theoretical explanation for the empirical benefits of multitasking.
- Algorithmic Design: Based on this foundation, complementary crossover and mutation operators were designed specifically for MFEA-DGD. Furthermore, a hyper-rectangular search strategy was introduced to facilitate exploration in both the unified search space (spanning all tasks) and the individual subspaces of each task [94].
- Experimental Verification: MFEA-DGD has been validated on various multitask optimization problems, demonstrating an ability to converge faster to competitive results compared to state-of-the-art EMT algorithms. The theoretical framework also allows for the interpretation of experimental results based on the convexity of the different tasks involved [94].
Convergence Rates in Related Hybrid Algorithms
While not specific to the multifactorial case, convergence analyses of other evolutionary-gradient hybrids inform the broader field. For instance, the Evolutionary Stochastic Gradient Descent (ESGD) framework guarantees that the best fitness in the population will never degrade, thanks to a back-off strategy in the SGD step and an elitist strategy in the evolution step [95]. Another algorithm, MADAGRAD, provides specific convergence rates: a linear rate for smooth and strongly convex cost functions in the deterministic setting, and a gradient convergence of order O(1/k) for non-convex cost functions with Lipschitz continuous gradients in both deterministic and stochastic settings [96].
Gradient Descent Integration Methodologies
The integration of gradient descent with evolutionary algorithms creates powerful hybrid optimizers that combine the global exploration capabilities of population-based search with the efficient local convergence of gradient-based methods.
Architectural Frameworks for Integration
- Evolutionary Gradient Descent (EGD): This algorithm integrates classic EA components—a population and mutation—with Gradient Descent (GD). It has been proven that EGD can converge to a second-order stationary point by effectively escaping saddle points, a common challenge in non-convex optimization. This makes it particularly suitable for complex AI tasks, including reinforcement learning [97].
- Evolutionary Stochastic Gradient Descent (ESGD): This framework alternates between an SGD step and an evolution step to improve the average fitness of the population. It treats individuals optimized with different SGD-based optimizers and hyperparameters as competing species in a coevolution setting, thereby leveraging the complementarity of optimizers [95].
- Coupling with Conjugate Gradients: For large-scale continuous multi-objective problems, a hybrid algorithm couples Differential Evolution (DE) with a conjugate gradient method. The conjugate gradient drives rapid convergence toward the Pareto front, while DE promotes diversity across the front. An objective decomposition strategy differentiates the conjugate gradients for various solutions, and a line search strategy ensures each offspring is of higher quality than its parent [98].
Surrogate-Assisted and Learning-Based Integration
- Gradient-Descent-Like Learning (GDL): In Surrogate-Assisted Evolutionary Algorithms (SAEAs) for expensive many-objective optimization, a GDL operator can be embedded to guide offspring generation. This operator uses a trained neural network to determine the fastest convergence direction for each solution, leveraging relationships within the current population and the surrogate model [99].
- Anchor-Based Supervision: The GDL operator often uses an anchor-based supervision mechanism. The population is segmented, and triple training data is generated. Each elite solution acts as a label for a corresponding poorer solution, with a midpoint serving as an anchor to enhance the supervised learning of the convergence process [99].
Experimental Protocols and Validation
To validate the performance of algorithms combining MFEAs with gradient descent, rigorous experimental protocols are essential. The following methodology outlines a standard approach for benchmarking.
Protocol for Benchmarking MFEA-DGD
- Problem Selection: Choose a diverse set of multitask optimization benchmarks. These should include tasks with varying degrees of similarity and landscape characteristics (e.g., convex, non-convex) to test knowledge transfer and convergence.
- Algorithm Configuration:
- Implement the proposed MFEA-DGD with its specialized crossover and mutation operators.
- Set parameters for the hyper-rectangular search strategy to balance exploration and exploitation.
- Comparative Analysis:
- Run state-of-the-art EMT algorithms (e.g., canonical MFEA) and single-task evolutionary algorithms on the same problem set.
- Use performance metrics such as convergence speed (number of function evaluations to reach a target fitness) and the quality of the final solutions (e.g., best fitness, hypervolume for multi-objective problems).
- Interpretation:
- Analyze the results in the context of the theoretical convergence proof. Examine how the convexity of certain tasks influenced the optimization of others, providing a post-hoc explanation for the empirical performance [94].
Protocol for Validating ESGD on Deep Neural Networks
- Application Domain: Select resource-intensive applications such as speech recognition, image recognition, and language modeling, using networks with deep architectures [95].
- Experimental Setup:
- Initialize a population of neural networks.
- For the SGD step, employ various base optimizers (e.g., SGD, Adam) with distinct hyperparameters for different individuals.
- For the evolution step, use a gradient-free evolutionary algorithm to recombine and mutate the populations.
- Validation and Comparison:
- Compare ESGD against standalone SGD and other population-based methods.
- Monitor the best fitness in the population to verify the non-degradation guarantee.
- Measure final performance on test sets to assess generalization.
Visualization of Algorithmic Workflows
MFEA-DGD Knowledge Transfer Process
The following diagram illustrates the core process of knowledge transfer in MFEA-DGD, which is facilitated by its specialized operators and the hyper-rectangular search strategy.
Diagram 1: MFEA-DGD Knowledge Transfer and Convergence
ESGD Alternating Framework
This diagram outlines the alternating structure of the ESGD framework, which cycles between gradient-based and evolutionary steps.
Diagram 2: ESGD Alternating Optimization Framework
For researchers aiming to implement or experiment with these algorithms, particularly in domains like drug design, the following tools and concepts are essential. The table below details key "research reagents" in the computational context.
Table 1: Key Research Reagents for Evolutionary-Gradient Hybrid Algorithms
| Item Name | Function / Role in the Experiment | Example / Specification |
|---|---|---|
| MFEA-DGD Framework | Provides the core algorithm with proven convergence guarantees for evolutionary multitasking. | Includes specialized crossover/mutation and hyper-rectangular search [94]. |
| SELFIES Representation | Ensures 100% validity of generated molecular structures during evolutionary operations, crucial for drug design. | Used in MOEAs for de novo molecular optimization [49]. |
| Quantitative Estimate of Druglikeness (QED) | A composite metric to evaluate and rank compounds based on their drug-like properties. | Combines 8 molecular descriptors (e.g., MW, ALOGP, HBD) into a single score [100]. |
| Surrogate Model (Kriging/NN) | Approximates expensive objective functions (e.g., molecular property prediction), drastically reducing computational cost. | Used in SAEAs; e.g., Kriging in ParEGO, Neural Networks in GDL-SAEA [99]. |
| GDL Operator | A neural network-based component that learns and guides offspring generation along gradient-descent-like directions. | Embeds into SAEAs to replace traditional crossover/mutation [99]. |
| Anchor-Based Supervision | A training mechanism that stabilizes learning in GDL operators by providing directional references for improvement. | Uses triplets of (poor solution, anchor, elite solution) [99]. |
| Compatibility Rules (Strict/Lax) | Knowledge-based rules that define which molecular fragments can be bonded, ensuring synthetic feasibility. | Used in LEADD; extracted from a library of drug-like molecules [101]. |
Application in Drug Design and Molecular Optimization
The integration of MFEAs with gradient-based approaches shows significant promise in the field of computer-aided drug design (CADD), where it helps traverse the vast chemical space efficiently.
- Multi-Objective Optimization for Drug Likeness: Multi-Objective Evolutionary Algorithms (MOEAs) like NSGA-II, NSGA-III, and MOEA/D are being deployed to optimize multiple molecular properties simultaneously. When combined with the SELFIES molecular representation, these algorithms can generate a diverse set of synthetically accessible candidate molecules [49].
- Lamarckian Evolutionary Algorithm (LEADD): LEADD uses a knowledge-based framework where molecules are represented as graphs of molecular fragments. Its genetic operators enforce atom type compatibility rules derived from drug-like molecules, striking a balance between optimization power and synthetic accessibility [101].
- Swarm Intelligence for Molecular Optimization: Algorithms like the Swarm Intelligence-Based Method for Single-Objective Molecular Optimization (SIB-SOMO) adapt metaheuristic frameworks to the molecular domain. They utilize operations like MIX and MOVE, along with Random Jump, to efficiently find near-optimal molecular structures for a given objective, such as maximizing QED [100].
Table 2: Performance Comparison of Evolutionary-Gradient Hybrid Algorithms
| Algorithm Name | Key Integration Feature | Reported Performance Advantage | Application Domain |
|---|---|---|---|
| MFEA-DGD | Diffusion Gradient Descent dynamics | Faster convergence to competitive results; provable convergence [94]. | General Multitask Optimization |
| ESGD | Alternates SGD and evolution steps | Non-degrading best fitness; effective on speech, image, and language tasks [95]. | Deep Neural Network Training |
| EGD | Combines population/mutation with GD | Escapes saddle points; converges to second-order stationary points [97]. | Non-convex Synthetic & RL Tasks |
| MADAGRAD | Multivariate adaptive learning rates | Linear convergence for strongly convex; O(1/k) for non-convex; reduced tuning [96]. | Image Classification Data Sets |
| GDL-SAEA | Neural network for descent direction | Superior HV and IGD on DTLZ, WFG, and real-world problems with up to 10 objectives [99]. | Expensive Many-Objective Optimization |
| LEADD | Lamarckian mechanism & fragment rules | Designs fitter, more synthetically accessible molecules more efficiently [101]. | De Novo Drug Design |
Multi-population evolutionary algorithms have emerged as a powerful paradigm for solving complex optimization problems across various domains, from dynamic multiobjective optimization to multitask problem-solving. These algorithms operate on the principle of dividing a population into multiple subpopulations, each potentially exploring different regions of the search space or addressing different aspects of an optimization problem. Within the broader context of multifactorial evolutionary algorithm (MFEA) research, understanding the coincidence relations—the theoretical and empirical alignments between different algorithmic frameworks—becomes crucial for advancing the field [102] [4].
The conceptual foundation of multi-population models lies in their ability to mimic natural ecosystems where multiple species coexist, interact, and collectively adapt to their environment [103]. This biological inspiration translates computationally into algorithms that can maintain population diversity, avoid premature convergence, and tackle problems with complex Pareto fronts or multiple conflicting objectives. As optimization problems in domains such as drug development, neural architecture search, and image processing grow increasingly complex [104] [105], the need for robust multi-population approaches becomes more pronounced.
This technical guide examines the theoretical foundations, experimental methodologies, and practical implementations of multi-population evolution models, with particular emphasis on verifying their performance and establishing their coincidence relations with related algorithmic frameworks such as MFEA.
Theoretical Foundations of Multi-Population Evolution
Basic Principles and Definitions
Multi-population evolutionary algorithms depart from traditional single-population approaches by maintaining multiple distinct subpopulations that evolve either independently or with controlled interactions. The fundamental components include:
- Subpopulation Management: Techniques for creating, maintaining, and potentially removing subpopulations based on performance metrics or diversity measures [106] [103]
- Interaction Mechanisms: Controlled information exchange between subpopulations through migration, crossover, or knowledge transfer operations [102] [4]
- Resource Allocation: Dynamic assignment of computational resources to different subpopulations based on their perceived utility [107]
The mathematical formulation of a multi-population optimization system typically involves multiple search populations P₁, P₂, ..., Pₖ evolving simultaneously, with interaction mappings Φᵢⱼ: Pᵢ → Pⱼ defining how information flows between populations i and j.
Coincidence Relations with Multifactorial Evolutionary Algorithms
A significant theoretical advancement in understanding multi-population evolution comes from establishing its coincidence relations with multifactorial evolutionary algorithms (MFEA). Research has demonstrated that MFEA can be rigorously analyzed as a multi-population evolution model, where each population is represented independently and evolved for selected tasks [102] [4].
The key coincidence relations include:
- Population-Task Mapping: In MFEA, individuals are implicitly assigned to specific tasks through skill factors, effectively creating subpopulations for each task [4]
- Unified Search Space: MFEA employs a unified representation scheme where all solutions exist in a common search space, enabling knowledge transfer across tasks [102]
- Implicit Parallelism: Both frameworks exhibit implicit parallel exploration of different regions of the search space or different optimization tasks [4]
These coincidence relations are not merely theoretical constructs but have practical implications for algorithm design and implementation, particularly in multi-task optimization scenarios common in drug development where researchers must optimize multiple molecular properties simultaneously.
Experimental Verification Frameworks
Benchmark Problems and Performance Metrics
Rigorous experimental verification of multi-population evolution models requires comprehensive benchmarking across diverse problem types. Standard benchmark suites include:
Table 1: Standard Benchmark Problems for Multi-Population Algorithm Verification
| Benchmark Category | Example Problems | Key Characteristics | Application Domain | |------------------------||------------------------|| | Dynamic Multiobjective Optimization | FDA, DF series [106] | Time-varying objectives and constraints | Internet of Things, network optimization | | Multitask Optimization | 25 MTO benchmark problems [4] | Multiple self-contained tasks solved simultaneously | Drug discovery, multi-property optimization | | Large-Scale Many-Objective Optimization | DTLZ, WFG, LSMOP [108] | High-dimensional decision and objective spaces | Cloud resource scheduling, smart grids | | Neural Architecture Search | CIFAR-10, CIFAR-100, ImageNet [105] | Architecture accuracy and complexity trade-offs | Automated deep learning design |
Performance evaluation employs both quantitative metrics and qualitative assessments:
- Convergence Metrics: Inverted Generational Distance (IGD), Hypervolume (HV)
- Diversity Indicators: Spread, Spacing, and Diversity Comparison Indicator [106]
- Statistical Testing: Friedman test with post-hoc analysis for multiple algorithm comparison [104]
- Efficiency Measures: Evaluation numbers, computational time, and convergence speed [4]
Experimental Protocols for Coincidence Relation Verification
To experimentally verify the coincidence relations between multi-population models and MFEA, researchers must implement specific experimental protocols:
- Algorithmic Recoding: Implement MFEA following a multi-population perspective, with explicit subpopulations for each task [4]
- Across-Population Crossover: Design crossover operations that allow information exchange between subpopulations while preventing population drift [4]
- Performance Comparison: Execute both traditional MFEA and multi-population MFEA on identical benchmark problems
- Statistical Analysis: Apply rigorous statistical tests to determine significant differences in performance
The critical null hypothesis in these experiments is that the multi-population interpretation of MFEA does not alter its algorithmic behavior or performance characteristics. Rejection of this hypothesis requires demonstrating significant performance differences with p-values < 0.05 in statistical tests [4].
Representative Multi-Population Algorithms and Experimental Results
Algorithmic Implementations Across Domains
Recent research has produced several innovative multi-population algorithms with verified performance across application domains:
Co-evolutionary Multi-population Evolutionary Algorithm (CMEA) Designed for dynamic multiobjective optimization problems (DMOPs), CMEA integrates three novel strategies: convergence-based population evolution (CPE), multi-population-based dynamic detection (MDD), and multi-population-based dynamic response (MDR) [106]. Experimental results on FDA and DF benchmarks demonstrate CMEA's superiority in maintaining diversity while accelerating convergence speed.
Multi-population Estimation of Distribution Algorithm (M-EDA) Applied to multilevel image thresholding, M-EDA employs multiple populations with different initialization strategies and sampling distributions (normal and Cauchy) [104]. The algorithm achieves superior results on the BSDS500 dataset and practical footwear defect detection, winning at four thresholding levels based on Minimum Cross-Entropy.
Dual-Population Cooperative Evolutionary Algorithm (DVA-TPCEA) Targeting large-scale many-objective optimization problems (LaMaOPs), DVA-TPCEA employs quantitative analysis of decision variables and a dual-population cooperative evolution mechanism with convergence and diversity populations [108]. The algorithm demonstrates significant advantages on DTLZ, WFG, and LSMOP test suites, plus practical cloud resource scheduling applications.
Multi-Objective Evolutionary Algorithm with Multi-Population Mechanism (SMEM-NAS) For neural architecture search, SMEM-NAS employs two cooperating populations—a main population guiding evolution and a vice population expanding diversity—to prevent premature convergence [105]. With only 0.17 days of single GPU search time, it discovers competitive architectures achieving 78.91% accuracy on ImageNet.
Quantitative Performance Comparison
Experimental results across studies demonstrate consistent performance advantages for multi-population approaches:
Table 2: Performance Comparison of Multi-Population Algorithms Against Benchmarks
| Algorithm | Comparison Algorithms | Performance Improvement | Statistical Significance | |---------------|||| | CMEA [106] | DNSGA-II, dCOEA, KnEA | Superiority validated on 75% of FDA and DF benchmarks with different change frequencies and severities | p < 0.05 in Wilcoxon signed-rank tests | | M-EDA [104] | LFD, GSA, GBO, HHO, EDA | Best algorithm for optimizing MCE, winning at four thresholding levels | Significant difference in Friedman test (p < 0.05) | | EBJADE [107] | JADE, SHADE, L-SHADE | Strong competitiveness and superior performance in CEC2014 benchmark tests | Ranking based on CEC2014 evaluation criteria | | Cultural Color IGA [109] | Traditional IGA | Reduces user evaluations by 67.4%, improves average fitness by 22.68% | Independent experiments with fuzzy evaluation | | SMEM-NAS [105] | NSGANetV1, MnasNet, MixNet | 78.91% accuracy with MAdds of 570M on ImageNet | Competitive with state-of-the-art NAS methods |
Implementation Guidelines
Workflow and System Architecture
Implementing an effective multi-population evolution system requires careful attention to architectural components and their interactions:
Figure 1: Multi-Population Evolutionary Algorithm Workflow
The Scientist's Toolkit: Essential Research Reagents
Implementing and experimenting with multi-population evolution models requires both computational resources and algorithmic components:
Table 3: Essential Research Reagents for Multi-Population Evolution Research
| Category | Item | Specification | Function/Purpose | |--------------|----------|-------------------|| | Benchmark Suites | FDA/DF benchmarks [106] | Dynamic multiobjective problems with varying change frequency and severity | Algorithm verification in dynamic environments | | | CEC2014 test suite [107] | 30 benchmark functions for real-parameter single objective optimization | Performance comparison and competition | | | MTO benchmark problems [4] | 25 multi-task optimization problems | Verification of cross-task knowledge transfer | | Algorithmic Components | Low-discrepancy sequences [104] | Sobol, Halton, Faure, or Vander Corput sequences | Population initialization for better search space coverage | | | Multiple sampling distributions [104] | Normal (70%) and Cauchy (30%) distributions | Enhanced exploration and exploitation balance | | | Dynamic population update [103] | Seeking and tracking modes with quantum entanglement | Maintaining diversity while improving convergence | | Evaluation Metrics | Hypervolume (HV) [108] | Volume of objective space covered relative to reference point | Convergence and diversity measurement | | | Inverted Generational Distance (IGD) [106] | Distance between true PF and obtained solution set | Convergence to Pareto front | | | Friedman statistical test [104] | Non-parametric multiple comparison test | Algorithm ranking with statistical significance | | Implementation Frameworks | Python-based optimization system [109] | Python 3.9.7 with numerical and visualization libraries | Rapid prototyping and experimental analysis | | | Multi-population MFEA framework [4] | Refactored MFEA with explicit subpopulations | Experimental verification of coincidence relations |
Parameter Configuration and Sensitivity Analysis
Successful implementation requires careful parameter configuration:
- Population Sizing: Subpopulation sizes should balance specialization and diversity; typical sizes range from 50-200 individuals per subpopulation [4]
- Interaction Frequency: Knowledge transfer between populations should occur at controlled intervals (e.g., every 5-20 generations) to prevent premature convergence [102]
- Selection Pressure: Skill factor assignment in MFEA should balance task specialization and knowledge transfer [4]
- Dynamic Parameter Adaptation: Self-adaptive mechanisms for parameters like mutation rates improve robustness across problem types [107]
Sensitivity analysis should systematically vary these parameters to determine their impact on algorithm performance and identify robust configurations for specific problem classes.
Multi-population evolution models represent a significant advancement in evolutionary computation, with rigorously verified performance across diverse application domains. The established coincidence relations between these models and multifactorial evolutionary algorithms provide a theoretical foundation for understanding their behavior and capabilities.
Experimental verification consistently demonstrates that multi-population approaches outperform traditional single-population algorithms in maintaining diversity, accelerating convergence, and solving complex optimization problems with multiple objectives or tasks. The success of algorithms like CMEA, M-EDA, DVA-TPCEA, and SMEM-NAS across domains from image processing to neural architecture search validates the utility of this approach.
For researchers in drug development and other complex scientific domains, multi-population evolution models offer powerful tools for tackling multifaceted optimization challenges. Future research directions include adaptive population sizing, transfer learning between subpopulations, and hybrid models combining the strengths of multiple algorithmic frameworks.
The discovery of a new drug is a fundamentally multi-objective challenge. An ideal candidate must simultaneously exhibit high biological activity against its intended target, possess favourable drug-like properties, and demonstrate minimal toxicity [110] [111]. Traditional drug development, often hampered by high costs and lengthy timelines, has frequently struggled with the complexity of balancing these numerous, often conflicting, objectives [110] [112]. This intricate problem space is the natural domain of multifactorial evolutionary algorithm research, which provides the computational framework for navigating vast chemical landscapes in search of optimal solutions.
A pivotal concept in this multi-objective optimization is Pareto Optimality, which identifies solutions where no single objective can be improved without worsening another [110]. Instead of a single "best" molecule, these algorithms discover a set of non-dominated candidates, known as the Pareto Front, providing researchers with a spectrum of optimal trade-offs [49]. This review explores how state-of-the-art computational methods, particularly those leveraging evolutionary algorithms and AI-driven platforms, are harnessing these principles to evaluate success and accelerate the discovery of novel therapeutic compounds.
Core Principles of Multi-Objective Optimization in Drug Design
The Pareto Principle in Molecular Optimization
In the context of drug design, Pareto Optimality reframes the goal from finding a single superior compound to mapping a frontier of possibilities. A molecule on the Pareto Front is one for which any improvement in one property (e.g., binding affinity) inevitably leads to the deterioration of at least one other critical property (e.g., solubility or synthetic accessibility) [110]. This approach avoids the common pitfall of scalarization methods, which combine multiple objectives into a single weighted score. Scalarization can mask critical deficiencies in some properties and overly restrict the exploration of chemical space [110]. By contrast, Pareto-based methods acknowledge the inherent trade-offs in molecular design and empower medicinal chemists with a diverse set of candidate molecules representing different balanced profiles.
Algorithmic Frameworks for Pareto Optimization
Multifactorial evolutionary algorithm research has produced several powerful algorithms for navigating multi-objective problems. The following table summarizes key algorithms and their applications in drug discovery.
Table 1: Multi-Objective Evolutionary Algorithms in Drug Design
| Algorithm | Core Mechanism | Key Application in Drug Discovery | Notable Features |
|---|---|---|---|
| NSGA-II/III [49] | Fast non-dominated sorting & crowding distance/niche preservation | Optimizing compounds for drug-likeness and synthesizability [49] | Effective for up to ~4 objectives; maintains population diversity |
| MOEA/D [49] | Decomposes multi-objective problem into single-objective subproblems | Molecular generation using SELFIES representations [49] | Computational efficiency on complex problems |
| Pareto Monte Carlo Tree Search (PMMG) [110] | MCTS guided by Pareto dominance to explore SMILES string space | Simultaneous optimization of up to 7 objectives (e.g., activity, solubility, toxicity) [110] | Excels in high-dimensional objective spaces (>4 objectives) |
| Differential Evolution (DE) [113] | Vector operations and random draws for continuous space optimization | Finding optimal experimental designs and conditions in chemometrics [113] | Superior to Genetic Algorithms for continuous, real-valued functions |
Quantitative Success Metrics in Multi-Objective Molecular Generation
Evaluating the performance of generative algorithms requires robust, quantitative metrics that go beyond simple compound quality. The field has coalesced around several key indicators.
Table 2: Key Performance Metrics for Multi-Objective Optimization in Drug Design
| Metric | Description | Interpretation | Exemplary Performance |
|---|---|---|---|
| Hypervolume (HV) [110] | The volume in objective space covered between the Pareto front and a reference point. | A larger HV indicates a better approximation of the true Pareto front, meaning broader and superior coverage of optimal solutions. | PMMG achieved an HV of 0.569, outperforming the best baseline by 31.4% [110]. |
| Success Rate (SR) [110] | The percentage of generated molecules that simultaneously satisfy all predefined objective thresholds. | Measures the algorithm's precision in producing viable candidates against multiple constraints. | PMMG reached a remarkable SR of 51.65% on a 7-objective problem, 2.5x higher than other methods [110]. |
| Diversity (Div) [110] | A measure of the structural or property variation among the generated molecules. | High diversity is crucial to avoid chemical homogeneity and ensure a wide range of scaffolds for downstream testing. | PMMG maintained a high diversity of 0.930, indicating a broad exploration of chemical space [110]. |
Detailed Experimental Protocols in Multifactorial Evolutionary Algorithm Research
Protocol 1: Pareto Monte Carlo Tree Search Molecular Generation (PMMG)
The PMMG algorithm represents a cutting-edge approach for high-dimensional molecular optimization [110].
1. Molecular Representation: The algorithm uses a Recurrent Neural Network (RNN) trained on the Simplified Molecular-Input Line-Entry System (SMILES) representation of molecules. The RNN acts as a generator, predicting the probability distribution of the next token in a SMILES string during the expansion and simulation steps of the tree search [110].
2. Pareto Monte Carlo Tree Search Workflow: The process is iterative, building a search tree through four repeated steps [110]:
- Selection: Traverse the tree from the root node by selecting nodes with the highest Upper Confidence Bound (UCB) score until a leaf node is reached.
- Expansion: Expand the leaf node by adding one or more child nodes, representing the next possible tokens in the SMILES string, as generated by the RNN.
- Simulation: From the new child node(s), simulate a complete rollout to a terminal state (a full SMILES string), again using the RNN to guide the generation.
- Backpropagation: Evaluate the generated molecule(s) against all multi-objective criteria (e.g., bioactivity, QED, SA score, etc.). The results of this evaluation are then propagated back up the path from the simulated node to the root, updating the node statistics and refining the Pareto dominance relationships that guide future searches [110].
3. Objective Function and Normalization: A critical step involves defining and normalizing the objective functions. For a typical project, this might include maximizing biological activity (e.g., EGFR inhibition), solubility, and metabolic stability, while minimizing toxicity and synthetic accessibility (SA score). Given that these properties have different scales, a Gaussian modifier is often applied to normalize all objectives to a consistent range, such as [0,1], ensuring each contributes equally to the optimization process [110].
Protocol 2: Multi-Objective Evolutionary Algorithms with SELFIES
This protocol utilizes evolutionary algorithms with the SELFIES representation to guarantee molecular validity [49].
1. Representation and Initialization: The genotypic representation of molecules uses SELFIES (SELF-referencing Embedded Strings), which ensures that every string of symbols corresponds to a syntactically valid molecular graph. An initial population of molecules (e.g., 200 individuals) is randomly generated from the SELFIES grammar [49].
2. Evolutionary Cycle: The algorithm proceeds through generations, applying genetic operators [49]:
- Evaluation: Each molecule in the population is scored against the multiple objectives (e.g., objectives from the GuacaMol benchmark suite, QED, and SA score).
- Selection: Algorithms like NSGA-II use fast non-dominated sorting to rank individuals into Pareto fronts. Individuals from the best fronts are selected to create a mating pool, with niching techniques (e.g., crowding distance) used to preserve diversity.
- Crossover & Mutation: Selected "parent" molecules are recombined (crossover) and randomly altered (mutation) directly at the SELFIES string level. The key advantage of SELFIES is that these operations always produce valid offspring, eliminating the need for repair functions that are often required with SMILES strings [49].
3. Termination and Analysis: The process runs for a predetermined number of generations (e.g., 30-400). The final Pareto set is analyzed to identify novel, well-balanced compounds, and their internal diversity is assessed to confirm broad exploration of the chemical space [49].
The Scientist's Toolkit: Essential Research Reagents and Computational Solutions
Table 3: Key Research Reagents and Tools for AI-Driven Multi-Objective Drug Discovery
| Tool/Reagent | Type | Primary Function | Application in Workflow |
|---|---|---|---|
| SELFIES [49] | Molecular Representation | Guarantees 100% valid molecular structures from string-based representations. | Used in evolutionary algorithms (e.g., NSGA-II, MOEA/D) to ensure all generated molecules are valid, improving exploration efficiency. |
| Monte Carlo Tree Search (MCTS) [110] | Search Algorithm | Strategically explores a tree of decisions (e.g., SMILES tokens) by balancing exploration and exploitation. | The core of PMMG; guides an RNN through chemical space to find molecules on the Pareto front. |
| ROSETTA [114] | Software Suite | Provides flexible protein-ligand docking with full atomistic flexibility for scoring. | Used in REvoLd to accurately evaluate the binding pose and energy of candidate molecules against a protein target. |
| GuacaMol [49] | Benchmark Suite | Provides a standardized set of tasks and objectives for evaluating generative models. | Serves as a source of multi-objective optimization tasks to fairly compare the performance of different algorithms. |
| Enamine REAL Space [114] | Make-on-Demand Library | A virtual library of billions of readily synthesizable compounds built from robust reactions. | Serves as the constrained chemical search space for algorithms like REvoLd, ensuring high synthetic accessibility. |
| AutoDock Vina [112] | Docking Software | Rapidly predicts how small molecules bind to a protein target. | A common tool for calculating docking scores as a proxy for biological activity in multi-objective workflows. |
Case Study: Dual-Target Inhibitor Design for EGFR and HER2
A illustrative application of these principles is the design of dual-target inhibitors for the EGFR and HER2 kinases, crucial targets in cancers like lung and breast cancer [110]. This case study demonstrates a real-world, multi-objective scenario.
Objective Definition: The optimization involved seven key objectives: maximizing inhibitory activity against both EGFR and HER2, solubility, metabolic stability, and Quantitative Estimate of Drug-likeness (QED); and minimizing toxicity and Synthetic Accessibility Score (SA score) [110].
Methodology and Workflow: The PMMG algorithm was employed for this task. The RNN generator, guided by the Pareto MCTS, explored the SMILES string space. Each generated molecule was virtually screened using predictive models for all seven properties. The MCTS tree used these multi-faceted results to learn which molecular structures (and therefore which branches of the search tree) led to promising, well-balanced candidates.
Outcome: The algorithm successfully identified several candidate compounds with predictive properties that were comparable to or even surpassed those of lapatinib, an established dual EGFR/HER2 inhibitor. This success highlights the potential of Pareto optimization methods to handle complex, real-world drug design challenges involving numerous, competing objectives [110].
The integration of multifactorial evolutionary algorithm research into drug design marks a significant paradigm shift. By moving beyond single-objective optimization and embracing the Pareto principle, these advanced computational methods provide a robust framework for successfully evaluating and achieving a balanced profile in novel drug candidates. The quantitative success of platforms like PMMG, which can efficiently navigate seven or more simultaneous objectives, demonstrates a tangible path toward reducing the high attrition rates that have long plagued the pharmaceutical industry. As AI-driven platforms continue to mature and these methodologies become more refined, the ability to systematically explore the vast chemical space and deliver optimized, novel therapeutics for patients will be fundamentally transformed.
Conclusion
Multifactorial evolutionary algorithms represent a transformative approach to concurrent optimization that leverages implicit parallelism and knowledge transfer between related tasks. By enabling simultaneous optimization of multiple objectives while mitigating negative transfer through adaptive strategies, MFEAs offer significant advantages in computational efficiency and solution quality for complex biomedical problems. The future of MFEA research points toward enhanced theoretical foundations with proven convergence properties, deeper integration with machine learning for transfer prediction, expanded applications in multi-target drug discovery and clinical optimization, and development of more sophisticated constraint-handling mechanisms for real-world biomedical challenges. As these algorithms continue evolving, they hold substantial promise for accelerating drug development pipelines and optimizing complex biological systems through efficient multi-task optimization paradigms.
References
- 1. Multifactorial evolutionary algorithm with adaptive transfer ... [https://link.springer.com/article/10.1007/s40747-023-01105-4]
- 2. Interactive Multifactorial Evolutionary Optimization ... [https://www.mdpi.com/2076-3417/13/4/2243]
- 3. [2003.10768] Multifactorial Cellular Genetic Algorithm (MFCGA) [https://ar5iv.labs.arxiv.org/html/2003.10768]
- 4. Rigorous Analysis of Multi-Factorial Evolutionary Algorithm ... [https://www.atlantis-press.com/journals/ijcis/125919256/view]
- 5. MFEA-RCIM: A Multifactorial for... Evolutionary Algorithm [https://pubmed.ncbi.nlm.nih.gov/40465437/]
- 6. the variants of the traveling salesman problem with time ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10280250/]
- 7. A time-efficient solution approach for multi/many-task reliability... [https://ideas.repec.org/a/eee/reensy/v264y2025ipas095183202500376x.html]
- 8. A Novel Self-Adjusting Dual-Mode Evolutionary Framework for... [https://www.ieee-jas.net/article/doi/10.1109/JAS.2025.125273?viewType=HTML&pageType=en]
- 9. Mutagenic multifactorial based on trait... evolutionary algorithm [https://link.springer.com/article/10.1007/s11431-025-3087-9]
- 10. Rapid and lean multifactorial screening methods for robust ... [https://www.sciencedirect.com/science/article/pii/S2666912921000064]
- 11. Multifactorial differential evolution enhanced by adaptive ... [https://www.sciencedirect.com/science/article/abs/pii/S2210650225003517]
- 12. Cultural transmission based multi-objective evolution ... [https://www.sciencedirect.com/science/article/abs/pii/S0020025521009282]
- 13. Multifactorial Evolutionary Algorithm with Nodedepth ... [https://www.sciencedirect.com/science/article/abs/pii/S0950705125019483]
- 14. -Net: A pixel-adaptive multigrid finite element analysis neural... MFEA [https://asu.elsevierpure.com/en/publications/mfea-net-a-pixel-adaptive-multigrid-finite-element-analysis-neura]
- 15. Evolutionary multitasking with evolutionary trend alignment ... [https://www.sciencedirect.com/science/article/abs/pii/S0957417424031889]
- 16. Residual Learning Inspired Crossover Operator and ... [https://arxiv.org/html/2503.21347v1]
- 17. 2025-2026 Pre-Doctoral Fellows – AFPE [https://afpepharm.org/index.php/2025-2026-pre-doctoral-fellows/]
- 18. Evolutionary Multitask Optimization: Fundamental research ... [https://www.sciencedirect.com/science/article/abs/pii/S2210650222001699]
- 19. A Comprehensive Review of Bio-Inspired Optimization ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10807478/]
- 20. Enhancing evolutionary multitask optimization by ... [https://www.sciencedirect.com/science/article/abs/pii/S095741742503595X]
- 21. A Two-Level Transfer Learning Algorithm for Evolutionary ... [https://www.frontiersin.org/journals/neuroscience/articles/10.3389/fnins.2019.01408/full]
- 22. A multi-objective multi-task evolutionary algorithm based ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494625000432]
- 23. Adaptive archive-based multifactorial evolutionary ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494623004039]
- 24. A multitask optimization algorithm based on elite individual ... [https://www.aimspress.com/article/doi/10.3934/mbe.2023360?viewType=HTML]
- 25. A multifactorial evolutionary algorithm to detect stably ... [https://www.sciencedirect.com/science/article/abs/pii/S221065022500344X]
- 26. Evolutionary Algorithms - an overview | ScienceDirect Topics [https://www.sciencedirect.com/topics/computer-science/evolutionary-algorithms]
- 27. The mechanism of assortative mating for educational attainment [https://pmc.ncbi.nlm.nih.gov/articles/PMC10311485/]
- 28. Behavioral evolution and biocultural games [https://pubmed.ncbi.nlm.nih.gov/2911595/]
- 29. Reconsidering the Heritability of Intelligence in Adulthood [https://link.springer.com/article/10.1007/s10519-011-9507-9]
- 30. Vertical and oblique cultural transmission fluctuating in ... [https://www.sciencedirect.com/science/article/pii/S0040580918301333]
- 31. A data-driven generative strategy to avoid reward hacking ... [https://www.nature.com/articles/s41467-025-57582-3]
- 32. Uncertainty-Aware Multi-Objective Reinforcement Learning ... [https://arxiv.org/html/2510.21153v1]
- 33. Leading AI-Driven Drug Discovery Platforms [https://www.sciencedirect.com/science/article/abs/pii/S0031699725075118]
- 34. Prospective de novo drug design with deep interactome ... [https://www.nature.com/articles/s41467-024-47613-w]
- 35. Top Scientific Data Platforms for AI-Driven Drug Discovery [https://www.collaborativedrug.com/cdd-blog/top-scientific-data-platforms-for-ai-driven-drug-discovery-what-to-look-for]
- 36. Drug Discovery SaaS Platforms Market 2025 Trends and ... [https://www.towardshealthcare.com/insights/drug-discovery-saas-platforms-market-sizing]
- 37. Drug discovery center integrates AI for big impact [https://www.unc.edu/posts/2025/11/24/drug-discovery-center-integrates-ai-for-big-impact/]
- 38. Generative AI for drug discovery and protein design [https://www.sciencedirect.com/science/article/pii/S2590098625000107]
- 39. Recent advances in molecular representation methods and ... [https://www.nature.com/articles/s44386-025-00017-2]
- 40. and Comparing tokenization for enhanced... SMILES SELFIES [https://www.nature.com/articles/s41598-024-76440-8?error=cookies_not_supported&code=64ddb799-fb14-4158-97e4-a72eb7d6963c]
- 41. SELFIES and the future of molecular string representations [https://www.sciencedirect.com/science/article/pii/S2666389922002069]
- 42. EvoMol: a flexible and interpretable evolutionary algorithm for ... [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-020-00458-z]
- 43. Evaluating Effects of Augmented SELFIES for Molecular ... [https://arxiv.org/html/2504.20789v1]
- 44. Domain adaptation of a SMILES chemical transformer to ... [https://www.nature.com/articles/s41598-025-05017-w]
- 45. Going beyond SMILES enumeration for data augmentation in ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00028a]
- 46. Beyond performance: how design choices shape chemical language... [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01099-w]
- 47. A robust optimization model for influence maximization in ... [https://computationalsocialnetworks.springeropen.com/articles/10.1186/s40649-021-00096-x]
- 48. A hybrid evolutionary algorithm for influence maximization in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12606240/]
- 49. Optimized Drug Design using Multi-Objective Evolutionary ... [https://arxiv.org/html/2405.00401v1]
- 50. Multi-and many-objective optimization: present and future ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10773868/]
- 51. Evolutionary design of molecules based on deep learning ... [https://www.nature.com/articles/s41598-021-96812-8]
- 52. Exploring multiobjective evolutionary algorithms for ... [https://www.sciencedirect.com/science/article/pii/S095219762501190X]
- 53. Visual Evolutionary Optimization on Combinatorial ... [https://arxiv.org/html/2505.06850v1]
- 54. A Survey on Multimodal Recommender Systems [https://arxiv.org/html/2502.15711v1]
- 55. Improving conversational recommender systems via multi- ... [https://www.sciencedirect.com/science/article/pii/S0950705123011097]
- 56. Multidimensional Approach To Recommender Systems [https://neo4j.com/graphgists/multidimensional-approach-to-recommender-systems/]
- 57. How to Build an Online Recommendation System [https://www.databricks.com/blog/guide-to-building-online-recommendation-system]
- 58. A Multidimensional Model for Recommendation Systems ... [https://www.mdpi.com/2079-9292/12/2/402]
- 59. Self-adaptive multifactorial evolutionary algorithm for ... [https://www.sciencedirect.com/science/article/abs/pii/S0920410521005611]
- 60. Exploring Decision Tree Machine Vision Systems in 2025 [https://www.unitxlabs.com/resources/decision-tree-machine-vision-system-2025-accuracy-speed/]
- 61. Decision tree-based machine learning methods for ... [https://www.nature.com/articles/s41598-025-17037-7]
- 62. Adaptive incremental transfer learning for efficient ... [https://www.sciencedirect.com/science/article/abs/pii/S0167739X25000251]
- 63. Multifactorial Evolutionary Algorithm Based on Diffusion ... [https://pubmed.ncbi.nlm.nih.gov/37159319/]
- 64. A Group-based Approach to Improve Multifactorial ... [https://www.ijcai.org/proceedings/2018/538]
- 65. Cost-constrained feature selection using gradient boosting ... [https://www.sciencedirect.com/science/article/abs/pii/S0952197625027824]
- 66. A Multiobjective multifactorial optimization algorithm based ... [https://www.sciencedirect.com/science/article/abs/pii/S0020025519309041]
- 67. Improving scale parameters in Successful-history-based ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494625016011]
- 68. An efficient approach for mathematical modeling and ... [https://www.nature.com/articles/s41598-025-10394-3]
- 69. A hybrid simple exponential smoothing-barnacles mating ... [https://www.sciencedirect.com/science/article/pii/S2215016125001931]
- 70. sexual selection and assortative mating estimation software [https://bmcecolevol.biomedcentral.com/articles/10.1186/s12862-025-02394-8]
- 71. What makes evolutionary multi-task optimization better [https://www.sciencedirect.com/science/article/abs/pii/S156849462300563X]
- 72. Evolutionary constrained multi-objective optimization [https://link.springer.com/article/10.1007/s44336-024-00006-5]
- 73. Theoretical and numerical constraint-handling techniques ... [https://www.sciencedirect.com/science/article/pii/S0045782501003231]
- 74. Progressive auto-encoding for domain adaptation in ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494625012293]
- 75. Geometric Moment Alignment for Domain Adaptation via ... [https://arxiv.org/html/2510.14666v1]
- 76. Optimized loss and self attention for enhanced domain ... [https://www.nature.com/articles/s41598-025-24115-3]
- 77. Learning Where, What and How to Transfer [https://arxiv.org/html/2511.15199]
- 78. Knowledge transfer in evolutionary multi-task optimization [https://www.sciencedirect.com/science/article/abs/pii/S1568494623002004]
- 79. A classifier-assisted evolutionary algorithm with knowledge ... [https://link.springer.com/article/10.1007/s40747-025-01908-7]
- 80. A knowledge transfer-based strategy for constrained ... [https://www.sciencedirect.com/science/article/abs/pii/S221065022500269X]
- 81. MGPT: A Multi‐task Graph Prompt Learning Framework for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12442687/]
- 82. Adaptive multi-view learning method for enhanced drug ... [https://www.sciencedirect.com/science/article/pii/S2095177925000929]
- 83. A Survey on Evolutionary Multitask Optimization [https://ojs.istp-press.com/jait/article/view/730]
- 84. [PDF] Benchmark Functions for CEC ' 2017 Competition on ... [https://www.semanticscholar.org/paper/Benchmark-Functions-for-CEC-%E2%80%99-2017-Competition-on-Cheng-Li/1ffe4b1ee324e451da1a5386c3094067e5cd561d]
- 85. 5. Example 5: CEC'2017 Test Suite - neorl - Read the Docs [https://neorl.readthedocs.io/en/latest/examples/ex5.html]
- 86. Enhanced Multi-Strategy Slime Mould Algorithm for Global ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11351541/]
- 87. Evolutionary Computation and Large Language Models [https://arxiv.org/html/2505.15741v1]
- 88. A multi-factor evolutionary algorithm for solving the ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494624002448]
- 89. The Tenth NTIRE 2025 Efficient Super-Resolution ... [https://arxiv.org/html/2504.10686v1]
- 90. A GIN-Guided Multiobjective Evolutionary Algorithm for ... [https://www.mdpi.com/1999-4893/18/10/666]
- 91. KING: An Efficient Optimization Approach [https://www.sciencedirect.com/science/article/abs/pii/S0925231225023173]
- 92. Applications of machine learning in drug discovery and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6552674/]
- 93. Applications of Model-Based Meta-Analysis in Drug ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9314311/]
- 94. Multifactorial Evolutionary Algorithm Based on Diffusion ... [https://ui.adsabs.harvard.edu/abs/2024ITCyb..54.4267L/abstract]
- 95. Evolutionary Stochastic Gradient Descent for Optimization ... [https://arxiv.org/abs/1810.06773]
- 96. A multivariate adaptive gradient algorithm with reduced ... [https://www.sciencedirect.com/science/article/abs/pii/S0893608022001903]
- 97. Evolutionary Gradient Descent for Non-convex Optimization [https://www.ijcai.org/proceedings/2021/443]
- 98. Integrating Conjugate Gradients Into Evolutionary ... [https://www.ieee-jas.net/en/article/id/f95f45b0-ef19-4e1f-a3ee-2fc3e68faa85]
- 99. A gradient-descent-like learning-based framework in ... [https://link.springer.com/article/10.1007/s40747-025-01955-0]
- 100. Molecule discovery and optimization via evolutionary ... [https://www.nature.com/articles/s41598-024-75515-w]
- 101. LEADD: Lamarckian evolutionary algorithm for de novo drug ... [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-022-00582-y]
- 102. Rigorous Analysis of Multi-Factorial Evolutionary Algorithm ... [https://link.springer.com/article/10.2991/ijcis.d.191004.001]
- 103. Multigroup cooperative evolutionary optimization algorithm ... [https://link.springer.com/article/10.1007/s10462-025-11279-7]
- 104. Multi-population estimation of distribution algorithm for ... [https://www.sciencedirect.com/science/article/abs/pii/S092523122500997X]
- 105. A Pairwise Comparison Relation-assisted Multi -objective Evolutionary ... [https://arxiv.org/html/2407.15600v1]
- 106. A Co-evolutionary Multi-population Evolutionary Algorithm ... [https://www.sciencedirect.com/science/article/abs/pii/S221065022400186X]
- 107. A novel differential evolution algorithm with multi-population ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0302207]
- 108. Research on Multi-Objective Evolutionary Algorithms ... [https://www.mdpi.com/2076-3417/14/22/10309]
- 109. Cultural Heritage Color Regeneration: Interactive Genetic ... [https://www.mdpi.com/2076-3417/15/4/1720]
- 110. A Multi‐Objective Molecular Generation Method Based on Pareto ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12120794/]
- 111. Concepts and Challenges in Quantitative Pharmacology ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC2628212/]
- 112. Advancing active compound discovery for novel drug targets [https://www.nature.com/articles/s41401-025-01591-x]
- 113. Using Differential Evolution to Design Optimal Experiments [https://pmc.ncbi.nlm.nih.gov/articles/PMC7088454/]
- 114. Ultra-large library screening with an evolutionary algorithm ... [https://www.nature.com/articles/s42004-025-01758-x]