Genetic Algorithm vs Differential Evolution: A Beginner's Guide for Research and Drug Development
This guide provides a clear, comparative exploration of Genetic Algorithms (GA) and Differential Evolution (DE) for researchers and professionals in drug development and the chemical sciences.
Genetic Algorithm vs Differential Evolution: A Beginner's Guide for Research and Drug Development
Abstract
This guide provides a clear, comparative exploration of Genetic Algorithms (GA) and Differential Evolution (DE) for researchers and professionals in drug development and the chemical sciences. It covers the foundational principles of both evolutionary algorithms, detailing their unique methodologies and operators. The content extends to practical implementation strategies, troubleshooting common issues like premature convergence, and a validation of their performance based on recent scientific benchmarks. By synthesizing theoretical knowledge with application-focused insights, this article serves as a primer for selecting and optimizing these powerful algorithms for complex optimization tasks in biomedical research.
Understanding the Core: Biological Metaphors and Algorithmic Principles
Evolutionary Algorithms (EAs) are a class of population-based, metaheuristic optimization algorithms inspired by the principles of biological evolution, such as natural selection, reproduction, and mutation [1]. They belong to the broader field of computational intelligence and are designed to solve complex optimization problems for which traditional, exact solution methods are ineffective or unknown [1]. By simulating a process of "survival of the fittest," EAs iteratively generate improved solutions to a problem, making them particularly powerful for navigating high-dimensional, non-differentiable, and multimodal search spaces commonly encountered in scientific and engineering disciplines, including drug development [2] [3].
The core principle of an EA is to maintain a population of candidate solutions. Each candidate is evaluated for its "fitness"—a measure of how well it solves the problem. High-fitness candidates are more likely to be selected as parents to produce offspring for the next generation. This reproduction process involves genetic operators like crossover (recombining parts of parent solutions) and mutation (introducing random small changes). Over successive generations, the population evolves toward better regions of the search space [4] [5]. This tutorial provides an in-depth introduction to EAs, with a specific focus on comparing two prominent types: Genetic Algorithms (GAs) and Differential Evolution (DE), framed for beginners and practitioners in research-intensive fields.
The Core Mechanisms of Evolutionary Algorithms
All Evolutionary Algorithms share a common generic structure, though they differ in their specific implementation details [1]. The following diagram illustrates the typical workflow of an EA.
Key Components and Operators
The operation of an EA relies on several key components:
- Population: A set of multiple candidate solutions (individuals). Unlike traditional methods that improve a single solution, the population-based approach allows EAs to explore multiple areas of the search space simultaneously, reducing the risk of becoming trapped in local optima [4].
- Fitness Function: A function that assigns a quality score to each candidate solution based on its performance on the optimization problem. The fitness function guides the search process by determining which solutions are "better" and thus more likely to reproduce [4] [5].
- Selection: The process of choosing parent solutions from the current population based on their fitness. Fit individuals have a higher probability of being selected, mimicking natural selection. Common strategies include tournament selection (selecting the best from a random subset) and roulette wheel selection (probability proportional to fitness) [5].
- Crossover (Recombination): An operator that combines the genetic information of two or more parents to create one or more offspring. This allows the exchange of promising solution features between individuals. A simple example is the one-point crossover, where two binary strings are split at a random point and segments are swapped [4] [5].
- Mutation: An operator that introduces small, random changes to an offspring's genetic representation. Mutation is crucial for maintaining population diversity and exploring new regions of the search space, thereby preventing premature convergence to suboptimal solutions. It typically occurs with a low probability [4] [5].
Table 1: Core Components of an Evolutionary Algorithm
| Component | Description | Role in the Algorithm |
|---|---|---|
| Population | A collection of candidate solutions (individuals). | Enables parallel exploration of the search space. |
| Fitness Function | A problem-specific function measuring solution quality. | Guides the search by selecting the fittest individuals. |
| Selection | Process for choosing parents based on fitness. | Promotes the propagation of good genetic material. |
| Crossover | Operator combining parts of two or more parents. | Exploits and recombines existing good solutions. |
| Mutation | Operator introducing random changes to an offspring. | Explores new areas and maintains population diversity. |
A Deep Dive into Genetic Algorithms (GAs)
Genetic Algorithms (GAs), developed by John Holland and his colleagues in the 1970s, are one of the most popular and historically significant types of Evolutionary Algorithms [5]. They closely adhere to the metaphor of genetic reproduction, where solutions are encoded as chromosomes composed of genes [6].
Representation and Operators in GAs
In the canonical GA, solutions are represented using a fixed-length encoding, traditionally binary strings, though integer and real-valued representations are also common depending on the problem [6] [4]. For example, in a knapsack problem, a binary chromosome might represent whether an item is included (1) or not (0) [4].
The power of a GA comes from its genetic operators:
- Crossover: This is the primary search operator in GA. It creates new offspring by recombining genetic material from two parents. Methods include one-point, two-point, and uniform crossover [4].
- Mutation: This is a secondary operator that acts as a background operator. It randomly alters one or more gene values in a chromosome (e.g., flipping a bit in a binary string) to introduce novelty [5].
Experimental Protocol: Implementing a Simple GA
The following Python pseudocode outlines the basic structure of a Genetic Algorithm, which can be applied to problems like feature selection or parameter tuning [4] [5].
Table 2: Key "Reagent Solutions" for a Genetic Algorithm Experiment
| Reagent (Component) | Function | Example / Notes |
|---|---|---|
| Population | The set of candidate solutions to be evolved. | Initialized randomly or using a heuristic. Size is critical for diversity. |
| Fitness Function | Defines the objective and measures solution quality. | Must be carefully designed to accurately reflect the problem's goals. |
| Selection Operator | Guides the search by selecting fitter parents. | Tournament or Roulette Wheel selection are common choices. |
| Crossover Operator | Recombines parents to create new offspring. | One-point or uniform crossover for binary representations. |
| Mutation Operator | Introduces diversity and prevents premature convergence. | Bit-flip for binary, Gaussian noise for real-valued representations. |
A Deep Dive into Differential Evolution (DE)
Differential Evolution (DE), introduced by Storn and Price in 1997, is a powerful EA specifically designed for optimizing real-valued functions in continuous search spaces [2] [3]. While it shares the common EA framework of population, mutation, crossover, and selection, its mutation strategy is unique and gives the algorithm its name.
The Distinctive Mutation Strategy of DE
The key differentiator of DE is how it performs mutation. Instead of relying on a probability distribution, DE generates a mutant vector for each individual in the population (called the target vector) by adding a scaled difference between two or more randomly selected population vectors to a third base vector [2] [3]. The most common mutation strategy, "DE/rand/1/bin", is mathematically expressed as:
$$ \text{mutationvector} = x{r1} + F \cdot (x{r2} - x{r3}) $$
Here, $x{r1}$, $x{r2}$, and $x{r3}$ are three distinct randomly chosen population vectors, and $F$ is a scaling factor that controls the amplification of the differential variation $(x{r2} - x_{r3})$ [2] [3]. This use of vector differences allows DE to automatically adapt the step size and orientation of the search based on the current distribution of the population.
Crossover and Selection in DE
After mutation, a crossover operation is performed between the mutant vector and the original target vector to create a trial vector. This is typically binomial crossover, where each parameter of the trial vector is inherited either from the mutant vector or the target vector with a certain probability, controlled by the crossover rate ($Cr$) [2]. Finally, a greedy selection occurs: the trial vector replaces the target vector in the next generation only if it has a better or equal fitness [2] [3]. The following diagram visualizes the core process of creating a new candidate in DE.
Experimental Protocol: Implementing a Simple DE
The following Python pseudocode implements the "DE/rand/1/bin" strategy, which is the classic and one of the most widely used variants of Differential Evolution [2] [3].
Table 3: Key "Reagent Solutions" for a Differential Evolution Experiment
| Reagent (Component) | Function | Example / Notes |
|---|---|---|
| Population (Vectors) | Set of real-valued candidate solutions. | Each individual is a vector in a continuous space. |
| Scaling Factor (F) | Controls the amplification of differential variation. | Typically in [0, 2]. A smaller F promotes convergence. |
| Crossover Rate (Cr) | Controls the mixing of mutant and target vectors. | Typically in [0, 1]. A higher Cr exploits the mutant more. |
| Mutation Strategy | Defines how the mutant vector is created. | "DE/rand/1" uses random base vector and one difference. |
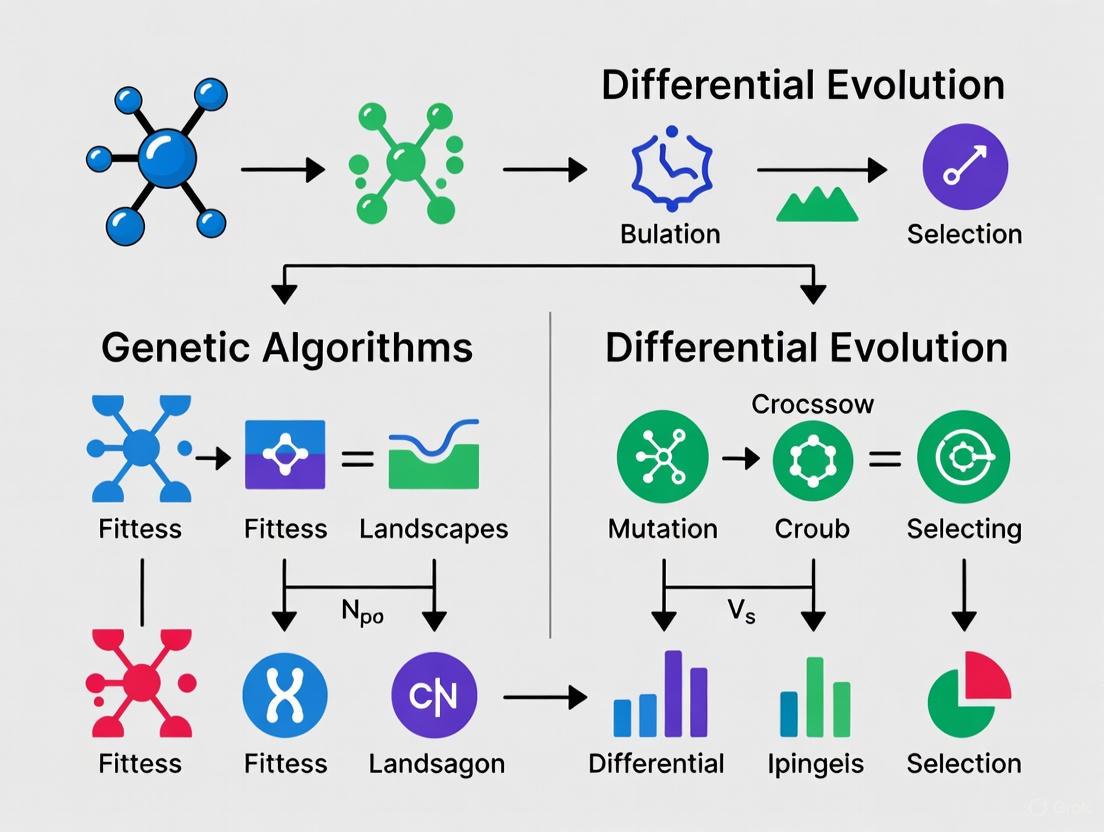
Comparative Analysis: Genetic Algorithms vs. Differential Evolution
Understanding the differences between GAs and DE is crucial for selecting the right tool for a given optimization problem. The table below summarizes their key distinctions.
Table 4: A Comparative Summary of Genetic Algorithms (GAs) and Differential Evolution (DE)
| Feature | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Primary Metaphor | Genetic reproduction (chromosomes, genes) [6]. | Directional information and vector differences [3]. |
| Representation | Traditionally binary strings, but other encodings are possible [4]. | Primarily real-valued vectors [6] [2]. |
| Core Search Driver | Crossover is the primary, disruptive search operator [4]. | Mutation based on vector differences is the primary driver [3]. |
| Key Parameters | Population size, crossover probability, mutation probability [5]. | Population size, scaling factor (F), crossover rate (Cr) [2]. |
| Operator Sequence | Selection → Crossover → Mutation [5]. | Mutation → Crossover → Selection [7]. |
| Typical Application Scope | Well-suited for discrete and combinatorial problems (e.g., scheduling) [4]. | Excels in continuous, numerical optimization (e.g., function fitting) [6] [2]. |
| Strengths | Easily parallelizable, good for escaping local optima in combinatorial spaces [4]. | Fewer control parameters, often more effective/efficient for continuous problems [6] [2]. |
Guidance for Algorithm Selection
The choice between GA and DE depends heavily on the nature of the problem:
- Use Genetic Algorithms when dealing with discrete or combinatorial optimization problems, such as the traveling salesman problem, feature selection, or scheduling [4]. Their representation and crossover operators are naturally suited for these domains.
- Use Differential Evolution when the problem involves optimization in a continuous, real-valued parameter space, especially if the function is non-differentiable, nonlinear, or multimodal [2] [3]. DE's ability to use directional information from the population often leads to faster and more robust convergence on such problems [6].
- Consider DE's simplicity: DE requires very few control parameters to steer the minimization (typically just F and Cr), which makes it easier and more practical to use for many real-world applications [2].
Advanced Concepts and Current Trends
Theoretical Foundations
Two fundamental theoretical concepts provide context for understanding EAs:
- The No Free Lunch Theorem: This theorem states that all optimization algorithms are equally effective when averaged over all possible problems [1]. This means there is no single EA that is universally best. The strong performance of GAs and DE on specific problem classes is precisely because they exploit the structure of those problems. Therefore, problem-specific knowledge should be incorporated into the EA design (e.g., in the representation or fitness function) for best results [1].
- Convergence: For EAs that employ elitism (always keeping the best solution found so far), it is possible to prove that the algorithm will converge to the global optimum, given infinite time [1]. However, this proof does not specify the speed of convergence, which is a key practical concern.
Variants and Recent Developments
The fields of GA and DE are actively evolving. Numerous advanced variants have been developed to enhance performance:
- DE Strategy Variants: There are multiple strategies for creating the mutant vector in DE, following a naming convention of DE/x/y/z [2] [7]. For example, DE/best/1/bin uses the best solution in the population as the base vector, promoting faster convergence (though with a higher risk of getting stuck in a local optimum), while DE/rand/1/bin uses a random base vector, favoring exploration [2].
- Self-Adaptation: Advanced versions of DE and ES can self-adapt their parameters (like F and Cr) during the run, freeing the user from the burden of finding robust static parameter values [7].
- Hybrid Algorithms (Memetic Algorithms): EAs are often hybridized with local search techniques to refine solutions. These hybrids are known as Memetic Algorithms and often demonstrate superior performance by combining the global exploration of EA with the local exploitation of a dedicated local search method [1].
Evolutionary Algorithms, particularly Genetic Algorithms and Differential Evolution, provide powerful and flexible frameworks for solving complex optimization problems that are intractable for traditional methods. GAs, with their strong biological metaphor and suitability for combinatorial problems, and DE, with its unique differential mutation strategy for continuous spaces, are two cornerstone techniques in this domain.
The key takeaway is that algorithm selection is problem-dependent. For researchers and scientists in fields like drug development, where problems can range from discrete molecular design (potentially suited for GAs) to continuous parameter tuning in pharmacokinetic models (potentially suited for DE), understanding the core mechanisms, strengths, and weaknesses of each algorithm is the first step toward harnessing their power. By following the structured methodologies and experimental protocols outlined in this guide, practitioners can effectively apply these population-based optimizers to push the boundaries of their research.
The Genetic Algorithm (GA) is a powerful metaheuristic optimization algorithm inspired by the principles of Darwin's theory of natural selection [8]. As a problem-independent optimization method, GA belongs to a broader class of evolutionary computing algorithms designed to find solutions to NP-hard problems where traditional methods struggle with the exponential growth of possible solutions [8]. By modeling the evolutionary processes of selection, inheritance, and genetic variation, GAs can efficiently explore complex solution spaces to find near-optimal solutions for a wide range of optimization challenges. The fundamental analogy draws parallels between biological evolution and computational optimization: cells operate similarly to Turing machines, with genetic programs providing the operational blueprint [8]. This biological foundation enables GAs to tackle complex optimization problems across diverse fields, from computational biology to drug development.
Core Components and Operational Mechanics
Foundational Elements and Workflow
The genetic algorithm operates through an iterative process that mimics natural evolution, requiring only two essential components: a population of candidate solutions and a fitness function to evaluate them [8]. The algorithm creates conditions of natural selection where individuals with advantageous traits are more likely to survive and reproduce, progressively improving the population's overall fitness across generations [8]. This process incorporates the key biological principles of fitness, inheritance, and natural variation through recombination and mutation [8].
Table 1: Core Components of a Genetic Algorithm
| Component | Description | Biological Analogy |
|---|---|---|
| Population | Set of candidate solutions (genes, chromosomes) | Population of organisms in an ecosystem |
| Fitness Function | Function that quantifies solution quality | Environmental selection pressures |
| Selection | Process choosing individuals for reproduction | Natural selection based on fitness |
| Crossover | Combining genetic material from two parents | Sexual reproduction and recombination |
| Mutation | Random alterations to genetic material | Genetic mutations introducing variation |
The GA workflow follows a generational approach that begins with population initialization and proceeds through repeated cycles of fitness evaluation, selection, and genetic operations until termination conditions are met. The initial population, or first generation (F1), consists of a set of genes, chromosomes, or other units of interest, commonly represented as bit arrays where different permutations of 0s and 1s represent different genes [8]. Through successive generations, the algorithm preserves and combines beneficial traits while introducing controlled variations, creating an evolutionary trajectory toward improved solutions.
Detailed Operational Workflow
The genetic algorithm implements a structured workflow that transforms an initial population of candidate solutions through successive generations:
Population Initialization: The algorithm begins by creating an initial population of candidate solutions, typically represented as binary strings, real-valued vectors, or other appropriate data structures. For a binary representation, different permutations of 0s and 1s represent different genes or chromosomes [8]. The population size is a critical parameter that affects both diversity and computational efficiency, with larger populations providing more genetic diversity but requiring more computational resources per generation.
Fitness Evaluation: Each candidate solution in the population is evaluated using a problem-specific fitness function that quantifies how well it solves the target problem. The fitness function serves as the environmental pressure in the evolutionary process, assigning higher values to better solutions. In a common approach, beneficial traits might be represented by 1s and neutral traits by 0s, with the fitness score equivalent to the sum of these binary values [8]. The design of an effective fitness function is crucial, as it directly guides the evolutionary process toward desired solutions.
Selection Operation: The selection process mimics natural selection by choosing which individuals from the current population will contribute genetic material to the next generation. Individuals with higher fitness scores have a greater probability of being selected, similar to how organisms with advantageous traits are more likely to survive and reproduce in nature [8]. However, most implementations also preserve a small proportion of less-fit individuals to maintain genetic diversity and prevent premature convergence.
Genetic Operators: The crossover (recombination) operator combines genetic information from two parent solutions to create offspring. In a simple single-point crossover, a random point is selected along the parent chromosomes, and segments are exchanged to create new offspring [8]. The mutation operator introduces random changes by altering small portions of the genetic material, such as flipping bits in a binary representation with a low probability [8]. These operators balance the exploitation of good solutions with the exploration of new possibilities in the search space.
Termination Check: The algorithm iteratively repeats the evaluation-selection-variation cycle until a termination condition is met. Common termination criteria include reaching a predetermined number of generations, achieving a satisfactory fitness level, or detecting population convergence where successive generations no longer produce significant improvements [9].
Advanced Modifications and Specialized Variants
Enhanced GA Variants for Complex Problems
Basic genetic algorithms can be enhanced with specialized techniques to address specific challenges and improve performance across diverse problem domains:
Elitism: This commonly used approach ensures that the best solutions are preserved unchanged across generations by automatically carrying the highest-fitness individuals from one generation to the next [8]. Elitism guarantees that solution quality never decreases between generations and prevents the loss of valuable genetic information [8]. By maintaining the best performers without modification, elitism accelerates convergence while ensuring monotonic improvement in solution quality.
Speciation: Speciation heuristics discourage crossover between highly similar individuals, promoting genetic diversity within the population [8]. Without speciation, populations often suffer from premature convergence where suboptimal solutions dominate early in the evolutionary process [8]. By encouraging mating between diverse individuals, speciation maintains a broader exploration of the solution space and helps escape local optima.
Adaptive Genetic Algorithms (AGAs): These self-tuning variants dynamically adjust mutation and crossover rates throughout the evolutionary process to maintain population diversity while preserving convergence properties [8]. Though computationally more expensive, AGAs often produce more realistic and robust results, particularly for problems with complex fitness landscapes [8]. Research has demonstrated that AGAs offer "the highest accuracy and the best performance on most unimodal and multimodal test functions" compared to other optimization approaches [8].
Interactive Genetic Algorithms (IGAs): When fitness cannot be quantitatively defined, IGAs incorporate human judgment into the selection process by having users evaluate candidate solutions subjectively [8]. While valuable for domains like fashion design or creative arts, IGAs face scalability challenges due to human fatigue and introduce subjective biases [8]. The interactive approach shifts the fitness computation burden to users but enables optimization in domains with qualitative evaluation criteria.
Table 2: Advanced GA Variants and Their Applications
| Variant | Key Mechanism | Advantages | Typical Applications |
|---|---|---|---|
| Elitist GA | Preserves best solutions unchanged | Prevents loss of good solutions; Monotonic improvement | General optimization; Engineering design |
| Speciated GA | Restricts mating between similar individuals | Maintains diversity; Prevents premature convergence | Multimodal optimization; Neural network training |
| Adaptive GA | Dynamically adjusts genetic parameters | Self-tuning; Robust performance | Complex landscapes; Real-world problems |
| Interactive GA | Incorporates human evaluation | Handles qualitative fitness criteria | Creative design; Subjective optimization |
Genetic Algorithm vs. Differential Evolution: A Comparative Analysis
Fundamental Differences and Performance Comparisons
While both belonging to the broader class of evolutionary algorithms, Genetic Algorithms and Differential Evolution (DE) exhibit distinct characteristics that make them suitable for different problem types. DE has gained recognition as a powerful alternative to GAs, particularly for continuous optimization problems [10].
Representation and Operation: The primary difference between GAs and DE lies in their representation and search mechanisms. GAs traditionally operate on discrete representations, often using binary encoding, while DE is designed specifically for continuous parameter spaces [10]. DE employs straightforward vector operations rather than the crossover and mutation mechanisms typical of GAs, creating new candidate solutions by adding the weighted difference between two population vectors to a third vector [2].
Performance Characteristics: Experimental comparisons between GAs and DE have demonstrated DE's superiority in many numerical optimization scenarios. One comprehensive study comparing state-of-the-art multiobjective algorithms found that "on the majority of problems, the algorithms based on differential evolution perform significantly better than the corresponding genetic algorithms with regard to applied quality indicators" [11]. This suggests that DE explores the decision space more efficiently than GAs for numerical multiobjective optimization [11]. However, GAs maintain advantages for problems with discrete or mixed variable types and in domains where their representation more naturally matches the problem structure.
Parameter Sensitivity and Control: DE requires fewer control parameters than most GA variants, typically needing only three parameters: population size, mutation scale factor, and crossover rate [2]. This makes DE easier to implement and tune for practitioners [2]. The canonical DE has been shown to work well for complex problems, including solving multi-objective problems, finding clustering weights, and training neural networks [10].
Table 3: Genetic Algorithm vs. Differential Evolution Comparison
| Characteristic | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Search Space | Primarily discrete | Continuous |
| Core Operations | Selection, crossover, mutation | Vector addition, subtraction |
| Parameter Count | More parameters required | Fewer parameters (typically 3) |
| Convergence | May be slower on numerical problems | Faster convergence for continuous spaces |
| Exploration Mechanism | Probability-based mutation | Directional information via difference vectors |
| Implementation Complexity | Moderate | Simple vector operations |
Mutation and Crossover Strategies
The mutation and crossover mechanisms represent a fundamental distinction between GAs and DE. In GAs, mutation typically occurs through random alterations based on probability distributions, such as bit flips in binary representations [8]. In contrast, DE mutation utilizes directional information from the population by calculating weighted differences between solution vectors [7]. This difference-based approach allows DE to efficiently adapt step sizes and directions according to the distribution of solutions in the search space.
Crossover also differs significantly between the two approaches. In GAs, crossover typically occurs at defined points in the chromosome, exchanging segments between parent solutions [8]. DE employs a more granular approach where each variable undergoes independent crossover decisions, increasing diversity in the offspring generation [7]. Additionally, DE performs mutation before crossover, reversing the traditional order used in most GA implementations [7].
Experimental Protocols and Research Applications
Implementation Framework and Research Reagents
Implementing genetic algorithms for research requires both computational frameworks and problem-specific components that serve as the "research reagents" for experimental optimization:
Table 4: Essential Research Reagents for Genetic Algorithm Experiments
| Reagent | Function | Implementation Example |
|---|---|---|
| Population Initialization | Generates initial candidate solutions | Random sampling from defined search space |
| Fitness Function | Evaluates solution quality | Problem-specific objective function |
| Selection Operator | Chooses parents for reproduction | Tournament selection, roulette wheel |
| Crossover Operator | Combines parent solutions | Single-point, multi-point, uniform crossover |
| Mutation Operator | Introduces genetic diversity | Bit flip, random reset, swap mutation |
| Termination Criterion | Determines algorithm completion | Generation count, fitness threshold, convergence |
Experimental Protocol for Phylogenetic Tree Construction: One significant biological application of GAs involves constructing phylogenetic trees from evolutionary data. The Hill et al. team applied GAs to this challenging combinatorial problem where the number of possible trees grows exponentially with taxa [8]. Their implementation followed this methodology:
Representation: Encode potential phylogenetic trees as chromosomes, with each gene representing a topological feature or branch arrangement.
Fitness Evaluation: Calculate tree fitness based on maximum parsimony or maximum likelihood criteria, measuring how well the tree explains the observed biological sequences.
Genetic Operations: Apply specialized crossover operators that combine subtree elements from parent trees and mutation operators that rearrange branches or alter topological features.
Performance: Their Phanto program demonstrated that GAs could "infer the phylogeny of 92 taxa with 533 amino acids, including gaps in a little over half an hour using a regular desktop PC" [8].
Experimental Protocol for Protein Folding Prediction: The Wong et al. team applied GAs to the protein folding prediction problem using the HP Lattice model (Hydrophobic-Polar Lattice) to simplify protein structures [8]. Their approach:
Representation: Encode protein conformations as chromosomes representing the spatial arrangement of amino acids.
Fitness Function: Define fitness as the negative of the energy required to fold the protein into that shape, implementing the HP model to capture hydrophobicity interactions between amino acid residues.
Optimization: Use the iterative nature of GAs to find configurations that minimize the folding energy, exploring the vast conformational space efficiently.
Chemical and Pharmaceutical Applications
Genetic algorithms have demonstrated significant utility in chemical optimization and drug development, where they help navigate complex experimental parameter spaces. The recently developed Paddy algorithm, an evolutionary approach inspired by plant reproduction behavior, has shown robust performance across various chemical optimization tasks [9]. In benchmark studies comparing multiple optimization approaches, evolutionary methods like Paddy demonstrated "robust versatility by maintaining strong performance across all optimization benchmarks" [9].
Chemical optimization applications typically follow this experimental protocol:
Parameter Encoding: Represent experimental conditions (temperature, concentration, pH, etc.) as chromosomes with each gene corresponding to a specific parameter.
Fitness Evaluation: Measure experimental outcomes (reaction yield, purity, biological activity) quantitatively as fitness scores.
Iterative Optimization: Evolve experimental conditions across generations, with high-performing parameter sets receiving greater representation in subsequent experimental rounds.
Validation: Confirm optimized conditions through replication and out-of-sample testing to prevent overfitting to specific experimental conditions.
This approach has been successfully applied to diverse chemical challenges including synthetic methodology development, chromatography condition optimization, catalyst design, and drug formulation [9]. The ability of GAs to efficiently explore high-dimensional parameter spaces makes them particularly valuable for complex chemical systems where traditional one-variable-at-a-time approaches are impractical.
Genetic Algorithms provide a powerful and biologically-inspired methodology for solving complex optimization problems across diverse domains. Their representation of candidate solutions as evolving populations subject to selection pressures enables efficient exploration of challenging search spaces. For researchers and drug development professionals, GAs offer particular value for problems with discrete variables, complex constraints, or where the problem structure naturally aligns with chromosomal representations.
The choice between Genetic Algorithms and Differential Evolution should be guided by problem characteristics and research objectives. DE generally outperforms GA for continuous numerical optimization, particularly when leveraging its efficient vector operations and directional search capabilities [11]. However, GAs maintain advantages for discrete optimization, problems requiring specialized representations, and domains where their operators can be customized to incorporate domain knowledge. Emerging evolutionary approaches like the Paddy algorithm demonstrate continued innovation in this field, combining elements from both paradigms to address complex chemical optimization challenges [9].
As optimization needs evolve with increasing problem complexity and data availability, both Genetic Algorithms and Differential Evolution will continue to serve as valuable tools in the researcher's toolkit. Understanding their complementary strengths enables practitioners to select the most appropriate approach for their specific optimization challenges, whether in computational biology, drug development, or other scientific domains requiring robust optimization methodologies.
Differential Evolution (DE) is a powerful evolutionary algorithm (EA) first introduced by Rainer Storn and Kenneth Price in the mid-1990s for optimizing problems defined over continuous domains [12]. As a population-based metaheuristic, DE belongs to the broader class of evolutionary computation but distinguishes itself through a unique differential mutation strategy that efficiently explores complex search spaces [13] [14]. Unlike traditional genetic algorithms (GAs) that were originally designed for discrete spaces and rely heavily on crossover operations, DE operates directly on real-valued vectors using vector differences to drive the mutation process, making it particularly effective for numerical optimization problems [10] [11].
The fundamental distinction between DE and GA lies in their approach to candidate improvement. While GAs typically use genotype representations (often binary or integer strings) and apply crossover as the primary search operator, DE utilizes a differential mutation strategy that calculates weighted differences between population vectors to create new trial vectors [6] [12]. This approach enables DE to automatically adapt the step size and orientation of its search based on the current population distribution, allowing for more effective navigation of complex fitness landscapes, especially in continuous domains [11] [15]. For researchers and drug development professionals, this translates to superior performance in optimizing complex, multimodal objective functions commonly encountered in chemometrics, molecular modeling, and binding affinity prediction [16] [10].
Core Algorithmic Mechanics
Fundamental Operations and Workflow
DE maintains a population of candidate solutions, referred to as agents or vectors, which evolve over generations through the sequential application of mutation, crossover, and selection operations [13] [12]. The algorithm treats the optimization problem as a black box, requiring only the ability to evaluate candidate solutions against a fitness function, without needing gradient information [13]. This property makes DE particularly valuable for optimizing non-differentiable, noisy, or otherwise irregular functions common in scientific applications [10] [15].
The complete DE workflow integrates these core operations into an iterative process that progressively refines the population toward optimal solutions. This systematic procedure enables DE to efficiently balance exploration of the search space with exploitation of promising regions.
Figure 1: Differential Evolution Algorithm Workflow. The process iterates through mutation, crossover, and selection operations until termination criteria are met.
Mutation: The Differential Advantage
The mutation operation constitutes DE's distinctive feature, employing vector differences to explore the search space [13]. For each target vector in the population, a donor vector is created by perturbing a base vector with the scaled difference of two other randomly selected population vectors [10]. The most common mutation strategy, known as DE/rand/1, follows this formula:
Donor Vector = Xᵣ₀ + F × (Xᵣ₁ - Xᵣ₂)
where Xᵣ₀, Xᵣ₁, and Xᵣ₂ are three distinct randomly selected vectors from the population, and F is the mutation scale factor typically chosen from the range [0, 2] [13] [10]. The differential component (Xᵣ₁ - Xᵣ₂) enables the algorithm to automatically adapt step sizes based on the distribution of solutions in the current population [15]. This self-adjusting mechanism allows DE to perform large jumps in early generations when the population is dispersed, and finer adjustments as the population converges toward promising regions [6].
Crossover: Incorporating Genetic Diversity
Following mutation, DE employs a crossover operation to increase population diversity by combining components of the donor vector with the target vector [12]. The most common approach is binomial crossover, which constructs a trial vector by selecting elements from either the donor or target vector based on a crossover probability (CR) parameter [13] [10]. The crossover operation ensures that at least one dimension is inherited from the donor vector while preserving some genetic material from the target vector, maintaining a balance between exploration and exploitation [15].
Selection: Greedy Survival Competition
DE implements a straightforward yet effective selection mechanism where each trial vector competes directly against its corresponding target vector [10]. If the trial vector demonstrates superior or equal fitness compared to the target vector, it replaces the target in the next generation; otherwise, the target vector survives [12]. This greedy selection strategy ensures monotonic improvement in population fitness while preserving diversity through the simultaneous evaluation of all candidate solutions [13].
DE vs. Genetic Algorithms: A Comparative Analysis
While both DE and Genetic Algorithms belong to the broader evolutionary computation family, they differ significantly in their representation, operations, and performance characteristics [6] [11]. Understanding these distinctions is crucial for selecting the appropriate algorithm for specific optimization challenges.
Table 1: Differential Evolution vs. Genetic Algorithms Comparison
| Characteristic | Differential Evolution | Genetic Algorithms |
|---|---|---|
| Representation | Real-valued vectors [12] | Typically binary or integer strings [12] |
| Primary Search Operator | Differential mutation [6] | Crossover/recombination [6] |
| Mutation Strategy | Uses vector differences [13] | Typically bit-flips or random perturbations [6] |
| Parameter Adaptation | Self-adapting step sizes through vector differences [15] | Fixed mutation rates [6] |
| Convergence Speed | Generally faster for continuous problems [11] | Slower for continuous, high-dimensional problems [11] |
| Typical Applications | Continuous parameter optimization, chemometrics, engineering design [10] | Discrete/combinatorial optimization, scheduling [10] |
Experimental studies have demonstrated DE's superiority over GAs for many numerical optimization problems. Research comparing multiobjective variants showed that "on the majority of problems, the algorithms based on differential evolution perform significantly better than the corresponding genetic algorithms with regard to applied quality indicators" [11]. This performance advantage stems from DE's ability to automatically adapt its search step size based on population distribution, whereas GAs typically rely on fixed mutation rates that require careful tuning [6].
Implementation Guidelines
Parameter Configuration
DE performance depends critically on appropriate parameter selection. The three primary control parameters—population size (NP), mutation factor (F), and crossover rate (CR)—should be chosen based on problem characteristics [13] [10].
Table 2: DE Parameter Settings and Guidelines
| Parameter | Symbol | Typical Range | Recommended Starting Value | Impact |
|---|---|---|---|---|
| Population Size | NP | [5×D, 10×D] where D is dimension [10] | 10×D [13] | Larger values increase diversity but slow convergence |
| Mutation Factor | F | [0.4, 1.0] [15] | 0.8 [13] | Lower values emphasize exploitation, higher values exploration |
| Crossover Rate | CR | [0.7, 0.95] for non-separable problems [15] | 0.9 [13] | Higher values preserve more donor vector information |
For problems with strong multimodality or periodic terms, lower CR values (0.2-0.5) may produce better results by promoting search along coordinate axes [15]. The mutation factor F can also be dynamically adjusted using dithering, which randomizes F within a specified range (e.g., [0.3, 1.0]) for each mutant vector to enhance exploration [15].
Constraint Handling
DE originally designed for unconstrained optimization can be extended to constrained problems through penalty methods, where the objective function is modified to include a penalty term for constraint violations: f̃(x) = f(x) + ρ×CV(x), where CV(x) measures the constraint violation and ρ is a penalty coefficient [13]. Alternative approaches include projecting infeasible solutions onto the feasible set or using specialized repair operations [10].
Advanced DE Variants and Recent Advances
The success of basic DE has spurred development of numerous enhanced variants targeting specific problem classes and performance limitations [14] [17]. For multimodal optimization problems (MMOPs) where identifying multiple optimal solutions is valuable, DE has been integrated with niching techniques that maintain subpopulations around different optima [17]. These approaches enable DE to locate and maintain multiple global and local optima in a single run, providing decision-makers with alternative solutions for scenarios where practical constraints may preclude implementing the theoretical global optimum [17].
Recent advancements include:
- Adaptive DE variants that dynamically adjust control parameters F and CR based on performance feedback [14]
- Hybrid DE algorithms that combine DE with local search techniques (memetic algorithms) or machine learning models for improved exploitation [17]
- Multi-objective DE for problems with competing objectives using Pareto-based selection [11]
- DE with surrogate models that reduce computational cost for expensive objective functions [14]
Application in Drug Discovery and Development
DE has demonstrated significant utility in drug discovery, particularly in predicting drug-target interactions (DTIs) and binding affinities—critical tasks for drug repositioning and discovery [16]. Traditional experimental approaches for investigating DTIs are time-consuming and require substantial financial resources, making computational approaches highly valuable [16].
In a recent implementation, researchers proposed a deep learning approach for predicting binding affinities between drugs and targets using a Convolution Self-Attention Network with Attention-based Bidirectional Long Short-Term Memory Network (CSAN-BiLSTM-Att) [16]. Due to the model's complexity, proper hyperparameter tuning was essential, for which DE was employed to select optimal hyperparameters [16]. The DE-optimized model achieved a concordance index of 0.898 and a mean square error of 0.228 on the DAVIS dataset, and 0.971 concordance with 0.014 mean square error on the KIBA dataset, outperforming previous approaches [16].
Table 3: Experimental Results of DE-Optimized Model for Drug-Target Binding Affinity Prediction
| Dataset | Concordance Index (CI) | Mean Square Error (MSE) | Performance Context |
|---|---|---|---|
| DAVIS | 0.898 | 0.228 | Outperformed previous approaches [16] |
| KIBA | 0.971 | 0.014 | Superior to existing methods [16] |
The experimental workflow for this application illustrates DE's role in optimizing complex computational models:
Figure 2: Drug-Target Binding Affinity Prediction Using DE Optimization. DE efficiently tunes hyperparameters in complex deep learning models for drug discovery applications.
Experimental Protocols and Research Reagents
Computational Research Toolkit
Implementing DE for optimization problems requires specific computational tools and parameters. The following table details key components of the DE research toolkit:
Table 4: Differential Evolution Research Reagent Solutions
| Component | Type/Value | Function/Purpose |
|---|---|---|
| Population Size | 5×D to 10×D (D = dimensions) | Maintains genetic diversity while balancing computational cost [10] |
| Mutation Scheme | DE/rand/1 or DE/best/1 | Determines how donor vectors are created [13] |
| Mutation Factor (F) | 0.4-1.0 | Controls amplification of differential variation [15] |
| Crossover Rate (CR) | 0.7-0.9 for non-separable problems | Controls inheritance from donor versus target vector [15] |
| Termination Criteria | Maximum generations or fitness threshold | Determines when optimization process stops [12] |
| Constraint Handling | Penalty functions or projection methods | Manages feasible solution search spaces [13] |
Benchmarking Protocol
To validate DE performance against alternative optimizers like Genetic Algorithms, follow this experimental protocol:
Problem Selection: Choose benchmark problems with varying characteristics (unimodal, multimodal, separable, non-separable) and real-world applications like drug-target binding affinity prediction [16] [11]
Algorithm Configuration:
- Implement DE with population size NP = 10×D, F = 0.8, CR = 0.9
- Implement GA with comparable population size, binary tournament selection, simulated binary crossover, and polynomial mutation [11]
Performance Metrics:
- Record number of function evaluations to reach target fitness
- Measure final solution quality
- Compute statistical significance of results across multiple independent runs [11]
Statistical Analysis:
- Perform Wilcoxon signed-rank tests to determine significant differences
- Calculate mean and standard deviation of performance metrics [11]
Differential Evolution represents a significant advancement in evolutionary computation, particularly for continuous optimization problems encountered in scientific research and drug development. Its distinctive approach of using vector differences to guide the search process enables efficient exploration of complex fitness landscapes without requiring gradient information or differentiable objective functions. For researchers investigating drug-target interactions, DE provides a powerful tool for optimizing complex computational models, as demonstrated by its successful application in predicting binding affinities with superior accuracy.
When compared to Genetic Algorithms, DE typically demonstrates faster convergence and better performance on continuous numerical optimization problems, while GAs may remain preferable for discrete or combinatorial problems [11]. The choice between these evolutionary approaches should be guided by problem characteristics—with DE being particularly well-suited for high-dimensional, continuous, multimodal problems common in drug discovery and chemometrics.
Future DE research directions include further development of adaptive parameter control mechanisms, hybridization with machine learning techniques for surrogate modeling, and enhanced constraint handling approaches for complex real-world optimization challenges [14] [17]. As computational power grows and optimization problems increase in complexity, DE's balance of simplicity, efficiency, and effectiveness positions it as an increasingly valuable tool in the researcher's toolkit.
In both natural evolution and computational optimization, four fundamental concepts form the cornerstone of understanding: genotype, phenotype, population, and fitness. These terms originate from evolutionary biology but have been adapted into powerful computational paradigms that drive modern optimization techniques. For researchers in drug development and related fields, understanding these concepts is crucial for leveraging evolutionary algorithms to solve complex problems, from molecular design to experimental parameter optimization. This guide provides an in-depth technical breakdown of these core concepts, framing them within the context of comparing two prominent evolutionary algorithms: Genetic Algorithms (GAs) and Differential Evolution (DE). The precise mathematical formulation of these concepts enables their transformation from biological principles into robust computational tools that can navigate high-dimensional search spaces common in pharmaceutical research and development.
Terminology Breakdown
Genotype
- Biological Definition: In genetics, a genotype constitutes the complete set of genes inherited from parents [18]. For a specific trait, it refers to the pair of alleles an organism possesses (e.g.,
RR,RW, orWWfor seed shape in Mendel's pea plants) [18]. - Computational Representation: In evolutionary computation, a genotype (or chromosome) is the encoded representation of a candidate solution within the algorithm's search space [19]. Unlike the discrete alleles in biology, computational genotypes often use real-valued or integer representations, especially in DE and related techniques applied to continuous parameter optimization [3].
- Algorithm Context: The representation of the genotype is a primary differentiator between GAs and DE. GAs traditionally use bitstrings (sequences of 1s and 0s) to represent solutions, requiring problem-specific encoding and decoding steps [19]. In contrast, DE typically operates directly on real-valued vectors, making it particularly suitable for numerical optimization problems in chemical systems and drug development where parameters are continuous [9] [3].
Table: Genotype Representations in Evolutionary Algorithms
| Algorithm | Typical Genotype Representation | Application Context |
|---|---|---|
| Genetic Algorithm (GA) | Bitstring (Binary or Gray-code) [19] | Discrete or encoded parameter spaces; subset selection [19] |
| Differential Evolution (DE) | Real-valued vector [3] | Continuous parameter optimization; chemical system tuning [9] |
| Paddy Field Algorithm (PFA) | Real-valued parameters (x = {x1, x2, ..., xn}) [9] |
High-dimensional chemical optimization tasks [9] |
Phenotype
- Biological Definition: The phenotype is the observable characteristic or trait of an organism (e.g., round or wrinkled seeds), which results from the expression of the genotype in conjunction with environmental influences [18].
- Computational Representation: In optimization, the phenotype is the actual candidate solution decoded from the genotype and evaluated by the objective function (or fitness function) [19]. For a real-valued genotype, the phenotype might be the vector itself, interpreted as a set of system parameters. For a binary-coded genotype, it must be decoded into meaningful parameters before evaluation [19].
- Algorithm Context: The mapping from genotype to phenotype is straightforward in DE due to its real-valued representation, reducing computational overhead [3]. In GAs, this mapping can be complex, involving scaling and transformation from a bitstring to real values or other data structures, which adds to the computational cost but provides flexibility for non-numeric problems [19].
Population
- Biological Definition: A biological population is a group of interbreeding individuals of the same species living in a shared geographical area [18]. Population genetics studies the genetic composition of such groups and how it changes over time [18].
- Computational Representation: In evolutionary algorithms, the population is the set of all candidate solutions (genotypes) being maintained and evolved during the optimization process [3] [19]. The population size is a critical algorithmic parameter balancing exploration of the search space and computational expense.
- Algorithm Context: Both GAs and DE are population-based optimizers. DE's population comprises real-valued vectors (agents), and its mutation strategy specifically uses vector differences within this population to explore the search space [3] [20]. GAs maintain a population of bitstrings, and diversity is managed through selection, crossover, and mutation operators [19]. The Paddy algorithm introduces a density-based reinforcement concept, where the spatial distribution of the population influences the propagation of new solutions [9].
Fitness
- Biological Definition: Fitness is a quantitative measure of an organism's ability to survive, reproduce, and propagate its genes to subsequent generations [21] [22]. It is a propensity rather than a guarantee—a genotype with high fitness has a high expected number of offspring [21] [22].
- Computational Representation: The fitness is the output value of the objective function being optimized. It numerically evaluates the quality of a candidate solution (phenotype) [19]. The algorithm's goal is to find the solution that minimizes or maximizes this function.
- Mathematical Formulation: In population genetics, the change in genotype frequency due to natural selection is driven by relative fitness (denoted
w), which is normalized against the fitness of other genotypes in the population [21] [22]. This is distinct from absolute fitness (W), which is the expected number of offspring or the actual growth rate of a genotype [21]. The change in allele frequency per generation isΔp = p(w - w̄)/w̄, wherepis the frequency,wis the relative fitness of the allele, andw̄is the mean relative fitness of the population [21] [22]. - Algorithm Context: In both GAs and DE, it is the relative fitness of solutions within the population that guides selection. DE uses a direct comparison between parent and trial vectors, inherently implementing a relative fitness competition [3]. GAs often use selection mechanisms explicitly based on relative fitness, such as fitness-proportional selection or ranking [19].
Table: Key Fitness Metrics and Their Computational Analogues
| Fitness Metric | Biological Definition | Computational Role in Optimization |
|---|---|---|
Absolute Fitness (W) |
The expected number of offspring of a genotype [21] [22]. | The raw output value of the objective function for a candidate solution. |
Relative Fitness (w) |
Absolute fitness normalized by the fitness of a reference genotype (often the fittest) [21] [22]. | A normalized quality measure used for selection probabilities (e.g., in GA selection) [19]. |
Selection Coefficient (s) |
A measure of the reduction in fitness of a genotype relative to the fittest (w₂ = 1 - s) [22]. |
Implicitly determines the replacement probability of a parent solution by a new candidate. |
Genetic Algorithms vs Differential Evolution: A Comparative Analysis
Understanding the core terminology enables a clear comparison of how Genetic Algorithms and Differential Evolution operationalize these concepts differently. The table below summarizes the key distinctions.
Table: Comparative Analysis of Genetic Algorithms and Differential Evolution
| Feature | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Genotype Representation | Discrete (Bitstrings) [19] | Continuous (Real-valued vectors) [3] |
| Primary Exploration Mechanism | Crossover (Recombination) & Mutation [19] | Differential Mutation & Crossover [3] |
| Mutation Operator | Bit-flip with low probability [19] | Weighted vector difference: v_i = x_r1 + F*(x_r2 - x_r3) [3] [20] |
| Crossover Operator | Multi-point (e.g., 1-point, uniform) [19] | Binomial or Exponential [3] |
| Selection Strategy | Fitness-proportional, tournament [19] | Greedy one-to-one spawning [3] |
| Typical Application Domains | Combinatorial problems, subset selection, sequencing [19] | Continuous parameter optimization, chemical system tuning [9] [3] |
The workflow diagrams for each algorithm illustrate how these components interact.
Genetic Algorithm Workflow
Differential Evolution Workflow
Experimental Protocols and Applications
Benchmarking Evolutionary Algorithms
Robust benchmarking is essential for evaluating algorithm performance. The following methodology, derived from the Paddy algorithm study [9], provides a framework for comparing GA, DE, and other optimizers:
- Define Benchmark Problems: Select a diverse set of optimization tasks:
- Mathematical Functions: Bimodal distributions, irregular sinusoidal functions to test convergence and ability to avoid local optima [9].
- Chemical Hyperparameter Optimization: Tuning an Artificial Neural Network for tasks like solvent classification for reaction components [9].
- Targeted Molecule Generation: Optimizing input vectors for a decoder network (e.g., Junction-Tree Variational Autoencoder) to design molecules with desired properties [9].
- Configure Algorithms: Set population size, iteration limits, and algorithm-specific parameters (e.g., DE's mutation factor
Fand crossover rateCR, GA's crossover and mutation rates) [9] [3]. Use identical computational resources. - Execute and Measure: For each benchmark and algorithm, run multiple independent trials to account for stochasticity. Track:
- Convergence Speed: Number of function evaluations or iterations to reach a solution threshold.
- Solution Quality: Best fitness value found.
- Robustness: Consistency of performance across different trials and problem types.
- Computational Runtime [9].
- Analyze Results: Compare performance metrics across algorithms. Advanced analysis may involve assessing performance on high-dimensional problems to evaluate scalability and the "curse of dimensionality" [3].
Application in Drug Discovery
Evolutionary algorithms are increasingly applied in pharmaceutical research. The "fitness function" in this context is a computational proxy for a desired drug profile. Key applications include:
- Molecular Generation and Optimization: AI-driven generative models can create novel molecular structures. Evolutionary algorithms like DE can optimize the input vectors of these models to steer generation toward regions of chemical space with high fitness, such as strong target binding affinity and low toxicity [9] [23].
- Chemical System Optimization: Algorithms can efficiently navigate complex experimental parameter spaces (e.g., reaction conditions, chromatographic settings) to maximize yield or purity, directly integrating with automated laboratory systems [9].
- Neural Network Training: DE can be used as a global optimizer to find the weights of a neural network, potentially avoiding local minima that trap traditional gradient-based methods, though at the cost of increased computational time [24].
The Scientist's Toolkit
Table: Essential Reagents and Resources for Evolutionary Algorithm Experiments
| Tool/Reagent | Function/Purpose | Example/Notes |
|---|---|---|
| Optimization Software Libraries | Provide implemented algorithms, saving development time. | Hyperopt (Tree of Parzen Estimators) [9], Ax/Botorch (Bayesian Optimization) [9], EvoTorch (Evolutionary Algorithms) [9]. |
| Paddy Package | Implements the Paddy Field Algorithm for chemical optimization [9]. | Python library for robust optimization of chemical systems; emphasizes avoiding local minima [9]. |
| Fitness (Objective) Function | Encodes the problem to be solved; evaluates solution quality. | Defined by the researcher. Examples: molecular binding affinity score, chemical reaction yield, neural network training error [9] [24]. |
| Computational Environment | Hardware and software for running resource-intensive optimizations. | Systems supporting parallel processing can significantly speed up population evaluation [20] [24]. |
| Validation Framework | Prevents overfitting and ensures solutions generalize. | Crucial in drug discovery. Uses out-of-sample data and robust statistical tests to validate optimized solutions [20] [23]. |
The precise definitions of genotype, phenotype, population, and fitness create a universal framework for understanding and applying evolutionary computation. For drug development professionals, the choice between Genetic Algorithms and Differential Evolution hinges on the problem structure: GAs offer flexibility for discrete and combinatorial problems, while DE excels at optimizing continuous parameters common in chemical and pharmacological models. Mastery of these core concepts enables the effective deployment of these powerful optimization strategies, accelerating research in molecular design, experimental planning, and the development of robust AI models for the pharmaceutical industry.
Evolutionary Algorithms (EAs) represent a sophisticated class of metaheuristic optimization methods that emulate the processes of biological evolution to solve complex computational problems. By utilizing mechanisms inspired by Darwinian natural selection—such as selection, mutation, and crossover—these algorithms effectively tackle a wide variety of optimization challenges that are difficult for traditional methodologies. The fundamental principle underlying evolutionary computation is the simulation of natural selection's "survival of the fittest" paradigm, where a population of candidate solutions evolves over generations toward increasingly optimal configurations [25] [10].
Within the broader family of evolutionary computing, Genetic Algorithms (GA) and Differential Evolution (DE) have emerged as two powerful approaches with distinct characteristics and applications. While both algorithms belong to the same evolutionary computation family and share conceptual foundations, they employ different strategies for manipulating candidate solutions and exploring search spaces. Genetic Algorithms, developed by John Henry Holland in the 1970s, operate on binary or discrete representations of solutions, applying genetic operators inspired by biological genetics [26] [5]. In contrast, Differential Evolution, introduced by Rainer Storn and Kenneth Price in 1997, specializes in continuous optimization problems and employs unique vector-based mutation strategies that differentiate it from traditional GAs [10] [27].
The biological inspiration for these algorithms extends beyond mere metaphor—it provides a robust framework for solving complex, multi-modal, and non-differentiable optimization problems that challenge conventional mathematical approaches. By mimicking nature's billion-year-old optimization process, researchers have developed computational tools capable of navigating high-dimensional search spaces, avoiding local optima, and discovering innovative solutions across diverse domains including drug discovery, engineering design, and artificial intelligence [10] [28].
Biological Foundations and Computational Analogies
The design of evolutionary algorithms draws upon well-established biological principles, creating direct analogies between natural processes and computational mechanisms. Understanding these biological foundations is essential for appreciating the operational principles of both Genetic Algorithms and Differential Evolution.
Natural Selection and Fitness Landscapes
In biological evolution, natural selection acts as the primary mechanism driving species adaptation to their environment. Organisms with traits better suited to their environment tend to survive and reproduce more successfully, passing these advantageous traits to subsequent generations. Similarly, in both GA and DE, a fitness function evaluates candidate solutions, preferentially selecting better-performing individuals to contribute to future generations [26]. The fitness function in evolutionary computation corresponds to the environmental pressures in nature, creating a computational "fitness landscape" where algorithms seek peaks of optimal performance [5].
Genetic Inheritance and Representation
Biological genetics provides the inspiration for how solutions are represented and modified in evolutionary algorithms. In nature, genetic information is encoded in DNA, which undergoes recombination during sexual reproduction and occasional mutations. Similarly, evolutionary algorithms maintain a population of candidate solutions, each represented as chromosomes containing genes that encode specific solution parameters [26]. The representation varies between algorithms—traditional GAs often use binary strings, while DE typically works with real-valued vectors, but both maintain the fundamental genetic metaphor [10] [27].
Evolutionary Operators
Biological evolution operates through several key mechanisms that have direct computational counterparts:
Mutation: In nature, random changes in DNA sequences introduce novel traits. In evolutionary computation, mutation operators randomly alter portions of candidate solutions, maintaining population diversity and exploring new regions of the search space [26] [5].
Crossover (Recombination): Sexual reproduction combines genetic material from parents to produce offspring. Similarly, algorithmic crossover operations combine elements from multiple parent solutions to create new candidate solutions [26].
Selection: Nature's survival-of-the-fittest principle is implemented through selection operators that determine which solutions get to reproduce based on their fitness [5].
The following table summarizes the biological analogies in GA and DE:
Table 1: Biological Analogies in Evolutionary Algorithms
| Biological Concept | Computational Implementation | Role in Optimization |
|---|---|---|
| DNA/Genome | Chromosome (Binary, Real-valued) | Solution representation |
| Gene | Parameter/variable | Decision variable |
| Population | Set of candidate solutions | Diversity maintenance |
| Fitness | Objective function value | Solution quality measure |
| Mutation | Random perturbation | Diversity introduction |
| Crossover | Solution recombination | Exploitation of good traits |
| Natural Selection | Selection operators | Fitness-based propagation |
Genetic Algorithms: Mechanisms and Methodologies
Algorithmic Framework and Core Components
Genetic Algorithms operate through an iterative process that mirrors biological evolution, starting with an initial population of candidate solutions and progressively improving them through the application of genetic operators. The algorithm maintains a population of individuals, each representing a potential solution to the optimization problem at hand. These individuals undergo evaluation, selection, and reproduction cycles that emulate natural evolutionary processes [26] [5].
The standard Genetic Algorithm workflow consists of several well-defined phases. Initialization creates the first generation of candidate solutions, typically through random generation within the problem's search space. The fitness evaluation phase assesses each solution's quality using a problem-specific fitness function. Selection identifies promising solutions based on their fitness, giving them higher probability of contributing offspring to the next generation. Crossover combines genetic material from selected parents to produce new solutions, while mutation introduces random changes to maintain diversity. Finally, replacement forms the new population for the next generation [26].
Diagram 1: Genetic Algorithm Workflow
Genetic Representation and Operators
A fundamental aspect of Genetic Algorithms is the chromosomal representation of solutions. While traditional GAs often employ binary strings, modern implementations may use various representations including real-valued vectors, permutations, or tree structures depending on the problem domain [26]. The representation choice significantly impacts algorithm performance and should align with the problem structure.
Selection operators determine which solutions proceed to the reproduction phase. Common selection strategies include:
- Fitness Proportionate Selection: Solutions are selected with probability proportional to their fitness scores [5].
- Tournament Selection: Small random subsets of the population compete, with the fittest advancing [27].
- Rank-Based Selection: Solutions are selected based on their fitness rank rather than absolute values [5].
Crossover operators combine genetic information from parent solutions. Standard approaches include:
- Single-Point Crossover: A single crossover point is selected, and tails are swapped [26].
- Multi-Point Crossover: Multiple crossover points divide the chromosome into alternating segments [27].
- Uniform Crossover: Each gene is randomly selected from either parent with equal probability [26].
Mutation operators introduce random perturbations to maintain population diversity. The mutation rate is typically kept low to prevent the algorithm from degenerating into random search [26] [5].
Implementation Considerations
Successful implementation of Genetic Algorithms requires careful attention to several parameters that control the evolutionary process. The population size balances diversity and computational cost—larger populations explore more space but require more evaluations per generation [26]. Crossover and mutation rates determine the balance between exploiting existing good solutions and exploring new regions of the search space. Elitism strategies preserve the best solutions from each generation, ensuring that high-quality genetic material is not lost [27].
Termination criteria for GAs may include reaching a maximum number of generations, achieving a satisfactory fitness level, or detecting convergence when successive generations no longer produce significant improvements [26]. Proper parameter tuning is essential for obtaining good performance, though optimal settings are often problem-dependent [26] [27].
Differential Evolution: Advanced Evolutionary Approach
Algorithmic Foundations and Vector Operations
Differential Evolution represents a significant advancement in evolutionary computation, specifically designed for continuous optimization problems. While sharing the general evolutionary framework with Genetic Algorithms, DE employs distinct vector-based operations that make it particularly effective for real-valued search spaces. The algorithm begins by initializing a population of candidate solutions, represented as real-valued vectors, within the specified bounds of the optimization problem [10] [2].
The hallmark of Differential Evolution is its unique mutation strategy, which generates new parameter vectors by adding the scaled difference between two population vectors to a third vector. This approach enables DE to automatically adapt the step size and orientation of the search based on the current population distribution. The standard mutation strategy, denoted as DE/rand/1, follows the formula:
[ \text{mutant} = x{r1} + F \cdot (x{r2} - x_{r3}) ]
where (x{r1}), (x{r2}), and (x_{r3}) are three distinct randomly selected population vectors, and (F) is the scaling factor controlling the amplification of the differential variation [10] [2].
Following mutation, DE employs a crossover operation that combines parameters from the mutant vector with those of a target vector to produce a trial vector. Unlike the typical crossover in GAs, DE commonly uses binomial crossover where each parameter is independently selected from either the mutant or target vector based on a crossover probability [10]. The final selection step is deterministic—the trial vector replaces the target vector in the next generation only if it yields an equal or better fitness value [2].
Diagram 2: Differential Evolution Workflow
Mutation Strategies and Parameter Control
Differential Evolution features several mutation strategies that influence its exploration-exploitation balance. Common strategies include:
- DE/rand/1: Uses three randomly selected vectors, promoting exploration.
- DE/best/1: Incorporates the best solution in the population to guide toward promising regions.
- DE/current-to-best/1: Combines the current vector with the best solution to balance exploration and exploitation.
The naming convention DE/x/y/z specifies the vector to be mutated (x), the number of difference vectors used (y), and the crossover type (z) [2].
DE requires only three control parameters, making it simpler to implement than many other evolutionary algorithms:
- Population Size (NP): Typically set between 5-10 times the problem dimension [10].
- Scaling Factor (F): Controls mutation strength, usually in [0, 1] or [0, 2] [2].
- Crossover Rate (CR): Determines parameter inheritance probability, typically in [0.3, 1] [10].
These parameters significantly impact DE performance, and extensive research has focused on adaptive parameter control mechanisms to enhance its robustness across diverse problem types [10].
Comparative Analysis: Genetic Algorithm vs Differential Evolution
Structural and Operational Differences
While both Genetic Algorithms and Differential Evolution belong to the evolutionary computation family and share common biological inspiration, they exhibit fundamental differences in their operational mechanisms and philosophical approaches to optimization. Understanding these distinctions is crucial for selecting the appropriate algorithm for specific problem domains and applications.
The primary distinction lies in their solution representation and operational domains. Traditional Genetic Algorithms often employ binary or discrete representations, making them suitable for combinatorial optimization problems. In contrast, Differential Evolution operates directly on real-valued vectors, positioning it as a preferred choice for continuous optimization problems [10] [27]. This fundamental difference in representation leads to variations in their genetic operators and search mechanisms.
Another significant difference concerns the application order of genetic operators. In Genetic Algorithms, selection typically occurs before recombination and mutation, emphasizing the propagation of high-fitness individuals. Differential Evolution reverses this sequence—mutation is the primary operator, followed by crossover and selection. This operational reversal contributes to DE's explorative capabilities in continuous spaces [27].
The mutation strategies employed by both algorithms further highlight their philosophical differences. GA uses typically small, random perturbations to maintain population diversity. DE's mutation is more directional, utilizing vector differences to guide the search process. This difference makes DE particularly effective for correlated parameter optimization where the relationship between variables can be exploited through vector operations [10] [2].
Table 2: Algorithmic Comparison Between GA and DE
| Characteristic | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Solution Representation | Binary, Discrete, Real-valued | Primarily Real-valued Vectors |
| Primary Operators | Selection, Crossover, Mutation | Mutation, Crossover, Selection |
| Mutation Strategy | Random perturbations | Scaled vector differences |
| Crossover Type | Single/Multi-point, Uniform | Binomial, Exponential |
| Selection Method | Probabilistic (Fitness-based) | Deterministic (Greedy) |
| Parameter Control | Multiple parameters required | Fewer parameters (F, CR, NP) |
| Problem Domain | Discrete, Combinatorial | Continuous, Real-valued |
| Convergence Behavior | May premature converge | Generally better global convergence |
Performance Analysis and Application Suitability
Empirical studies comparing GA and DE reveal distinct performance characteristics across various problem domains. Research indicates that DE often demonstrates superior performance on continuous optimization problems, particularly those with real-valued parameters and nonlinear objective functions [10] [27]. The vector-based operations of DE enable efficient navigation of continuous search spaces, often resulting in faster convergence to near-optimal solutions.
A comprehensive comparative study applied both GA and DE to the in-core fuel management (ICFM) problem of a research reactor, providing valuable insights into their relative performance. The research implemented two GA variants (with tournament and roulette wheel selection) alongside a basic DE strategy (DE/rand/1/bin). Statistical analysis of 50 independent runs for each method revealed that DE and GA with tournament selection performed comparably and significantly better than GA with roulette wheel selection. Importantly, DE demonstrated greater stability in exploring the search space and approached global optima in most runs, while both GA variants were susceptible to becoming trapped in local optima (26% for tournament GA, 38% for roulette wheel GA) [27].
The performance advantages of DE extend to its parameter sensitivity and ease of use. While both algorithms require parameter tuning, DE operates effectively with only three main control parameters compared to GA's typically larger parameter set. This characteristic makes DE more accessible to practitioners and reduces the overhead associated with extensive parameter optimization [10].
However, Genetic Algorithms maintain advantages in specific problem domains, particularly those involving discrete or combinatorial optimization. Problems such as scheduling, routing, and assignment where solutions naturally comprise discrete choices often align better with GA's representation capabilities [26]. Additionally, GA's longer history has resulted in more extensive hybridization with other techniques and broader implementation across diverse domains.
Applications in Drug Discovery and Development
Molecular Optimization and Drug-Target Interactions
The pharmaceutical industry has embraced evolutionary algorithms to address complex challenges in drug discovery and development, particularly in optimizing molecular structures and predicting drug-target interactions. Both Genetic Algorithms and Differential Evolution have demonstrated significant utility in these domains, though their applications often reflect their algorithmic strengths.
Drug-Target Binding Affinity Prediction represents a critical application where DE has shown remarkable performance. Researchers have developed a sophisticated deep learning approach called Convolution Self-Attention Network with Attention-based Bidirectional Long Short-Term Memory Network (CSAN-BiLSTM-Att) for predicting binding affinities between drugs and targets. Due to the model's complexity, proper hyperparameter tuning is essential for optimal performance. Differential Evolution has been successfully employed to select the most suitable hyperparameters, resulting in state-of-the-art performance with a concordance index of 0.898 and mean square error of 0.228 on the DAVIS dataset, and 0.971 concordance with 0.014 MSE on the KIBA dataset [16].
In targeted molecule generation, researchers have developed innovative frameworks that leverage both GA and DE for lead optimization in drug design. The LEOMol (Latent Evolutionary Optimization for Molecule Generation) approach integrates Evolutionary Algorithms with Variational AutoEncoders to search the latent space of molecular representations. This framework consistently demonstrates superior performance compared to previous state-of-the-art models across various constrained molecule generation tasks. The approach effectively generates molecules with desired properties while preserving similarity to input molecules—a crucial aspect of lead optimization [28].
Experimental Protocols and Research Reagents
The implementation of evolutionary algorithms in drug discovery follows rigorous experimental protocols and utilizes specific research reagents and computational resources. Below is a comprehensive overview of essential components in such research:
Table 3: Research Reagent Solutions for Evolutionary Algorithm Applications in Drug Discovery
| Research Reagent/Resource | Function/Purpose | Example Implementation |
|---|---|---|
| ZINC250k Dataset | Curated collection of drug-like molecules for model training | Pre-training VAEs for molecular representation learning [28] |
| DAVIS & KIBA Datasets | Benchmark datasets for drug-target binding affinity prediction | Evaluating model performance [16] |
| SELFIES Representation | Robust molecular string representation ensuring validity | Molecular encoding in VAEs [28] |
| RDKit | Open-source cheminformatics toolkit | Computing molecular properties and descriptors [28] |
| Variational AutoEncoder (VAE) | Deep learning architecture for latent space learning | Molecular representation and generation [28] |
| Convolution Self-Attention Network | Neural architecture for feature extraction | Processing molecular structures [16] |
| Bidirectional LSTM with Attention | Sequence processing with focus mechanisms | Analyzing molecular sequences [16] |
The experimental workflow for drug discovery applications typically involves multiple stages. Data preparation involves curating molecular datasets and computing relevant properties using cheminformatics tools like RDKit. Model architecture selection depends on the specific task—CSAN-BiLSTM-Att for binding affinity prediction or VAE frameworks for molecule generation. Algorithm implementation incorporates either GA or DE for optimization tasks, with careful parameter tuning. Validation and testing employ appropriate metrics and benchmark datasets to assess performance [16] [28].
For binding affinity prediction, the experimental protocol involves:
- Representing compounds and proteins using appropriate features (molecular fingerprints, protein sequences)
- Implementing the CSAN-BiLSTM-Att architecture for affinity prediction
- Employing Differential Evolution for hyperparameter optimization
- Evaluating performance using concordance index and mean square error
- Comparing results against baseline methods like KronRLS and SimBoost [16]
For molecular generation tasks, the LEOMol protocol includes:
- Pre-training a VAE on the ZINC250k dataset using SELFIES representations
- Implementing GA or DE to search the latent space for molecules satisfying constraints
- Incorporating property prediction oracles (including non-differentiable ones like RDKit)
- Generating molecules balancing novelty, desired properties, and similarity constraints [28]
The biological inspiration underlying Genetic Algorithms and Differential Evolution has proven remarkably fruitful in guiding the development of powerful optimization techniques. By emulating nature's evolutionary processes—natural selection, genetic inheritance, mutation, and recombination—these algorithms effectively solve complex problems across diverse domains, particularly in drug discovery and development. The comparative analysis reveals that while both algorithms share common biological foundations, their distinct operational mechanisms make them suitable for different problem classes, with DE generally excelling in continuous optimization and GA maintaining relevance for discrete and combinatorial problems.
The ongoing integration of evolutionary algorithms with advanced deep learning architectures represents a promising direction for future research, particularly in pharmaceutical applications. As demonstrated by recent advances in drug-target binding affinity prediction and targeted molecule generation, the synergy between biological inspiration and computational innovation continues to drive progress in optimizing complex molecular systems. These developments underscore the enduring value of biological principles as guides for computational algorithm design, enabling solutions to challenges that resist traditional mathematical approaches.
Inside the Algorithms: Operators, Workflows, and Scientific Applications
Genetic Algorithms (GAs) are adaptive heuristic search algorithms belonging to the larger class of evolutionary algorithms (EA). They are inspired by Charles Darwin's theory of natural selection and genetics, simulating the process of "survival of the fittest" among individuals across consecutive generations to solve optimization and search problems [29]. GAs are intelligent exploitation of random search provided with historical data to direct the search into the region of better performance in solution space [29]. These algorithms have found applications in diverse fields including drug discovery, hyperparameter optimization, and solving complex computational problems [30] [26].
In the broader context of evolutionary computation, GAs represent a specific approach that maintains a population of candidate solutions and evolves them through biologically inspired operations. When comparing GAs with differential evolution (DE)--another evolutionary algorithm--key differences emerge in their representation schemes and variation operators. While GAs typically use chromosome-based representations (often binary or integer strings), DE operates directly on real-valued vectors [6] [4]. Additionally, the mutation operator in DE is distinctly different, utilizing directional information from the population by calculating difference vectors [7].
Core Components of Genetic Algorithms
Fundamental Operators and Their Roles
The power of Genetic Algorithms emerges from the interaction of several core components that mimic evolutionary processes in nature. These components work together to maintain, improve, and diversify a population of candidate solutions over successive generations.
Table 1: Core Components of a Genetic Algorithm
| Component | Function | Biological Analogy |
|---|---|---|
| Initialization | Creates initial population of candidate solutions | Genesis of life |
| Selection | Chooses fitter individuals for reproduction | Natural selection |
| Crossover | Combines genetic information from two parents | Sexual reproduction |
| Mutation | Introduces random changes in genetic material | Genetic mutation |
| Replacement | Forms new generation from parents and offspring | Generational succession |
The GA methodology involves an iterative process where a population of candidate solutions (called individuals, creatures, organisms, or phenotypes) is evolved toward better solutions [26]. Each candidate solution has a set of properties called chromosomes or genotype that can be mutated and altered [26]. The evolution usually starts from a population of randomly generated individuals, with each iteration called a generation [26].
Algorithm Workflow Visualization
The following diagram illustrates the complete workflow of a canonical Genetic Algorithm, showing how the core components interact in an iterative cycle:
Detailed Breakdown of GA Workflow Components
Initialization
The evolutionary process begins with initialization, where an initial population of candidate solutions is generated [31]. The population size depends on the nature of the problem but typically contains hundreds or thousands of possible solutions [26]. While there are many methods for initializing populations, the most common approach in GAs is to create a population of randomly initialized binary strings [31]. However, other representations are possible, including real-valued vectors, integers, or tree structures depending on the problem domain.
The initialization phase is critical as it establishes the initial genetic diversity of the population. Occasionally, the solutions may be "seeded" in areas where optimal solutions are likely to be found, potentially accelerating convergence [26]. For problems with constrained search spaces, initialization must ensure all generated individuals are valid solutions or employ repair mechanisms to handle constraint violations.
Selection
Selection represents the first step in the generational cycle, where individuals are chosen from the current population to become parents for the next generation [31]. The selection process is fitness-based, meaning that individuals with better fitness scores have a higher probability of being selected [31] [29]. This operator implements the "survival of the fittest" principle by giving preference to individuals with better adaptation to their environment.
Table 2: Common Selection Methods in Genetic Algorithms
| Method | Description | Advantages | Disadvantages |
|---|---|---|---|
| Roulette Wheel | Probability proportional to fitness | Simple to implement | Premature convergence |
| Tournament | Selects best from random subset | Good diversity maintenance | Tournament size affects pressure |
| Rank-Based | Probability based on rank not raw fitness | Avoids super-individual dominance | Slower convergence |
| Elitism | Directly copies best individuals to next generation | Preserves best solutions | May reduce diversity |
The fitness function is always problem-dependent and measures the quality of the represented solution [26]. For example, in the knapsack problem, the fitness might represent the total value of objects in the knapsack if the solution is valid, or 0 otherwise [26]. In some problems, it may be hard or impossible to define an explicit fitness expression, requiring simulations or interactive approaches for fitness evaluation [26].
Crossover (Recombination)
Crossover, also called recombination, is a genetic operator that combines genetic information from two parents to generate new offspring [31] [29]. This operator is responsible for exploiting the existing genetic material in the population by combining promising solution fragments from different parents. Crossover is typically applied with a high probability (usually between 0.6-0.9) to encourage the mixing of genetic material.
The following diagram illustrates the single-point crossover mechanism, one of the most common crossover operations in Genetic Algorithms:
Several crossover techniques have been developed for different representation schemes:
- Single-point crossover: A single crossover point is selected, and genetic material beyond this point is swapped between parents [31].
- Two-point crossover: Two crossover points are selected, and the segment between them is swapped [4].
- Uniform crossover: Each gene is randomly copied from one of the parents [4].
- Arithmetic crossover: New individuals are created by calculating the weighted arithmetic mean of two parents (for real-valued representations).
Mutation
While crossover combines existing genetic material, mutation introduces new genetic material into the population [31]. Mutation is applied to offspring after crossover, typically with a low probability (often between 0.001-0.01) to maintain population diversity while not disrupting good solutions excessively [26]. This operator helps the algorithm explore new regions of the search space and escape local optima.
The implementation of mutation depends on the representation scheme:
- For binary representations, bit-flip mutation randomly toggles bits from 0 to 1 or vice versa [31].
- For real-valued representations, Gaussian or uniform noise addition is common.
- For integer representations, random replacement with valid values is typical.
- For permutation representations, swap, inversion, or scramble mutations are used.
Table 3: Mutation Operators for Different Representation Types
| Representation | Mutation Operator | Example |
|---|---|---|
| Binary | Bit-flip | 1010 → 1000 |
| Integer | Random resetting | (3,5,2) → (3,1,2) |
| Real-valued | Gaussian perturbation | (1.2, 3.4) → (1.3, 3.2) |
| Permutation | Swap | (A,B,C,D) → (A,D,C,B) |
Replacement
Replacement is the final step in the generational cycle where the old population is replaced with the newly created offspring [31]. The replacement strategy determines how the new generation is formed from the existing population and the newly created offspring. This operator plays a crucial role in controlling the selective pressure and maintaining population diversity.
Common replacement strategies include:
- Generational replacement: The entire parent population is replaced by the offspring population [31].
- Elitism: The best individuals from the parent population are preserved in the next generation [29].
- Steady-state: Only a portion of the population is replaced in each generation.
- Tournament replacement: Individuals are replaced based on fitness comparisons.
Experimental Protocol and Parameter Configuration
Standard Experimental Setup
Implementing a Genetic Algorithm for optimization requires careful configuration of multiple parameters. The following table summarizes key parameters and their typical values based on empirical studies:
Table 4: Genetic Algorithm Parameter Settings
| Parameter | Typical Range | Recommended Starting Value | Effect on Search |
|---|---|---|---|
| Population Size | 50-1000 | 100 | Larger = more diversity but slower |
| Crossover Rate | 0.6-0.95 | 0.85 | Higher = more exploitation |
| Mutation Rate | 0.001-0.01 | 0.005 | Higher = more exploration |
| Selection Pressure | Varies by method | Tournament size = 3 | Higher = faster convergence |
| Elitism Count | 1-10% of population | 1-5 individuals | Preserves best solutions |
The algorithm typically terminates when one of several conditions is met: a solution is found that satisfies minimum criteria, a fixed number of generations has been reached, the allocated budget (computation time/money) has been exhausted, or the highest ranking solution's fitness has reached a plateau [26].
Researcher's Toolkit: Essential Components for GA Implementation
Implementing effective Genetic Algorithms requires both conceptual understanding and practical tools. The following toolkit outlines essential components for GA research and application development:
Table 5: Genetic Algorithm Researcher's Toolkit
| Component | Function | Example Tools/Implementations |
|---|---|---|
| Representation Scheme | Encodes problem solutions | Binary strings, real-valued vectors, permutations |
| Fitness Function | Evaluates solution quality | Problem-specific objective function |
| Selection Operator | Chooses parents for reproduction | Tournament selection, roulette wheel |
| Crossover Operator | Combines parent solutions | Single-point, uniform, arithmetic crossover |
| Mutation Operator | Introduces random changes | Bit-flip, Gaussian, swap mutation |
| Replacement Strategy | Forms new generation | Generational, steady-state, elitist |
| Termination Condition | Determines when to stop | Max generations, fitness threshold, convergence |
Comparison with Differential Evolution
When comparing Genetic Algorithms with Differential Evolution (DE), several key differences emerge that are particularly relevant for researchers and practitioners. DE is another evolutionary algorithm that has gained popularity for solving continuous optimization problems [6] [13].
The most significant difference lies in the mutation strategy. While GAs typically use random changes or probability distributions for mutation, DE employs a unique approach that uses the weighted difference between two or more population vectors to create a mutant vector [7]. This approach provides DE with directional information from the current population distribution, often leading to faster convergence on continuous problems [7].
Another distinction is in the application focus. GAs are more often applied to combinatorial and discrete problems, while DE is primarily used for multidimensional real-valued functions [4] [13]. Additionally, in DE, the order of operations is different—crossover is applied after mutation, instead of the other way around as in canonical GAs [7].
For drug discovery professionals, both algorithms offer distinct advantages. GAs with their flexible representation schemes can handle diverse molecular representations, while DE's efficient continuous optimization may be beneficial for quantitative structure-activity relationship (QSAR) modeling and molecular docking simulations [30].
Differential Evolution (DE) is a powerful evolutionary algorithm widely used for solving complex optimization problems across various scientific fields, including computational chemistry and drug development. Introduced by Storn and Price in the mid-1990s, DE has established itself as a leading metaheuristic in the class of evolutionary algorithms due to its simplicity, robustness, and efficient convergence properties [32] [10]. Unlike traditional gradient-based methods, DE does not require the objective function to be differentiable, making it particularly effective for non-linear, non-differentiable, and multimodal optimization problems commonly encountered in real-world applications [32].
For researchers conducting comparative analyses of optimization algorithms, understanding DE's operational workflow is essential. This guide provides a comprehensive technical examination of DE's core components—initialization, mutation, crossover, and selection—framed within the broader context of how DE compares to traditional Genetic Algorithms (GAs). While both methods belong to the evolutionary computation family and share conceptual foundations in natural selection principles, they differ significantly in their operational mechanisms and performance characteristics [6] [10]. DE's distinctive approach of using vector differences for exploration and exploitation gives it particular advantages for continuous optimization problems relevant to drug discovery and molecular design [28].
Core Conceptual Framework: DE vs. Genetic Algorithms
Understanding Differential Evolution requires situating it within the broader landscape of evolutionary algorithms, particularly in comparison to Genetic Algorithms. While both are population-based metaheuristics inspired by natural evolution, their operational mechanisms and philosophical approaches differ significantly, leading to distinct performance characteristics across various problem domains [6].
Table 1: Fundamental Differences Between Differential Evolution and Genetic Algorithms
| Aspect | Differential Evolution (DE) | Genetic Algorithms (GA) |
|---|---|---|
| Representation | Primarily uses real-valued vectors [6] | Traditionally binary strings, though other representations possible [26] |
| Mutation Mechanism | Uses weighted vector differences [32] [33] | Typically bit-flips or random perturbations [34] |
| Crossover Approach | Binomial or exponential; gene exchange with probability CR [33] | Typically one-point, two-point, or uniform [34] |
| Parameter Sensitivity | Fewer parameters (F, CR, NP) [10] | Often requires tuning more parameters [34] |
| Primary Strength | Effective continuous optimization [10] | Broad applicability to discrete/continuous problems [26] |
The philosophical distinction between these approaches manifests in their practical implementation. DE operates directly on real-valued vectors using straightforward vector operations, making it particularly suitable for continuous optimization problems in scientific computing and engineering [10]. In contrast, GA's representation-agnostic nature provides flexibility across discrete and continuous domains but may require more careful operator design for specific problem types [26]. As noted in optimization literature, DE often produces "better, more stable solutions than GA" for continuous problems, competing effectively in terms of computational efficiency [10].
The Differential Evolution Workflow: Core Components
Initialization
The DE process begins with population initialization, where an initial set of candidate solutions is generated. For a D-dimensional optimization problem, the population consists of NP parameter vectors, each representing a potential solution. The initial population P = {X₁, X₂, ..., X_NP} is typically created by randomly generating values for each parameter within specified boundary constraints [33]:
where xi,j represents the j-th parameter of the i-th individual, xj,min and x_j,max are the lower and upper bounds for the j-th dimension, and rand(0,1) is a uniformly distributed random number between 0 and 1 [33]. This random initialization ensures adequate coverage of the search space, providing diverse genetic material for the evolutionary process. Population size (NP) is a critical parameter, with typical values ranging from 5 to 10 times the dimensionality of the problem, though problem-specific tuning may yield better performance [10].
Figure 1: DE Initialization Workflow
Mutation: Generating Donor Vectors
Following initialization, DE enters its generational loop, beginning with the mutation operation. Unlike the random perturbations typical of GA mutation, DE creates mutant/donor vectors by calculating weighted differences between population members [6] [33]. This distinctive approach leverages the distribution of the current population to guide the search direction and step size. For each target vector Xi in the current population, a donor vector Vi is generated according to a specific mutation strategy.
The most common mutation strategy, known as "DE/rand/1," follows this formulation [33]:
where r1, r2, and r3 are mutually distinct random indices different from i, and F is the scaling factor typically chosen from the range [0, 2] [33]. The differential component (Xr2 - Xr3) introduces the explorative capability, while the scaling factor F controls the amplification of the differential variation.
Table 2: Common DE Mutation Strategies and Applications
| Strategy | Formulation | Characteristics | Best For |
|---|---|---|---|
| DE/rand/1 | Vi = Xr1 + F · (Xr2 - Xr3) | Maintains diversity, good exploration | Multimodal problems [33] |
| DE/best/1 | Vi = Xbest + F · (Xr1 - Xr2) | Fast convergence, exploitation | Unimodal problems [33] |
| DE/current-to-best/1 | Vi = Xi + F · (Xbest - Xi) + F · (Xr1 - Xr2) | Balanced approach | Mixed search spaces [33] |
| DE/rand/2 | Vi = Xr1 + F · (Xr2 - Xr3) + F · (Xr4 - Xr5) | Enhanced exploration | Complex landscapes [33] |
The mutation strategy significantly influences DE's search behavior, balancing exploration (searching new areas) and exploitation (refining existing solutions). More advanced strategies like "DE/current-to-pbest/1" incorporate information from multiple high-quality solutions to guide the search more efficiently [33].
Crossover: Creating Trial Vectors
Following mutation, DE performs crossover to increase population diversity and combine genetic information. The donor vector Vi undergoes recombination with the target vector Xi to produce a trial vector U_i [32]. While GAs typically use one-point or two-point crossover, DE commonly employs binomial crossover, where each component (gene) of the trial vector is independently selected from either the donor or target vector [33]:
Here, CR is the crossover probability ∈ [0,1], j_rand is a randomly chosen index ∈ [1,D] that ensures at least one component is inherited from the donor vector [32] [33]. This element-wise operation differs significantly from the segment-based crossover typical in GAs and contributes to DE's effectiveness in continuous optimization.
Figure 2: DE Crossover Mechanism
Selection: Greedy Survival Competition
The final step in the DE generational cycle is selection, where the trial vector Ui competes directly against its target vector Xi for a place in the next generation [32]. DE employs a greedy selection strategy: if the trial vector yields an equal or better fitness value than the target vector, it replaces the target in the next generation; otherwise, the target vector survives unchanged [33]:
This one-to-one selection mechanism differs from the typical GA approach, where parents and children compete together for survival [6]. The greedy nature of DE selection creates strong evolutionary pressure, driving rapid convergence toward better solutions. However, this strength can become a weakness if not balanced with sufficient diversity maintenance, as it may lead to premature convergence [35].
Advanced DE Frameworks and Recent Developments
As DE has matured, researchers have developed numerous enhancements to address its limitations, particularly regarding parameter tuning, premature convergence, and stagnation in complex search landscapes. Modern DE variants often incorporate adaptive parameter control, ensemble mutation strategies, and hybrid mechanisms to maintain the exploration-exploitation balance throughout the search process [33] [35].
One significant advancement is the External Selection Mechanism (ESM), which stores successful solutions from each iteration in an archive [33]. When the algorithm detects stagnation, it selects parents for mutation from this archive, injecting previously successful genetic material back into the population to restore search diversity. This approach leverages the information entropy theory to maintain archive diversity, demonstrating improved performance on benchmark problems [33].
Another innovative framework, DEF-FM (Differential Evolution Framework based on the Fluid Model), incorporates principles from fluid mechanics to create dynamic mutation strategies that automatically balance exploration and exploitation [35]. This approach introduces hydrodynamic-inspired operations that prevent premature convergence by promoting diversity when the population shows signs of stagnation, showing particular promise for high-dimensional feature selection problems in machine learning applications [35].
Practical Implementation: Protocols and Reagents
Implementing an effective DE algorithm requires careful consideration of several practical aspects. Below, we outline a standard experimental protocol for applying DE to optimization problems, followed by essential "research reagents" - the computational tools and components needed for implementation.
Standard DE Experimental Protocol
Algorithm 1: Canonical Differential Evolution [33]
- Parameter Setting: Set population size (NP), scaling factor (F), crossover rate (CR), and stopping criterion.
- Initialization: Randomly initialize population of NP individuals within bounds.
- While stopping criterion not met do
- For each individual i in population do
- Mutation: Generate donor vector V_i using selected strategy (e.g., DE/rand/1)
- Crossover: Create trial vector Ui by recombining Vi and X_i
- Selection: Evaluate fitness and select between Xi and Ui for next generation
- End For
- End While
- Return best solution found
Table 3: Research Reagent Solutions for DE Implementation
| Component | Function | Implementation Options |
|---|---|---|
| Population Structure | Maintains candidate solutions | Array of real-valued vectors [33] |
| Fitness Evaluator | Assesses solution quality | Problem-specific objective function [10] |
| Mutation Operators | Generates donor vectors | DE/rand/1, DE/best/1, DE/current-to-best/1 [33] |
| Crossover Methods | Creates trial vectors | Binomial crossover, Exponential crossover [32] |
| Parameter Controllers | Adjusts F, CR, NP | Fixed values, Adaptive schemes [10] |
| Constraint Handlers | Maintains feasible solutions | Penalty functions, Projection methods [36] |
Application in Drug Discovery: LEOMol Case Study
A compelling example of DE's practical utility comes from drug discovery, where researchers have developed LEOMol (Latent Evolutionary Optimization for Molecule Generation), a framework that combines Variational Autoencoders with evolutionary algorithms for targeted molecule generation [28]. In this application, DE searches the latent space of molecular representations to identify regions corresponding to molecules with desired properties, outperforming gradient-based methods, particularly when using non-differentiable property oracles like RDKit [28].
The LEOMol implementation demonstrates DE's advantage in handling complex, real-world optimization challenges where objective functions may be noisy, non-differentiable, or computationally expensive to evaluate. This capability makes DE particularly valuable for lead optimization in drug discovery, where the goal is to refine chemical compounds to meet specific molecular property targets while maintaining structural similarity to promising initial candidates [28].
Differential Evolution represents a sophisticated yet practical approach to continuous optimization, with a distinctive workflow that differentiates it from traditional Genetic Algorithms. Its operations—initialization, mutation through vector differences, binomial crossover, and greedy selection—create a powerful search mechanism that balances exploration and exploitation effectively. For drug development professionals and researchers, DE offers particular advantages for challenging optimization problems involving non-differentiable functions, multiple optima, or complex constraints.
As evolutionary computation continues to evolve, DE remains an active research area with ongoing developments in adaptive parameter control, hybrid models, and specialized variants for high-dimensional problems. The algorithm's conceptual simplicity, combined with its demonstrated effectiveness across diverse applications, ensures its continued relevance for scientific optimization challenges, particularly in the demanding field of pharmaceutical research and development.
Within the framework of a broader thesis comparing Genetic Algorithms (GAs) and Differential Evolution (DE) for beginners in research, particularly those in drug development, understanding the core operational mechanisms of each algorithm is paramount. Both GAs and DE belong to the class of evolutionary computation and are used to solve complex optimization problems by evolving a population of candidate solutions over generations [25] [6]. However, they diverge significantly in their approach to creating new candidate solutions. This whitepaper provides an in-depth technical comparison of two fundamental operators: the crossover operator from GAs and the differential mutation operator from DE. For researchers aiming to apply these techniques to problems like molecular docking or drug candidate optimization, grasping the nuances of these operators is crucial for selecting and tuning the appropriate algorithm.
Conceptual Foundations of the Operators
Genetic Algorithm (GA) and Crossover
In GAs, a potential solution is encoded as a chromosome (or genotype), which can be represented using binary, integer, or floating-point values [34]. The crossover operator is a cornerstone of GA, drawing a direct analogy to sexual reproduction in biological systems [34]. Its primary function is to combine genetic information from two parent chromosomes to produce one or two offspring [37]. The underlying hope is that by merging promising building blocks (schemata) from two fit parents, the offspring may exhibit superior fitness [34] [37]. The application of crossover is typically governed by a crossover rate (CR), a user-defined hyperparameter that controls the probability of the crossover operation occurring for a given pair of parents [34].
Differential Evolution (DE) and Differential Mutation
DE, while similar in its evolutionary structure, places a different emphasis on its operators. It predominantly uses real-valued vectors as its chromosomal representation [6] [38]. The central and most distinctive operator in DE is differential mutation. Contrary to its name in the evolutionary context, DE's mutation operator does more than just introduce small random perturbations; it is the primary driver for generating new trial vectors [6]. The classic "rand/1" mutation strategy is defined by the following equation:
$$v{i}(t+1) = x{r1}(t) + F \cdot (x{r2}(t) - x{r3}(t))$$
Here, (v{i}(t+1)) is the resulting mutant (or donor) vector, (x{r1}, x{r2}, x{r3}) are three distinct randomly selected parent vectors from the population, and (F) is the scaling factor, a crucial hyperparameter typically in the range [0, 2] [25] [38]. This mechanism uses the scaled difference vector between two solutions to perturb a third, effectively exploring the search space along the direction of this difference [6] [38]. This process inherently adapts to the current distribution of the population, a feature that enhances its robustness across various problems [38].
Operator Mechanics and Methodologies
A Taxonomy of GA Crossover Operators
GA crossover operators are diverse and often tailored to the specific encoding of the chromosome. The following table summarizes common crossover types:
Table 1: Classification and Description of Common GA Crossover Operators
| Crossover Type | Classification | Basic Methodology | Key Characteristics |
|---|---|---|---|
| Single-Point [37] [39] | Binary/Integer | A single crossover point is selected. Genetic material to the right of this point is swapped between the two parents. | Simple but can exhibit positional bias [37]. |
| Two-Point [37] [39] | Binary/Integer | Two crossover points are selected. The genetic material between these two points is swapped between the parents. | Reduces positional bias compared to single-point. |
| Multi-Point [39] | Binary/Integer | Multiple crossover points are selected, and segments are swapped alternately. | Further generalizes the N-point crossover concept. |
| Uniform [34] [37] [39] | Binary/Integer | Each gene (bit) in the offspring is chosen independently from one of the corresponding genes in the parents, based on a coin toss (e.g., 50% probability). | Highly disruptive, promotes diversity. |
| Uniform (with Mask) [37] [39] | Binary/Integer | A predefined crossover mask (a string of 0s and 1s) determines which parent contributes to each gene position in the offspring. | Offers more control over the mixing process. |
| Partially Mapped (PMX) [39] | Permutation-based | Designed for ordering problems (e.g., TSP). Swaps two subsequences between parents and uses a mapping to legalize the offspring and avoid duplicate genes. | Preserves absolute positions from parents. |
| Cycle (CX) [39] | Permutation-based | Identifies a "cycle" of alleles between parents. The offspring is created by exchanging the alleles in this cycle between the two parents. | Preserves the relative ordering of elements. |
| Arithmetic [39] | Real-valued | Creates offspring as a weighted arithmetic combination of parent vectors: ( \text{Offspring} = \alpha \cdot P1 + (1-\alpha) \cdot P2 ). | Produces offspring that are intermediate to parents. |
The following diagram illustrates the logical workflow for selecting and applying a crossover operator within a GA:
The Differential Mutation Mechanism in DE
In DE, the process of generating a new trial vector is a multi-stage process that critically relies on differential mutation. The standard DE workflow ("DE/rand/1/bin") is as follows:
- Mutation: For each target vector (xi(t)) in the population, a mutant vector (vi(t+1)) is generated using the equation in Section 2.2 [38].
- Crossover: The mutant vector (vi(t+1)) and the target vector (xi(t)) undergo a crossover operation (typically binomial) to produce a trial vector (u_i(t+1)). This crossover is controlled by the Crossover Rate (CR), which determines the proportion of parameters inherited from the mutant vector versus the target vector [38]. A random dimension is often forced to come from the mutant vector to ensure the solution changes.
- Selection: The fitness of the trial vector (ui(t+1)) is compared to that of the target vector (xi(t)). The superior one survives to the next generation [38].
It is vital to distinguish DE's crossover from GA's crossover. In DE, crossover acts as a supplementary operator that mixes the mutant and target vectors, whereas differential mutation is the primary innovation engine. The following diagram details this integrated process:
Comparative Analysis: Performance and Applications
Quantitative Comparison of Operator Characteristics
The following table provides a structured, quantitative comparison of the two operators across several key dimensions relevant to optimization performance.
Table 2: Quantitative and Qualitative Comparison of GA Crossover and DE Differential Mutation
| Characteristic | GA Crossover | DE Differential Mutation |
|---|---|---|
| Primary Role | Combining existing genetic material (exploitation) [34] [37]. | Generating new directions for exploration using vector differences (exploration) [6] [38]. |
| Typical Encoding | Binary, Integer, Permutation [34] [37]. | Real-valued vectors (floating-point) [6] [38]. |
| Key Hyperparameters | Crossover Rate (CR) - Probability of performing crossover [34] [40]. | Scaling Factor (F) - Controls the magnitude of the differential variation [38] [41]. |
| Parameter Sensitivity | Performance is highly sensitive to the chosen CR and mutation rate [40]. | Performance is highly sensitive to the values of F and CR [38]. |
| Population Diversity | Can be highly disruptive (e.g., uniform crossover), but may lose diversity if selection pressure is too high [37]. | Inherently maintains diversity through its difference-vector-based exploration, which adapts to the population's spread [6]. |
| Exploration vs. Exploitation | Tends to favor exploitation by recombining existing good solutions [34]. | Tends to be a strong exploration mechanism, especially in early generations [6] [38]. |
| Convergence Behavior | Can suffer from premature convergence if diversity is lost [6]. | Known for its strong and robust convergence properties on continuous problems, but can stagnate or converge prematurely on complex problems [6] [38]. |
Experimental Protocols and Performance Evaluation
To empirically compare these operators, researchers typically embed them within their respective algorithms (GA and DE) and run them on a suite of benchmark optimization functions. The following are standard experimental protocols:
1. Benchmark Testing Protocol:
- Objective: To compare the convergence accuracy and speed of GA and DE on standard test functions.
- Methodology:
- Select a set of benchmark functions (e.g., 26 functions as in [38]) including unimodal, multimodal, and noisy landscapes.
- For GA: Implement a standard GA with a selection operator (e.g., tournament or roulette wheel), a crossover operator (e.g., two-point or uniform with a defined CR), and a mutation operator (with a low mutation rate, e.g., 0.01-0.3 [34] [40]).
- For DE: Implement a standard DE/rand/1/bin algorithm [38].
- Metrics: Record the mean and standard deviation of the best-found solution over multiple independent runs, the number of function evaluations to reach a target fitness, and the success rate.
2. Parameter Sensitivity Analysis Protocol:
- Objective: To evaluate the robustness of each algorithm to its control parameters.
- Methodology:
- For GA: Vary the crossover rate (e.g., from 0.5 to 0.9 [40]) and the mutation rate (e.g., from 0.1 to 0.3 [40]) in a grid search. Measure performance on a selected benchmark.
- For DE: Vary the scaling factor F (e.g., from 0.4 to 0.9) and the crossover rate CR (e.g., from 0.1 to 0.9) in a similar grid search [38].
- Metrics: Generate performance heatmaps or conduct ANOVA to determine the significance of each parameter's effect.
Recent Findings: A 2025 study [38] highlighted that the inherent parameter sensitivity of DE can be mitigated by integrating a reinforcement learning-based dynamic parameter adjustment mechanism. This approach allows the scaling factor (F) and crossover rate (CR) to be adapted online during the evolution process, significantly enhancing global optimization performance and overcoming premature convergence issues.
The Scientist's Toolkit: Research Reagents & Materials
For researchers, particularly in drug development, looking to implement and experiment with these algorithms, the following table lists essential "research reagents" – the key components and tools needed.
Table 3: Essential Materials and Tools for Implementing GA and DE
| Item / Component | Function / Description | Relevance to GA / DE |
|---|---|---|
| Population of Candidate Solutions | A set of potential solutions to the optimization problem, which is iteratively improved. | The fundamental "substrate" upon which both GA and DE operate [25] [38]. |
| Fitness Function | A user-defined function that quantifies the quality or performance of a candidate solution. | The "environmental pressure" that guides the evolution in both algorithms [34]. Critical for drug development (e.g., binding affinity score). |
| Encoding / Representation Scheme | The method of mapping a real-world problem (e.g., a molecular structure) to a chromosome. | GA: Binary, integer, permutation. DE: Typically real-valued vectors [6]. |
| Selection Operator | A mechanism (e.g., roulette, tournament) to choose parent solutions based on their fitness. | Used in both algorithms to promote the propagation of good genes [25] [34]. |
| Crossover Operator (GA) | Recombines two parent chromosomes to create offspring. | The primary operator for creating new solutions in GA (e.g., single-point, uniform) [37] [39]. |
| Differential Mutation Operator (DE) | Generates a new vector by adding a scaled difference vector to a base vector. | The primary driver for exploration and new solution creation in DE [6] [38]. |
| Crossover Operator (DE) | Mixes the mutant vector with the target vector to produce the final trial vector. | A secondary operator in DE, often binomial or exponential, controlled by CR [38]. |
| Hyperparameters (F, CR, etc.) | Algorithmic parameters that control the behavior of the operators and require tuning. | GA: Crossover Rate, Mutation Rate. DE: Scaling Factor (F), Crossover Rate (CR). Performance is highly sensitive to these [38] [40]. |
| Benchmark Problems / Datasets | Standardized problems (e.g., Sphere, Rosenbrock, Rastrigin) or domain-specific datasets. | Essential for validating and comparing the performance of different algorithm configurations [38] [41]. |
In conclusion, the crossover operator in Genetic Algorithms and the differential mutation operator in Differential Evolution serve fundamentally different roles, despite both being core to their respective evolutionary paradigms. GA Crossover is fundamentally a recombinative operator, designed to exploit and mix promising genetic material from parents. In contrast, DE's Differential Mutation is an explorative, generative operator that uses the geometry of the population to direct its search, making it particularly well-suited for optimization in continuous spaces.
For the drug development researcher, this comparison offers clear guidance. GA, with its flexible representation, can be adeptly applied to combinatorial problems like molecular design or feature selection. DE, with its robust performance on real-valued problems and strong convergence characteristics, is often a superior choice for continuous parameter optimization, such as fine-tuning kinetic parameters in pharmacokinetic models or optimizing continuous descriptors in quantitative structure-activity relationship (QSAR) models. The choice of algorithm—and the consequent reliance on its core operator—should be a deliberate decision informed by the nature of the problem's search space.
The fundamental distinction between Genetic Algorithms (GAs) and Differential Evolution (DE) begins with how they represent potential solutions to optimization problems. This representation choice profoundly influences their application domains, operational mechanisms, and eventual performance. GAs typically employ discrete representations—binary strings or integers—that mimic biological chromosomes, requiring problem-specific encoding and decoding schemes to map between genotype and phenotype spaces [42] [26]. In contrast, DE operates directly on continuous real-number vectors that naturally represent parameters in many engineering and scientific problems without requiring transformation [13] [32].
These representation differences stem from each algorithm's philosophical origins. GAs draw inspiration from Mendelian genetics, where discrete genes combine to create new individuals [26] [29]. DE, while still evolutionary, emphasizes a different approach where continuous vector mathematics drives the search process [13] [14]. For researchers and drug development professionals, understanding this core distinction is crucial for selecting the appropriate algorithm for specific problem types, whether optimizing discrete drug compounds or continuous dosage parameters.
Genetic Algorithms: Discrete Representation Schemes
Binary Representation
Binary representation constitutes the most traditional encoding scheme for genetic algorithms, where candidate solutions are represented as strings of bits (0s and 1s) [26] [29]. Each bit in the string functions analogously to a biological gene, and the complete string forms a chromosome representing a potential solution [43]. This representation creates a genotype-phenotype mapping where the binary genotype must be decoded into a meaningful phenotypic solution for fitness evaluation [42].
The decoding process depends on the problem domain. For continuous parameter optimization, binary strings are typically converted to real numbers within specified bounds using either standard base-2 encoding or Gray coding [42]. Gray coding provides an advantage by ensuring that adjacent integer values differ by only a single bit, creating a smoother neighborhood structure that often facilitates better search performance [42]. For instance, while the numbers 15 and 16 have significantly different binary representations (01111 vs. 10000), their Gray encoded values (01000 vs. 11000) differ by only one bit [42].
Implementation Example: In a typical implementation, a binary-coded GA might represent a solution to a multi-parameter optimization problem as a concatenated bit string, where different segments correspond to different parameters [42]. Each parameter $xi$ with lower bound $li$ and upper bound $ui$ would be encoded using a binary substring of length $Li$, providing a resolution of $(ui-li)/(2^{L_i}-1)$ [26].
Integer and Nominal Representation
Many practical optimization problems naturally involve integer or categorical variables, making integer representation particularly valuable [42]. In drug development, this might represent discrete choices between molecular structures, formulation types, or categorical experimental conditions [43]. Integer representation eliminates the need for decoding between binary and real-number spaces, potentially improving algorithm efficiency for naturally discrete problems [42].
Nominal phenotypes extend this concept to represent categorical data that lacks intrinsic ordering [42]. The IMSL C Stat Library implementation supports this through specialized handling where "each nominal phenotype is encoded into a single non-negative integer" [42]. This approach enables GAs to handle mixed variable types—continuous, integer, binary, and nominal—within a unified framework, though often requiring specialized genetic operators like partially matched crossover for nominal variables [42].
Table 1: Genetic Algorithm Representation Schemes
| Representation Type | Data Structure | Encoding Method | Common Applications |
|---|---|---|---|
| Binary | Bit strings (0s and 1s) | Base-2, Gray coding | General optimization, feature selection [26] [29] |
| Integer | Integer arrays | Direct representation | Discrete choices, indexing, counting problems [42] |
| Nominal | Integer categories | Direct representation | Categorical variables, unordered options [42] |
| Mixed | Multiple segments | Hybrid encoding | Complex problems with mixed variable types [42] |
Differential Evolution: Continuous Real-Number Representation
Direct Continuous Representation
Differential Evolution operates natively on continuous real-number vectors, making it particularly suited for optimization problems in continuous domains [13] [32]. In DE, each candidate solution is represented as a D-dimensional vector $xi = [x{i,1}, x{i,2}, ..., x{i,D}]$ where each component represents a parameter value in the problem space [13]. This direct representation eliminates the need for encoding and decoding steps, allowing the algorithm to manipulate solutions in the same space where fitness is evaluated [32].
The continuous representation provides several advantages for real-valued optimization. It avoids discretization errors that can occur in binary-coded GAs and maintains the natural continuity and differentiability properties of the parameter space [13]. For drug development professionals, this approach naturally fits continuous parameters such as dosage levels, concentration values, temperature conditions, and time points [14].
Vector Operations and Search Mechanism
DE's representation scheme enables unique search mechanisms based on vector differences. The fundamental operation in DE is the mutation strategy, which creates donor vectors by combining scaled differences between population members [13] [32]. The classic DE/rand/1 binomial mutation strategy follows:
$$v{i} = x{r1} + F \cdot (x{r2} - x{r3})$$
Where $x{r1}$, $x{r2}$, and $x{r3}$ are distinct population vectors, and $F$ is the scaling factor controlling the magnitude of the differential variation [13]. This vector-based approach directly leverages the continuous representation to explore the search space, with difference vectors $(x{r2} - x_{r3})$ automatically adapting to the local fitness landscape [14] [32].
The continuous crossover operation further maintains solution feasibility through either binomial or exponential recombination, creating trial vectors by mixing components from target and donor vectors [13]. The binomial crossover follows:
$$u{i,j} = \begin{cases} v{i,j} & \text{if } rand(0,1) \leq CR \text{ or } j = j{rand} \ x{i,j} & \text{otherwise} \end{cases}$$
Where $CR$ is the crossover probability controlling parameter exchange, and $j_{rand}$ ensures at least one component comes from the donor vector [32].
Comparative Analysis: Performance and Applications
Algorithmic Workflows
The representation differences between GAs and DE yield distinct algorithmic workflows. The following diagrams illustrate these contrasting processes:
GA Workflow: Discrete Representation
DE Workflow: Continuous Representation
Performance Characteristics and Applications
The representation differences lead to distinct performance profiles for each algorithm. GAs with binary representation excel in problems with naturally discrete structure or mixed variable types, while DE typically demonstrates superior performance on continuous, real-valued optimization problems [13] [26] [32].
Table 2: Performance Comparison Based on Representation
| Characteristic | Genetic Algorithms (Binary/Integer) | Differential Evolution (Continuous) |
|---|---|---|
| Natural Domain | Discrete, combinatorial spaces [26] | Continuous parameter spaces [13] |
| Encoding Overhead | Requires encoding/decoding [42] | Direct representation [32] |
| Parameter Control | Mutation rate, crossover rate, population size [26] | Scaling factor F, crossover rate CR [13] |
| Local Search | May require specialized operators [26] | Self-adapting through vector differences [14] |
| Constraint Handling | Often requires special techniques [26] | Relatively straightforward via projection [13] |
For drug development applications, each algorithm fits different problem types. GAs with integer representation naturally model selection problems, such as choosing optimal combinations of drug candidates from large libraries or optimizing experimental designs with discrete factor levels [43]. DE's continuous representation excels in optimizing continuous parameters such as dosage concentrations, reaction conditions, or kinetic parameters in pharmacokinetic modeling [14].
Implementation Protocols for Researchers
Genetic Algorithm Protocol for Discrete Optimization
Objective: Solve discrete optimization problems using binary/integer representation Initialization:
- Define solution representation: Determine whether binary or integer encoding better fits the problem structure [42]
- Set population size: Typically hundreds to thousands of individuals, problem-dependent [26]
- Initialize population: Generate random individuals within feasible ranges [29]
Evolutionary Cycle:
- Evaluation: Decode each individual to its phenotypic representation and compute fitness [42]
- Selection: Apply selection operator (tournament, roulette wheel, etc.) to choose parents [26]
- Crossover: Implement appropriate crossover (single-point, multi-point, uniform) with probability 0.6-0.9 [29]
- Mutation: Apply mutation operator with low probability (0.001-0.01) to maintain diversity [26]
- Elitism: Preserve best individuals unchanged between generations [29]
Termination: Continue for fixed generations or until convergence criteria met [26]
Differential Evolution Protocol for Continuous Optimization
Objective: Solve continuous optimization problems using real-number vector representation Initialization:
- Define parameter bounds: Set lower and upper limits for each dimension [32]
- Set population size: NP = 5-10 times the problem dimension [13]
- Initialize population: Generate random vectors uniformly distributed within bounds [32]
Evolutionary Cycle:
- Mutation: For each target vector $x_i$, generate donor vector using differential mutation [13]
- Crossover: Create trial vector by combining target and donor vectors [32]
- Selection: Greedily select between target and trial vectors based on fitness [13]
Parameter Settings:
Termination: Continue until maximum iterations or fitness stagnation [14]
Table 3: Research Reagent Solutions for Evolutionary Algorithm Implementation
| Tool/Resource | Function | Application Context |
|---|---|---|
| DEAP (Python Framework) | Rapid prototyping of evolutionary algorithms | Implementing custom GA/DE variants [32] |
| ALGLIB Numerical Library | Robust implementation of optimization algorithms | Production-level GA/DE deployment [32] |
| IMSL C Stat Library | Commercial-grade numerical analysis | High-performance scientific applications [42] |
| Gray Encoding Scheme | Adjacent integer representation | Improving binary-coded GA performance [42] |
| Parameter Tuning Protocols | Systematic parameter optimization | Algorithm performance maximization [13] [26] |
The choice between binary/integer GA representation and continuous DE representation fundamentally shapes optimization approach and potential success. For researchers and drug development professionals, selection guidelines emerge from problem structure: GAs with discrete representation suit problems with inherent combinatorial structure, feature selection, or mixed variable types, while DE with continuous representation excels in real-valued parameter optimization, especially with noisy, non-differentiable, or multimodal objective functions [13] [26] [32].
Hybrid approaches represent a promising direction, potentially leveraging discrete representation for structure selection and continuous representation for parameter refinement within unified frameworks. As evolutionary algorithms continue advancing, understanding these fundamental representation differences provides researchers with principled foundations for selecting appropriate methodologies for specific optimization challenges in drug development and scientific research.
Evolutionary Algorithms (EAs) represent a sophisticated class of meta-heuristic optimization methods that emulate processes of biological evolution. By utilizing mechanisms such as selection, mutation, and crossover, these algorithms effectively tackle complex optimization challenges across various domains, particularly in computational biology and drug discovery. Their inherent adaptability allows them to respond efficiently to dynamic changes in problem landscapes, continuously evolving toward optimal solutions. Within this domain, Genetic Algorithms (GAs) and Differential Evolution (DE) have emerged as powerful, population-based approaches with distinct strengths and characteristics [25].
The adoption of these methods is largely driven by their efficacy in addressing problems that traditional static methodologies struggle to solve, especially in high-dimensional, non-differentiable, or noisy search spaces common in real-world scientific applications. As computational power has advanced alongside the rise of big data, deep neural networks and evolutionary computing algorithms have achieved remarkable success in fields ranging from pharmaceutical research to materials science [25]. This technical guide examines the application scenarios of GAs and DE across three critical domains—drug design, hyperparameter optimization, and molecular generation—providing researchers with practical insights for selecting and implementing these algorithms within their computational workflows.
Core Algorithmic Foundations: GA vs. DE
Genetic Algorithm Fundamentals
Genetic Algorithms operate on a population of candidate solutions, applying principles inspired by natural selection to evolve increasingly optimal solutions over generations. The algorithm begins with initialization of a population, typically with random solutions, though strategic initialization can significantly improve convergence times [25]. Each solution is encoded as a "chromosome"—often represented as binary strings, floating-point vectors, or other structured representations depending on the problem domain.
Key genetic operators include:
- Selection: Favors fitter individuals to pass their genetic material to subsequent generations. Common strategies include tournament selection and roulette wheel selection, with tournament selection generally demonstrating better performance in comparative studies [27].
- Crossover: Recombines genetic material from parent solutions to produce offspring, enabling the exploration of new regions in the search space.
- Mutation: Introduces random changes to maintain population diversity and prevent premature convergence to local optima.
The fitness function evaluates solution quality, guiding the evolutionary process toward optimal regions of the search space [25]. Research demonstrates that floating-point representations often yield better performance compared to binary representations for continuous optimization problems [25].
Differential Evolution Fundamentals
Differential Evolution shares conceptual similarities with GAs but employs distinct strategies for mutation and recombination. A fundamental difference lies in DE's operation sequence, where mutation acts as the primary operator before crossover, contrasting with the GA approach where crossover typically occurs first [27].
The characteristic DE mutation strategy "DE/rand/1" generates donor vectors for each target vector in the population using weighted differences between randomly selected population members:
V_i = X_r1 + F × (X_r2 - X_r3)
Where:
V_iis the donor vector for the i-th target vectorX_r1,X_r2,X_r3are distinct randomly selected population membersFis the scaling factor controlling amplification of differential variations [27]
Following mutation, crossover incorporates components from the donor vector into the target vector, producing a trial vector. Finally, selection determines whether the trial or target vector survives to the next generation based on fitness evaluation [27]. This differential mutation mechanism provides DE with strong exploration capabilities and often faster convergence on continuous optimization problems.
Comparative Analysis: Performance Characteristics
Table 1: Comparative Analysis of Genetic Algorithm vs. Differential Evolution
| Characteristic | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Primary Operation Sequence | Selection → Crossover → Mutation | Mutation → Crossover → Selection |
| Exploration Capability | Moderate, highly dependent on parameter tuning | Strong, inherent in differential mutation |
| Parameter Sensitivity | High (requires tuning of multiple parameters) | Moderate (fewer control parameters) |
| Convergence Speed | Variable, can stagnate with poor parameter choices | Generally fast on continuous problems |
| Local Optima Avoidance | Good with proper diversity maintenance | Excellent due to differential exploration |
| Discrete Problem Handling | Native support through chromosome encoding | Requires specialized discrete variants |
| Implementation Complexity | Moderate | Low to Moderate |
Statistical analyses from nuclear engineering applications reveal that DE demonstrates stronger robustness in approaching global optima, with GAs experiencing local optima trapping in approximately 26% of runs in one comparative study [27]. However, well-tuned GAs can occasionally discover superior final solutions, suggesting potential benefits for hybrid approaches or algorithm selection based on specific problem characteristics.
Application Scenario 1: Drug-Target Binding Affinity Prediction
Algorithm Implementation in Drug Discovery
Drug-target binding affinity prediction represents a critical regression task in computer-aided drug design, where accurate prediction of binding strength can significantly accelerate drug discovery pipelines. Traditional machine learning approaches have been limited by binary classification frameworks and insufficient negative samples. The CSAN-BiLSTM-Att model (Convolution Self-Attention Network with Attention-based Bidirectional Long Short-Term Memory Network) exemplifies how hybrid deep learning architectures combined with evolutionary optimization can advance this field [16].
This sophisticated architecture integrates convolutional neural network blocks with self-attention mechanisms to process protein and ligand representations, followed by attention-based BiLSTM layers for temporal feature capture and fully connected layers for final affinity prediction. The model's complexity necessitates careful hyperparameter tuning to achieve optimal performance, making it an ideal application for evolutionary optimization approaches [16].
Differential Evolution for Hyperparameter Optimization
The implementation of Differential Evolution for hyperparameter optimization in this domain follows a structured workflow:
Solution Representation: Each individual in the DE population encodes critical hyperparameters including learning rate, batch size, number of CNN filters, LSTM units, and attention dimensions as a multidimensional vector.
Fitness Evaluation: The fitness function trains the CSAN-BiLSTM-Att model with the proposed hyperparameters and evaluates performance on validation data using the Concordance Index (CI) metric, which measures ranking accuracy of predicted binding affinities.
Evolutionary Process: DE applies mutation and crossover operations to explore the hyperparameter space, systematically evolving toward configurations that maximize predictive performance [16].
Experimental results demonstrate this DE-optimized approach achieves state-of-the-art performance with a concordance index of 0.898 and mean square error of 0.228 on the DAVIS dataset, and 0.971 concordance with 0.014 MSE on the KIBA dataset [16].
Research Reagent Solutions
Table 2: Essential Research Materials for Drug-Target Affinity Prediction
| Resource/Reagent | Function/Application | Implementation Example |
|---|---|---|
| DAVIS Dataset | Provides quantitative binding affinity measurements (Kd values) for kinase inhibitor compounds | Benchmark dataset for model training and validation |
| KIBA Dataset | Offers kinase inhibitor bioactivity scores integrating multiple sources | Secondary validation dataset for generalization assessment |
| SMILES Representations | Standardized molecular string representations for chemical structures | Encoding ligand molecules for model input |
| Protein Sequences | Primary amino acid sequences of target proteins | Encoding target proteins for model processing |
| 3D Structural Data | Crystallographic protein structures when available | Optional input for structure-aware models |
Application Scenario 2: Hyperparameter Optimization for Deep Learning Models
Genetic Algorithm Framework Implementation
Hyperparameter optimization presents a significant challenge in developing effective deep learning models for scientific applications, with traditional methods like grid search exhibiting poor scalability and random search lacking evolutionary direction. Genetic algorithms provide a powerful alternative for navigating complex, high-dimensional hyperparameter spaces [44] [45].
The GA implementation for hyperparameter optimization follows these key steps:
Chromosome Encoding: Each individual in the GA population represents a complete set of hyperparameters as a chromosome, encoding parameters including learning rate, batch size, number of layers, layer-specific parameters (e.g., filters, units), activation functions, dropout rates, and optimization algorithm settings [45].
Fitness Evaluation: The fitness function trains the target deep learning model with the proposed hyperparameters and evaluates performance on a validation set. For classification tasks, this typically uses accuracy or F1-score, while side-channel attack applications employ success rate (SR) and guessing entropy (GE) as specialized evaluation metrics [45].
Genetic Operators: Tournament selection identifies parents for reproduction, while multi-point crossover combines hyperparameters from parent configurations. Mutation introduces variations through random modifications of hyperparameter values within defined ranges [45].
Experimental Protocol and Performance Metrics
In comparative studies evaluating protected AES implementations, the GA-based hyperparameter optimization framework achieved 100% key recovery accuracy across test cases, significantly outperforming random search baselines (70% accuracy) [45]. The method demonstrated competitive performance against Bayesian optimization and tree-structured Parzen estimators, achieving top performance in 25% of test cases and ranking second overall.
The experimental protocol for such evaluations includes:
- Dataset Partitioning: Separate profiling (training) and attack (testing) datasets
- Multiple Independent Runs: 50+ independent GA runs to ensure statistical significance
- Comparative Baselines: Performance comparison against grid search, random search, and Bayesian optimization
- Convergence Monitoring: Tracking fitness improvement across generations to assess optimization efficiency [45]
Algorithm Selection Guidelines
Table 3: Hyperparameter Optimization Method Comparison
| Optimization Method | Search Strategy | Computation Cost | Scalability | Best Use Cases |
|---|---|---|---|---|
| Grid Search | Exhaustive parameter sweeping | High | Low | Small parameter spaces (<5 parameters) |
| Random Search | Stochastic sampling | Medium | Medium | Moderate spaces with limited budget |
| Bayesian Optimization | Probabilistic model-based | High | Low-Medium | Expensive evaluations, continuous spaces |
| Genetic Algorithm | Evolutionary population-based | Medium-High | High | Complex, mixed parameter types |
| Differential Evolution | Differential mutation-based | Medium-High | High | Continuous parameter optimization |
Research indicates that GAs particularly excel in scenarios with mixed parameter types (continuous, discrete, categorical) and complex, non-differentiable search landscapes where gradient-based methods cannot be applied [44]. The global search capability of GAs helps avoid local minima convergence, a common challenge with greedy search strategies.
Application Scenario 3: Molecular Generation and Optimization
Synthesis-Aware Genetic Algorithm (SynGA)
Molecular generation represents a cornerstone application of evolutionary algorithms in drug discovery, with synthesizability emerging as a critical constraint for practical deployment. The SynGA (Synthesizable Genetic Algorithm) framework addresses this challenge by operating directly on synthesis routes rather than molecular structures, ensuring generated molecules remain synthesizable by construction [46].
The algorithm employs custom genetic operators designed around synthetic chemistry principles:
- Representation: Synthesis routes encoded as unordered binary trees where leaf nodes represent purchasable building blocks and internal nodes correspond to reaction applications
- Crossover: Exchanges subtrees between parent synthesis routes while maintaining synthetic feasibility
- Mutation: Modifies building blocks or reaction steps within synthetically plausible boundaries [46]
This approach contrasts with synthesis-agnostic methods that may propose chemically inaccessible structures, creating a significant barrier to real-world adoption. By embedding synthetic constraints directly into the evolutionary process, SynGA generates molecules with explicitly defined synthesis pathways using standard laboratory protocols [46].
Hybrid GPT-GA Framework (CCMol)
The Compound Construction Model (CCMol) exemplifies hybrid approaches integrating deep learning generative models with evolutionary optimization. This innovative framework leverages the complementary strengths of Generative Pretrained Transformers (GPT) for initial molecular generation and Genetic Algorithms for iterative property optimization [47].
The CCMol workflow implements:
- Initial Generation: GPT model generates diverse molecular structures conditioned on target protein constraints
- Evolutionary Optimization: GA optimizes generated molecules for improved physicochemical properties, binding affinity, and synthetic accessibility
- Multi-objective Fitness: Evaluation incorporates drug-likeness metrics, structural diversity, and target-specific activity predictions [47]
Experimental validation against three disease-related targets (GLP1, WRN, and JAK2) demonstrated CCMol's competitive performance with current advanced models, with particular strengths in structural diversity and drug-related property optimization [47].
Paddy Field Algorithm for Chemical Optimization
The Paddy field algorithm (PFA) represents a biologically-inspired evolutionary approach distinct from traditional GAs and DE, modeling plant reproductive strategies through a five-phase process: sowing, selection, seeding, pollination, and propagation [9]. Benchmarking against multiple optimization approaches including Bayesian optimization, evolutionary algorithms, and GAs demonstrated Paddy's robust versatility across mathematical and chemical optimization tasks [9].
Key advantages of Paddy for molecular optimization include:
- Density-Based Reinforcement: Solution propagation considers both fitness and population density
- Early Convergence Resistance: Maintains exploration capability to bypass local optima
- Chemical Compatibility: Effective sampling of discrete experimental spaces common in chemical applications [9]
Comparative Analysis and Selection Guidelines
Performance Benchmarking
Empirical evaluations across domains provide practical insights for algorithm selection. In nuclear engineering applications for in-core fuel management optimization, comprehensive statistical analysis using Kruskal-Wallis and Mann-Whitney tests revealed that DE and GA with tournament selection performed significantly better than GA with roulette wheel selection [27]. DE demonstrated particular strength in exploration efficiency and consistency, successfully approaching global optima in most runs, while GAs experienced local optima trapping in approximately 26% of executions [27].
For molecular design tasks, synthesis-aware GAs have demonstrated state-of-the-art performance in benchmark studies, particularly when enhanced with machine learning-guided building block filtering [46]. The hybrid SynGBO approach, which integrates SynGA with Bayesian optimization, achieved sample-efficient property optimization for both 2D and 3D molecular objectives [46].
Algorithm Selection Framework
Selection between GAs, DE, and hybrid approaches should consider these key factors:
Problem Constraints: DE excels for continuous parameter optimization, while GAs offer greater flexibility for mixed parameter types including discrete and categorical variables [27] [45].
Synthesizability Requirements: For molecular generation, synthesis-aware GAs provide explicit constraint handling, while projection-based methods require additional model training [46].
Computational Budget: DE often converges faster on continuous problems, while GAs may produce superior final solutions with sufficient generations [27].
Implementation Complexity: Basic DE implementations require fewer control parameters than GAs, potentially reducing development and tuning effort [27].
Hybrid Potential: Both GAs and DE effectively integrate with machine learning models, either as outer-loop optimizers or through learned genetic operators [46] [45].
Genetic Algorithms and Differential Evolution offer powerful, complementary approaches for optimization challenges in drug discovery and molecular sciences. GA flexibility proves valuable for complex search spaces with mixed parameter types and explicit constraints, while DE demonstrates consistent performance and strong exploration capabilities for continuous optimization problems. The emerging trend of hybrid approaches, integrating evolutionary algorithms with deep learning architectures like GPT and specialized neural networks, creates exciting opportunities for enhanced optimization across the drug development pipeline. As automated experimentation platforms advance, these evolutionary strategies will play increasingly critical roles in accelerating scientific discovery while ensuring practical constraints like synthesizability remain central to molecular design processes.
Navigating Practical Challenges: Parameter Tuning and Avoiding Common Pitfalls
For researchers, scientists, and drug development professionals venturing into evolutionary computation, understanding the critical control parameters of Genetic Algorithms (GA) and Differential Evolution (DE) is fundamental. Both algorithms belong to the broader class of evolutionary algorithms but are distinguished by their unique operational mechanisms and parameter sensitivities. The performance, efficiency, and ultimate success of these algorithms in solving complex optimization problems—from drug molecule design to protein folding—are profoundly governed by the careful configuration of three core parameters: population size, mutation rate (or scale factor in DE), and crossover rate. This guide provides an in-depth technical examination of these parameters, offering a structured comparison and evidence-based protocols for parameter tuning to empower beginners in making informed decisions for their research applications.
Algorithm Fundamentals and Parameter Roles
Genetic Algorithms are stochastic search techniques inspired by the principles of biological evolution and natural selection [48]. They operate on a population of potential solutions (individuals), each encoded as a string of characters (chromosomes). The algorithm proceeds through iterative cycles of evaluation (assessing solution quality via a fitness function), selection (choosing parents based on fitness), and reproduction (generating offspring via crossover and mutation) [48]. The core GA parameters directly influence this reproductive process, balancing the exploration of new solution regions with the exploitation of promising areas found.
Differential Evolution is a powerful population-based optimizer for continuous domains, known for its simplicity, robustness, and excellent convergence properties [49]. Its operation cycle shares similarities with GA—initialization, mutation, crossover, and selection—but its perturbation mechanism is distinct. DE relies on difference vectors constructed from randomly selected population individuals to guide its search, making its parameters integral to this unique exploratory process [49]. DE's efficiency has led to its successful application in various engineering and scientific domains, including image processing and chemical engineering [50] [49].
Comparative Framework: GA vs. DE
While both algorithms are population-based evolutionary strategies, they differ significantly in their operational metaphors and parameter interpretations. GA more closely mimics genetic reproduction, with a vocabulary of chromosomes, genes, and alleles, and its parameters are tuned to preserve and combine beneficial genetic material [6] [48]. DE's correspondences are less exact, focusing on a differential mutation process that uses real-number vectors and distance-and-direction-based perturbation to explore the solution space [6] [49]. This fundamental distinction dictates their differing parameter sensitivities and tuning strategies.
Deep Dive into Control Parameters
Population Size (NP)
Role and Mechanism:
Population size (NP) determines the number of candidate solutions in each generation. It critically affects the balance between exploration (searching new areas) and exploitation (refining existing solutions) [51]. An inadequate small population may lead to premature convergence toward sub-optimal solutions due to insufficient genetic diversity [51]. Conversely, an excessively large population enhances diversity but drastically increases computational costs and may waste resources without commensurate performance gains [51].
GA-Specific Considerations:
In GA, the optimal population size can be influenced by the chosen encoding scheme. A crude scaling law based on binary coding suggests a size of 2^(length/chromsize), where length is the number of binary bits per individual and chromsize is the average schema size of interest, though this is often considered overkill [52]. For specific problem types like the Traveling Salesman Problem (TSP), empirical studies have shown that dynamic population sizing can be beneficial, with smaller populations sometimes outperforming larger ones [53].
DE-Specific Considerations:
DE performance is highly sensitive to NP [51]. Conventional guidelines often suggest setting NP as a function of problem dimensionality (e.g., NP = 10 * D, where D is the number of dimensions), but recent research questions this linear relationship, indicating a more complex, nonlinear dependency [51]. The influence of NP also interacts significantly with other DE parameters, namely the scale factor (F) and crossover rate (CR) [51].
Table 1: Population Size Guidelines and Trade-offs
| Algorithm | General Guidelines | Too Small | Too Large | Common Adaptive Strategies |
|---|---|---|---|---|
| Genetic Algorithm (GA) | DeJong: 50 [52]Grefenstette: 30 [52]Can be problem-encoding dependent. | Loss of diversity, premature convergence [48]. | Increased computational cost, slow convergence [51]. | Dynamic Decreasing/Increasing methods (DHM/ILC, ILM/DHC) [53]. Restart upon convergence [52]. |
| Differential Evolution (DE) | Often 5-10 × problem dimension (D), but this is debated [51]. A common start is 50-100. | High risk of premature convergence, stagnation [51]. | Wasted computational resources, slow progress per generation [51]. | Linear decrease strategies [51]. Success-rule based increase/decrease [51]. |
Mutation Rate (p_m) and Scale Factor (F)
Role and Mechanism: This parameter controls the introduction of new genetic material or exploratory moves.
- In GA, the mutation rate (
p_m) is typically a low probability (e.g., per bit or per gene) that randomizes a portion of an offspring's encoding, helping to escape local optima and restore lost diversity [52] [48]. - In DE, the scale factor (
F) is a real-valued parameter (typically [0, 2]) that controls the magnitude of the differential variation. It weights the difference vector during mutation, directly governing the step size in the search space [50] [49]. A largerFpromotes exploration, while a smallerFfavors exploitation.
GA-Specific Considerations:
Standard settings for p_m are often very low. DeJong recommended a per-bit rate of 0.001, while Grefenstette suggested 0.01 [52]. A theoretical argument proposes a rate of approximately 1/L (where L is the genotype length) to expect about one mutation per offspring [52]. Exceedingly high mutation rates can transform the search into a random walk, while rates that are too low may fail to prevent premature convergence [48].
DE-Specific Considerations:
The scale factor F is crucial for DE's performance. The algorithm possesses an implicit self-adaptation, but this can lead to stagnation—where the population fails to improve despite having diversity—if the available step sizes are ineffective [50]. Research indicates that the optimal F may not only be problem-dependent but also vary during the optimization process, motivating time-varying and adaptive schemes [50] [38]. Randomization of F (e.g., using a normal or uniform distribution for each vector or generation) has proven beneficial in enriching the set of search moves and reducing stagnation risk [50].
Table 2: Mutation (GA) / Scale Factor (DE) Guidelines
| Parameter | Standard Settings | Effect if Too Low | Effect if Too High | Advanced Adaptive Methods |
|---|---|---|---|---|
GA Mutation Rate (p_m) |
DeJong: 0.001 [52]Grefenstette: 0.01 [52] | Trapping in local optima, loss of diversity [48]. | Degeneration to random search, disruption of good building blocks [48]. | Dynamic control based on population diversity or generation number [53]. |
DE Scale Factor (F) |
Common: 0.5 [49]Range: [0.4, 1.0] is typical. | Limited exploration, high stagnation risk [50]. | Overshooting, oscillation, difficulty converging [38]. | Time-varying decrease [50], Randomization (dither/jitter) [50], Reinforcement Learning-based policy networks [38]. |
Crossover Rate (p_corCR)
Role and Mechanism: Crossover promotes the recombination of genetic information between parent solutions.
- In GA, the crossover rate (
p_c) is the probability that two parents will undergo crossover to produce offspring (otherwise, offspring are clones of parents). It facilitates the mixing of beneficial building blocks (schemata) [53] [52]. - In DE, the crossover rate (
CR) determines the probability that a parameter (gene) for the trial vector will be copied from the mutant vector as opposed to the target vector [49]. ACRof 1 means the trial vector is a copy of the mutant vector, while aCRof 0 means it is a copy of the target vector (except for at least one randomly chosen parameter guaranteed to come from the mutant vector).
GA-Specific Considerations:
DeJong recommended a p_c of 0.6, while Grefenstette used 0.9 [52]. The optimal rate depends on the crossover type; more disruptive operators like uniform crossover may require lower rates (e.g., ~0.5) [52]. Recent research explores dynamic control, starting with a high mutation/low crossover ratio and linearly transitioning to a low mutation/high crossover ratio (DHM/ILC), or vice versa (ILM/DHC), showing effectiveness on TSP problems [53].
DE-Specific Considerations:
CR controls the alignment between the trial vector and the mutant vector. Higher values (CR → 1) promote the exploration of new directions dictated by the mutation, while lower values (CR → 0) favor a more conservative exploitation of the existing target vector [49]. Like F, the optimal CR is problem-sensitive, and adaptive mechanisms have been developed. A common static value is 0.9, but adaptive strategies often adjust it dynamically based on success history [38].
Table 3: Crossover Rate Guidelines for GA and DE
| Algorithm | Standard Settings | Effect if Too Low | Effect if Too High | Advanced Adaptive Methods |
|---|---|---|---|---|
GA Crossover Rate (p_c) |
DeJong: 0.6 [52]Grefenstette: 0.9 [52] | Limited mixing of schemata, reliance on mutation. | Excessive disruption of good parent solutions. | Dynamic Increasing of Low Crossover (DHM/ILC) [53]. |
DE Crossover Rate (CR) |
Common: 0.9 [49]Range: [0.1, 1.0] | Trial vector is too similar to target, slow progress. | Loss of information from the target vector, reduced stability. | Self-adaptive schemes [49], Reinforcement Learning control [38]. |
Experimental Protocols and Parameter Tuning
Standard Parameter Settings for Baseline Performance
Establishing a baseline is crucial. The following are historically significant and widely used parameter sets.
For Genetic Algorithms:
- DeJong Settings (Function Optimization): Population=50, Generations=1000, Crossover Rate=0.6 (one/two-point), Mutation Rate=0.001 (per bit) [52].
- Grefenstette Settings (Computationally Expensive Fitness): Population=30, Crossover Rate=0.9, Mutation Rate=0.01 (per bit) [52].
For Differential Evolution:
- Classic DE Settings:
NP=50-100,F=0.5,CR=0.9. These provide a robust starting point for many continuous problems [49].
Methodology for Dynamic Parameter Control
Dynamic parameter adjustment has shown significant performance improvements. Below is a protocol based on published research [53].
- Experiment Name: Dynamic Control of Crossover and Mutation Ratios.
- Objective: To compare static parameter settings against dynamic linear control methods.
- Algorithms: Standard GA with two dynamic methods: DHM/ILC and ILM/DHC.
- Test Problems: Ten Traveling Salesman Problems (TSP) [53].
- Protocol:
- Baseline 1 (Fifty-Fifty): Run GA with fixed 50% crossover and 50% mutation rates.
- Baseline 2 (Common Static): Run GA with fixed crossover=0.9 and mutation=0.03 [53].
- Dynamic Method 1 (DHM/ILC): Initialize mutation rate at 100% and crossover at 0%. Linearly decrease mutation and increase crossover each generation until they reach 0% and 100%, respectively, by the final generation [53].
- Dynamic Method 2 (ILM/DHC): Initialize mutation rate at 0% and crossover at 100%. Linearly increase mutation and decrease crossover each generation until they reach 100% and 0%, respectively, by the final generation [53].
- Evaluation: Compare the performance (e.g., best solution found, convergence speed) across the different methods. The study found DHM/ILC effective with small populations and ILM/DHC with large populations [53].
Methodology for Reinforcement Learning-Based DE Parameter Tuning
Reinforcement Learning (RL) offers a sophisticated framework for adaptive parameter control, as demonstrated in a 2025 study [38].
- Experiment Name: RL-enhanced Differential Evolution (RLDE).
- Objective: To dynamically adjust the scaling factor (
F) and crossover probability (CR) using a policy gradient network. - Algorithm: An improved DE algorithm (RLDE) [38].
- Test Problems: 26 standard benchmark functions and a UAV task assignment problem [38].
- Protocol:
- Initialization: Use the Halton sequence for uniform population initialization to improve the ergodicity of the initial solution set [38].
- RL Framework: The state space for the RL agent includes current population information and evolution state. The actions are adjustments to
FandCR. The reward is based on the improvement in fitness. - Parameter Adjustment: The policy gradient network outputs new values for
FandCRfor each individual in each generation, enabling online adaptive optimization. - Differentiated Mutation: The population is classified by fitness, and different mutation strategies are applied to different groups.
- Evaluation: Compare RLDE against other heuristic algorithms (e.g., PSO, ABC, standard DE) on the test functions in 10, 30, and 50 dimensions. The results demonstrated enhanced global optimization performance [38].
Visualization of Algorithm Flows and Parameter Interactions
Genetic Algorithm Workflow
The following diagram illustrates the core workflow of a Genetic Algorithm, highlighting the stages where control parameters exert their influence.
Differential Evolution Workflow
This diagram outlines the specific steps of the Differential Evolution algorithm, emphasizing its unique mutation mechanism and parameter roles.
For researchers implementing and experimenting with GA and DE, the following "reagents" are essential.
Table 4: Essential Research Reagents for Evolutionary Computation
| Item / Concept | Function / Purpose | Example Use Case / Note |
|---|---|---|
| Benchmark Test Functions | To empirically evaluate and compare algorithm performance, strengths, and weaknesses. | DeJong function, Shekel's Foxholes [48], IEEE CEC benchmark suites [51]. |
| Fitness Function | Encodes the problem objective; evaluates the quality (fitness) of a candidate solution. | Must be carefully designed to accurately reflect the desired outcome. Highly problem-specific. |
| Encoding Scheme | Defines how a candidate solution is represented as a chromosome/vector. | Binary, Permutation, Value (Real-valued), Tree encoding [53] [48]. |
| Selection Mechanism | Determines which parents get to reproduce, based on fitness. | Tournament Selection, Roulette Wheel, Rank Selection [53]. |
| Termination Criterion | Defines when the algorithm stops. | Max generations, convergence threshold (e.g., 90% population homogeneity [52]), or target fitness. |
| External Archive | (Common in Multi-Objective EA/DE) Stores non-dominated solutions found during the search. | Used in algorithms like ε-MyDE and APMORD to maintain a diverse Pareto front [41]. |
| Policy Gradient Network | (For RL-enhanced EAs) The RL agent that learns to dynamically adjust parameters. | Core component of the RLDE algorithm for adapting F and CR [38]. |
The critical control parameters of population size, mutation/scale factor, and crossover rate are the linchpins of performance for both Genetic Algorithms and Differential Evolution. While GA, with its stronger biological metaphor, often relies on carefully tuned but often static probabilities, DE's unique differential mutation mechanism makes its parameters (F and CR) highly interactive and dynamically sensitive. The prevailing trend in modern research moves decisively away from static "one-size-fits-all" parameter settings toward adaptive and self-adaptive strategies. These range from simple linear changes to sophisticated Reinforcement Learning-based controllers that respond to the algorithm's state in real-time. For beginners, starting with established baseline settings is prudent, but progression to dynamic tuning methods is essential for achieving robust and state-of-the-art performance on complex, real-world optimization problems in drug development and scientific research.
Premature convergence represents one of the most significant challenges in evolutionary computation, occurring when a population loses its diversity too quickly and becomes trapped in local optima, thereby failing to locate the global optimum solution. This phenomenon plagues both Genetic Algorithms (GAs) and Differential Evolution (DE) algorithms, though through somewhat different mechanisms. For researchers, scientists, and drug development professionals utilizing these optimization techniques, understanding and mitigating premature convergence is crucial for obtaining meaningful results, particularly when dealing with complex, high-dimensional problems such as molecular optimization in drug discovery [28] or nuclear fuel management [27].
Within the broader context of comparing GAs and DE for beginner researchers, it is essential to recognize that both algorithms belong to the class of evolutionary algorithms but employ distinct approaches to population evolution. GAs, inspired by natural selection, typically utilize binary or floating-point representations with selection, crossover, and mutation operators [25] [10]. DE, on the other hand, operates primarily through differential mutation operations, creating new candidates by combining existing solutions according to specific strategy equations [10] [38]. The core distinction lies in their search behavior: DE's mutation operator leverages vector differences between population members, enabling a more directed exploration of the search space compared to the often more random exploration of traditional GA mutations [10] [27].
The risk of premature convergence manifests differently in each algorithm. In GAs, premature convergence often occurs when highly fit individuals quickly dominate the population through selection pressure, reducing genetic diversity before thorough exploration of the search space [25]. In DE, while the differential mutation mechanism provides inherent exploratory capabilities, inappropriate parameter settings (particularly the scaling factor F and crossover rate CR) can still lead to stagnation in local optima [38]. Research comparing these algorithms in practical applications like in-core fuel management has demonstrated that while DE generally exhibits stronger robustness in avoiding local optima, both algorithms can benefit significantly from diversity preservation strategies [27].
Fundamental Mechanisms: How GA and DE Maintain Diversity
The fundamental operators of Genetic Algorithms and Differential Evolution inherently influence population diversity through distinct mechanisms, each with characteristic strengths and vulnerabilities regarding premature convergence.
Genetic Algorithm Operators and Diversity
GA maintains diversity through three primary operations: selection, crossover, and mutation. Selection operators determine which individuals proceed to the next generation based on fitness, with common approaches including tournament selection and roulette wheel selection. Comparative studies have demonstrated that tournament selection often provides better performance by maintaining greater diversity, as it avoids the premature convergence associated with roulette wheel selection where superior individuals can quickly dominate the population [27]. The crossover operation facilitates the exchange of genetic material between parents, potentially creating novel combinations while preserving building blocks of promising solutions. GA implementations may utilize one-point, two-point, or uniform crossover, with research indicating that two-point crossover can enhance performance in complex optimization problems by providing more diverse offspring [27]. Finally, mutation operators introduce random perturbations to individuals, serving as a crucial diversity preservation mechanism by exploring new regions of the search space and preventing stagnation [25].
Differential Evolution Operators and Diversity
DE employs a different approach to population evolution, characterized by its unique differential mutation strategy. Unlike GA, where mutation typically applies small random changes, DE generates new candidates through vector operations, specifically by adding the weighted difference between two population vectors to a third vector [10]. This fundamental difference provides DE with a more directed exploration capability. The standard DE/rand/1 mutation strategy follows the equation:
$$v{i}(t+1) = x{r1}(t) + F \cdot (x{r2}(t) - x{r3}(t))$$
Where $v{i}(t+1)$ is the mutant vector, $x{r1}$, $x{r2}$, and $x{r3}$ are distinct population vectors, and $F$ is the scaling factor controlling the amplification of the differential variation [38]. This differential mutation enables self-tuning characteristics, as the magnitude of perturbations automatically decreases as the population converges, providing a natural balance between exploration and exploitation [10]. DE's crossover operation follows mutation, incorporating components from both the target vector and mutant vector based on the crossover rate (CR) parameter. This binomial crossover creates trial vectors that combine information from multiple parents, maintaining diversity while preserving successful genetic material [10] [38].
Table: Comparison of Fundamental Diversity Mechanisms in GA and DE
| Aspect | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Primary Exploration Mechanism | Crossover and random mutation | Differential mutation based on vector differences |
| Selection Pressure | Explicit selection operators (tournament, roulette wheel) | One-to-one selection between target and trial vectors |
| Parameter Sensitivity | Highly dependent on crossover and mutation rates | Sensitive to scaling factor (F) and crossover rate (CR) |
| Inherent Diversity | Tends to lose diversity quickly under high selection pressure | Maintains diversity through difference vectors |
| Typical Applications | Discrete and combinatorial optimization [25] | Continuous optimization problems [10] |
Critical Factors Influencing Population Diversity
Several algorithmic factors significantly impact population diversity in both GA and DE, with understanding these elements being crucial for effectively mitigating premature convergence.
Parameter Settings and Their Impact
Parameter configuration plays a pivotal role in balancing exploration and exploitation in evolutionary algorithms. For DE, the scaling factor (F) and crossover rate (CR) directly influence diversity maintenance. The scaling factor F, typically in the range [0, 2], controls the magnitude of differential variations, with larger values promoting exploration and smaller values favoring exploitation [38]. Research has shown that excessively small F values may lead to premature convergence as the algorithm fails to explore sufficiently, while overly large values can hinder convergence [38]. Similarly, CR determines the probability of incorporating components from the mutant vector versus the target vector, affecting population diversity. Studies recommend CR values in the range [0.7, 0.9] for many applications, though problem-specific tuning is often necessary [38].
In GA, key parameters include mutation probability, crossover type, and selection pressure. Comprehensive surveys have demonstrated that mutation probability significantly influences diversity, with optimal values typically falling between 0.1 and 0.2 for the scramble mutation operator in complex optimization problems [27]. The choice of crossover operator also affects diversity, with research indicating that two-point crossover generally outperforms one-point crossover in maintaining genetic diversity for challenging optimization tasks [27]. Additionally, selection mechanisms directly impact diversity loss, with tournament selection providing better control over selection pressure compared to roulette wheel selection, which tends to promote faster convergence and greater diversity loss [27].
Population Sizing and Initialization Methods
Population size represents another critical factor in diversity maintenance. While larger populations naturally preserve more diversity, they increase computational costs. Studies on nuclear fuel management optimization have utilized population sizes of 30-50 as a balance between diversity and efficiency for 100-dimensional problems [27]. The initialization method also significantly impacts early-stage diversity. Traditional random initialization may lead to clustering in specific regions, limiting initial exploration. Advanced approaches like Halton sequences and Latin Hypercube sampling generate more uniform initial distributions, improving coverage of the search space and enhancing diversity [54] [38]. Research on improved DE variants has demonstrated that Halton sequence initialization effectively improves the ergodicity of the initial solution set, establishing better foundation for maintaining diversity throughout the evolutionary process [38].
Table: Diversity-Related Parameters in GA and DE
| Parameter | Algorithm | Impact on Diversity | Recommended Range |
|---|---|---|---|
| Mutation Probability | GA | Higher values increase diversity but may disrupt convergence | 0.1-0.2 [27] |
| Scaling Factor (F) | DE | Larger values promote exploration, smaller values favor exploitation | [0.4-0.95] [38] |
| Crossover Rate (CR) | DE | Higher values increase component exchange between vectors | [0.7-0.9] [38] |
| Population Size | Both | Larger sizes preserve diversity but increase computation | 30-50+ (problem-dependent) [27] |
| Selection Mechanism | GA | Tournament selection generally preserves diversity better than roulette wheel [27] | N/A |
Advanced Strategies for Diversity Preservation
Beyond parameter tuning, researchers have developed sophisticated strategies specifically designed to mitigate premature convergence by actively maintaining population diversity.
Adaptive Parameter Control
Adaptive parameter control mechanisms dynamically adjust algorithm parameters during evolution based on search progress, providing a powerful approach to balance exploration and exploitation. Recent research has introduced reinforcement learning (RL) based parameter adaptation, where policy gradient networks continuously optimize the scaling factor F and crossover probability CR through interactions with the search environment [38]. This approach enables the algorithm to respond to its current state, increasing exploration when diversity drops and focusing on exploitation when nearing promising optima. Similarly, dithering techniques that randomly vary the mutation constant on a generation-by-generation basis have demonstrated significant convergence improvements by preventing stagnation [54]. These adaptive approaches overcome the limitations of static parameter settings, which often require extensive problem-specific tuning and may perform suboptimally throughout different evolutionary stages.
Hybrid and Multi-Method Approaches
Hybrid algorithms combining concepts from both GA and DE have shown promising results in diversity preservation. The RecRankDE method exemplifies this approach by integrating singular value decomposition (SVD) with DE for recommendation systems, maintaining diversity through matrix operations that preserve relational information between users and items [25]. Another innovative approach employs hierarchical mutation mechanisms that classify populations based on fitness values and implement differentiated mutation strategies [38]. After evolution, solutions are sorted by fitness, with different groups receiving specialized treatment—retaining better solutions while aggressively improving poorer ones. This targeted approach prevents the suppression of promising but not-yet-optimal solutions by currently fit individuals, a common cause of premature convergence. Furthermore, multi-population strategies partition the population into subgroups with different characteristics or tasks, enabling parallel exploration of different search space regions while mitigating overall diversity loss [38].
External Archive and Quality-Diversity Methods
The use of external archives to store promising solutions that would otherwise be lost during selection represents another effective diversity preservation strategy. The SLDE algorithm periodically reintroduces vectors from an external archive into the population, systematically increasing diversity and enhancing the algorithm's ability to escape local optima [38]. Quality-diversity approaches like MAP-Elites (Multi-dimensional Archive of Phenotypic Elites) maintain collections of high-performing solutions with diverse characteristics, explicitly preserving behavioral diversity rather than just genetic diversity [55]. This technique has been successfully applied in benchmark function generation using genetic programming, creating varied functions with different performance characteristics that help compare and analyze algorithmic behaviors [55]. Similarly, in molecular generation, latent space evolutionary optimization maintains diverse candidate molecules while optimizing for specific properties, crucial for drug discovery applications where structural diversity is as important as property optimization [28].
Experimental Protocols and Evaluation Metrics
Rigorous experimental methodology is essential for evaluating diversity preservation strategies and comparing algorithm performance regarding premature convergence.
Standardized Testing Protocols
Comprehensive algorithm evaluation requires standardized testing protocols with multiple independent runs and appropriate statistical analysis. For comparing GA and DE performance in complex optimization problems like in-core fuel management, researchers have conducted 50 independent runs of each algorithm with identical population sizes, fitness functions, and convergence criteria [27]. This approach accounts for the stochastic nature of evolutionary algorithms and provides statistically significant results. The best fitness values from each run are collected for statistical analysis using non-parametric tests like Kruskal-Wallis and Mann-Whitney tests, which compare performance distributions without assuming normality [27]. Such rigorous methodology enables meaningful conclusions about algorithm robustness and consistency in maintaining diversity.
Performance evaluation should also include analysis of trapping rates in local optima, which directly indicates premature convergence susceptibility. Research has shown that while basic GA variants may experience local optima trapping rates of 26-38%, well-designed DE algorithms can significantly reduce this percentage, demonstrating stronger diversity preservation capabilities [27]. Additionally, fitness landscape analysis provides insights into problem characteristics that influence diversity loss. Metrics like Fitness Distance Correlation (FDC) characterize landscape deception, with values near zero indicating highly deceptive landscapes where diversity preservation is particularly crucial [55]. Neutrality measurements quantify regions where fitness remains constant despite genotype changes, requiring specialized diversity maintenance strategies to traverse effectively [55].
Diversity Measurement Techniques
Quantifying population diversity enables direct monitoring and comparison of diversity preservation strategies. Genotypic diversity metrics calculate distance between population members in the solution space, with the Wasserstein distance providing a multidimensional measure of distribution differences between solution sets found by different optimizers [55]. This approach has been used effectively in genetic programming to evolve benchmark functions that maximize performance differences between algorithms, indirectly measuring their diversity preservation characteristics. Phenotypic diversity metrics focus on behavioral differences rather than structural differences, particularly valuable in applications like molecular generation where different structures may exhibit similar properties or behaviors [28]. Maintaining archives of elite solutions with diverse phenotypic characteristics, as in MAP-Elites, ensures comprehensive exploration of possible solution behaviors rather than converging to minor variations of the same basic approach [55].
Table: Experimental Evaluation Metrics for Diversity Preservation
| Metric Category | Specific Metrics | Interpretation | Application Context |
|---|---|---|---|
| Performance Metrics | Success rate, Convergence generations | Lower success rates indicate premature convergence | General optimization [27] |
| Statistical Tests | Kruskal-Wallis, Mann-Whitney | Compare algorithm performance distributions | Algorithm comparison [27] |
| Diversity Metrics | Wasserstein distance, Phenotypic diversity | Higher values indicate better diversity maintenance | Benchmark evaluation [55] |
| Landscape Analysis | Fitness Distance Correlation (FDC), Neutrality | Quantifies problem difficulty and deception | Problem characterization [55] |
| Local Opta Analysis | Trapping rate | Percentage of runs stuck in local optima | Algorithm robustness [27] |
Application Case Study: Drug Discovery and Molecular Optimization
The challenge of premature convergence is particularly relevant in drug discovery, where evolutionary algorithms increasingly optimize molecular structures for desired properties while maintaining chemical diversity.
Latent Space Evolutionary Optimization
The LEOMol (Latent Evolutionary Optimization for Molecule Generation) framework demonstrates effective diversity preservation in constrained molecular generation by combining Variational AutoEncoders (VAE) with evolutionary algorithms [28]. This approach encodes molecules into a continuous latent space using SELFIES representations, which guarantee molecular validity throughout evolution, then applies either GA or DE to search this latent space for molecules optimizing target properties while maintaining structural diversity [28]. The integration of evolutionary algorithms with deep generative models enables exploration beyond the training data distribution, crucial for discovering novel molecular scaffolds rather than converging to minor variations of known compounds. This methodology directly addresses the diversity preservation challenge in lead optimization, where maintaining structural novelty while improving specific properties is essential for successful drug development.
Multi-objective Optimization and Diversity
Drug discovery inherently involves multiple, often competing objectives—including binding affinity, solubility, synthetic accessibility, and toxicity—making multi-objective optimization with diversity preservation particularly important. Evolutionary algorithms naturally accommodate multi-objective optimization through techniques like Pareto-front maintenance, which preserves diverse solutions representing different trade-offs between objectives [28]. Research has demonstrated that DE-based approaches consistently outperform previous state-of-the-art models across constrained molecule generation tasks, particularly in generating molecules with desired properties while preserving similarity to input molecules during lead optimization [28]. The capability to incorporate non-differentiable oracles such as RDKit property calculations further enhances practical utility, as many crucial molecular properties cannot be optimized through gradient-based methods alone [28].
Diagram: Molecular Optimization Workflow with Diversity Preservation. This workflow integrates evolutionary algorithms with deep generative models for drug discovery, emphasizing diversity preservation through multiple mechanisms.
Implementing effective diversity preservation strategies requires specific tools and methodologies tailored to evolutionary computation research and applications.
Algorithm Implementation Frameworks
SciPy Differential Evolution: Provides a comprehensive implementation of DE with multiple strategy options ('best1bin', 'rand1bin', etc.), Latin Hypercube initialization, and parallelization support through the workers parameter [54].
RDKit Cheminformatics Toolkit: An open-source toolkit for cheminformatics used for evaluating molecular properties in drug discovery applications, particularly valuable for providing non-differentiable oracles in evolutionary optimization [28].
MAP-Elites Framework: A quality-diversity algorithm implementation that maintains an archive of elite solutions with diverse phenotypic characteristics, enabling explicit diversity preservation in complex optimization landscapes [55].
Analysis and Visualization Tools
Fitness Landscape Analysis (FLA) Tools: Computational methods for quantifying problem characteristics like Fitness Distance Correlation (FDC) and neutrality, which help predict algorithm performance and diversity requirements [55].
Statistical Testing Libraries: Implementations of Kruskal-Wallis and Mann-Whitney tests for rigorous comparison of algorithm performance across multiple independent runs, essential for validating diversity preservation effectiveness [27].
Wasserstein Distance Metrics: Multidimensional distribution distance measures for quantifying differences between solution sets found by different optimizers, providing direct measurement of diversity maintenance [55].
The peril of premature convergence remains a significant challenge in evolutionary computation, but numerous effective strategies exist for maintaining population diversity in both Genetic Algorithms and Differential Evolution. For researchers and practitioners, the selection of appropriate diversity preservation techniques depends on problem characteristics, computational constraints, and application requirements. DE generally exhibits stronger inherent diversity preservation through its differential mutation mechanism, making it particularly suitable for continuous optimization problems where parameter tuning is feasible [10] [27]. GA offers greater flexibility for discrete and combinatorial problems, with careful selection of operators and parameters required to mitigate diversity loss [25] [27].
For drug development professionals and scientific researchers, emerging approaches like latent space evolutionary optimization [28] and reinforcement learning-guided parameter adaptation [38] represent promising directions that combine the strengths of multiple paradigms. These advanced techniques explicitly address the diversity-optimization tradeoff, enabling more effective exploration of complex search spaces like chemical compound spaces in drug discovery. Regardless of the specific algorithm chosen, rigorous experimental methodology with multiple independent runs and appropriate statistical analysis remains essential for meaningful evaluation and comparison of diversity preservation strategies [27]. By understanding and implementing these diversity maintenance approaches, researchers can significantly reduce the risk of premature convergence and enhance the effectiveness of evolutionary computation in scientific and engineering applications.
For researchers, scientists, and drug development professionals working with optimization algorithms, the problem of premature convergence to local optima remains a significant challenge in solving complex, high-dimensional problems. Within the broader thesis comparing genetic algorithms (GAs) and differential evolution (DE), this whitepaper examines the core differential mechanism that provides DE with a distinctive advantage in maintaining population diversity and escaping local optima. Traditional genetic algorithms, while powerful, often struggle with population diversity maintenance, particularly when solving multimodal optimization problems with numerous local optima [17]. The differential evolution algorithm, introduced by Storn and Price in 1995, employs a unique mutation strategy that leverages vector differences to navigate complex search spaces more effectively than traditional evolutionary approaches [13] [56]. This technical guide explores the mechanistic foundations of DE's mutation operator, provides comparative analysis with GA approaches, and presents experimental protocols for benchmarking performance in drug discovery applications where escaping local optima is critical for identifying optimal solutions.
Fundamental Mechanisms: DE's Difference-Vector Based Mutation
The differential evolution algorithm belongs to the class of evolutionary algorithms but distinguishes itself through its specialized approach to generating new candidate solutions. Unlike genetic algorithms that typically rely on binary representation and bit-flip mutations, DE uses real-valued vectors throughout its optimization process [6]. The algorithm begins by initializing a population of candidate solutions randomly distributed throughout the search space. For each iteration, DE creates new candidate solutions through a process of mutation and crossover, then selects the fittest individuals for the next generation [13] [2].
The most critical distinction lies in DE's mutation phase, which employs a difference-based operator. For each target vector in the population, DE generates a mutant vector (donor vector) by combining the differences between randomly selected population members. The fundamental mutation strategy, known as DE/rand/1, follows this mathematical formulation:
[ V{i,G+1} = X{r1,G} + F \cdot (X{r2,G} - X{r3,G}) ]
Where:
- (V_{i,G+1}) is the mutant/donor vector
- (X{r1,G}), (X{r2,G}), (X_{r3,G}) are three distinct randomly selected population vectors
- (F) is the scaling factor controlling amplification of the differential variation [13] [56]
This difference-vector approach enables DE to automatically adapt step sizes based on the distribution of the current population. When the population is widely dispersed, step sizes are naturally larger, facilitating exploration. As the population converges, step sizes automatically decrease, enabling finer exploitation of promising regions [13] [3]. This self-adaptive characteristic reduces the need for parameter tuning and provides a natural mechanism for transitioning between exploration and exploitation phases.
Table 1: Common DE Mutation Strategies and Their Characteristics
| Strategy | Mathematical Formulation | Exploration/Exploitation Balance | Convergence Speed |
|---|---|---|---|
| DE/rand/1 | (Vi = X{r1} + F \cdot (X{r2} - X{r3})) | High exploration | Moderate |
| DE/best/1 | (Vi = X{best} + F \cdot (X{r1} - X{r2})) | High exploitation | Fast |
| DE/current-to-best/1 | (Vi = Xi + F \cdot (X{best} - Xi) + F \cdot (X{r1} - X{r2})) | Balanced | Fast |
| DE/rand/2 | (Vi = X{r1} + F \cdot (X{r2} - X{r3}) + F \cdot (X{r4} - X{r5})) | Very high exploration | Slow |
| DE/current/1 | (Vi = Xi + F \cdot (X{r1} - X{r2})) | High exploration | Slow [57] |
After mutation, DE employs a crossover operation where parameters from the mutant vector are combined with the target vector to create a trial vector. This typically follows a binomial crossover scheme:
[ U{j,i,G+1} = \begin{cases} V{j,i,G+1} & \text{if } rand(0,1) \leq CR \text{ or } j = j{rand} \ X{j,i,G} & \text{otherwise} \end{cases} ]
Where (CR) is the crossover probability and (j_{rand}) is a randomly chosen index ensuring at least one parameter comes from the mutant vector [13]. The final selection step employs a greedy selection mechanism where the trial vector replaces the target vector only if it has better or equal fitness, ensuring the population either improves or remains the same each generation [2].
Figure 1: Differential Evolution Mutation and Selection Workflow
Comparative Analysis: DE vs. Genetic Algorithm Mutation Strategies
Understanding the fundamental differences between how differential evolution and genetic algorithms approach mutation reveals why DE generally demonstrates superior performance in escaping local optima, particularly for continuous optimization problems common in drug development.
Representation and Mutation Operations
Genetic algorithms traditionally operate on binary representations of solutions, though real-valued representations are also used. In either case, GA mutation typically occurs through random perturbations to individual elements of a solution. For real-valued representations, this often involves adding Gaussian or uniform random noise to gene values [6]. This approach creates undirected, random exploration of the search space without leveraging information about the population distribution.
In contrast, differential evolution uses vector differences between population members to guide its mutation process. This approach creates a form of directed mutation where the evolutionary step size and direction are informed by the natural clustering of the population [3]. The differential vectors provide information about the landscape topology, allowing DE to take larger steps when the population is diverse and smaller, more refined steps as convergence occurs.
Adaptation to Search Landscape
The GA mutation process typically relies on fixed or scheduled parameters that determine the magnitude of perturbations. While adaptive parameter control methods exist, they generally require explicit implementation and can be problem-dependent [58]. DE's difference-vector approach provides implicit adaptation to the search landscape. When the population is widely dispersed, difference vectors tend to be larger, promoting exploration. As the population converges around optima, difference vectors naturally become smaller, enabling finer exploitation [13] [3].
Information Utilization
Genetic algorithms typically use selection and recombination as the primary drivers of evolution, with mutation serving as a background operator to maintain diversity. In DE, the mutation operator plays a central role in the evolutionary process, actively leveraging information about the population distribution to guide the search [56]. This allows DE to more effectively utilize information gained about the search landscape throughout the optimization process.
Table 2: Mutation Strategy Comparison Between GA and DE
| Characteristic | Genetic Algorithm | Differential Evolution |
|---|---|---|
| Representation | Binary or real-valued | Real-valued vectors |
| Mutation Operator | Random perturbations (bit-flips or noise addition) | Difference vector-based |
| Step Size Control | Typically fixed or scheduled parameters | Self-adaptive based on population distribution |
| Information Utilization | Limited use of population distribution information | Active use of vector differences to guide search |
| Parameter Sensitivity | High sensitivity to mutation rate parameters | Lower sensitivity due to self-adaptation |
| Local Optima Escape | Limited without explicit diversity mechanisms | Strong through directional difference vectors |
| Implementation Complexity | Moderate | Low (requires few control parameters) [6] [3] |
Enhanced DE Mutation Strategies for Improved Performance
While the classic DE mutation strategies perform well, recent research has developed enhanced approaches that further improve the algorithm's ability to escape local optima and navigate complex search spaces. These advancements are particularly relevant for drug discovery applications where optimization landscapes often contain numerous local optima.
DE/Neighbor-Based Strategies
Traditional DE variants like DE/rand/1 and DE/best/1 face challenges in maintaining the balance between exploration and exploitation. To address this, neighbor-based mutation strategies have been developed. The DE/Neighbor/1 strategy selects parents from a defined neighborhood rather than the entire population, promoting better local exploration [56]. The enhanced DE/Neighbor/2 strategy further improves upon this by incorporating multiple difference vectors:
[ Vi = X{nbest} + F \cdot (X{r1} - X{r2}) + F \cdot (X{r3} - X{r4}) ]
This approach increases population diversity while maintaining selection pressure toward better solutions, resulting in improved convergence characteristics compared to basic DE variants [56].
Two-Stage and Adaptive Approaches
The Two-Stage Mutation Strategy Combination (TS-MSCDE) algorithm addresses premature convergence by dynamically adjusting mutation strategies based on optimization progress [57]. This approach divides the optimization process into exploration-focused and exploitation-focused stages, with distinct mutation strategies assigned to each stage. In the exploration phase, strategies like DE/current/1 are employed to maintain population diversity, while the exploitation phase utilizes strategies like DE/best/1 for refined local search [57].
Adaptive parameter control represents another significant advancement. Instead of fixed parameters, these approaches dynamically adjust the scale factor (F) and crossover rate (CR) based on algorithm performance. Reinforcement learning-based DE (RLDE) uses a policy gradient network to adaptively optimize these parameters in real-time, significantly enhancing optimization performance on complex problems [58].
Multi-Modal and Niching Extensions
For drug discovery applications where identifying multiple promising candidate compounds is valuable, multi-modal DE variants have been developed. These approaches incorporate niching techniques that promote the formation and maintenance of multiple subpopulations converging to different optima [17]. Methods such as crowding, fitness sharing, and speciation allow DE to simultaneously explore multiple promising regions of the search space, making it particularly valuable for identifying diverse candidate solutions in molecular design and binding affinity optimization [17].
Experimental Protocols and Implementation Guidelines
Implementing and benchmarking differential evolution requires careful experimental design, particularly when comparing performance against genetic algorithms and other optimization approaches for drug development applications.
Standard Experimental Protocol for DE Performance Evaluation
Benchmark Functions and Evaluation Metrics:
- Select standardized test suites (CEC2017, CEC2020) with diverse function characteristics [57]
- Include unimodal, multimodal, hybrid, and composition functions
- Measure mean error (best fitness - optimal fitness), success rate, and computational cost
- Perform multiple independent runs (typically 30-51) to ensure statistical significance
Parameter Configuration:
- Population size (NP): Typically 5-10 times the problem dimension [13]
- Scale factor (F): Start with 0.5-0.9 depending on mutation strategy [2]
- Crossover rate (CR): Begin with 0.9 for separable problems, 0.5-0.7 for non-separable [3]
- Termination criteria: Maximum function evaluations (e.g., 10,000 × D) or fitness threshold [56]
Implementation Details:
Drug-Target Binding Affinity Prediction Case Study
A practical application demonstrating DE's superiority in drug development involves optimizing hyperparameters for deep learning models predicting drug-target binding affinity. In recent research, a Convolution Self-Attention Network with Attention-based Bidirectional LSTM (CSAN-BiLSTM-Att) was optimized using differential evolution [16].
Experimental Setup:
- Dataset: DAVIS and KIBA drug-target interaction datasets
- Objective: Minimize mean square error of binding affinity prediction
- DE Configuration: Population size=50, F=0.8, CR=0.9, max iterations=500
- Comparison: Grid search, random search, genetic algorithm, Bayesian optimization
Results:
- DE-optimized model achieved concordance index of 0.898 (DAVIS) and 0.971 (KIBA)
- Superior performance compared to GA-optimized models (5-7% improvement)
- Effective navigation of high-dimensional hyperparameter space (24+ parameters) [16]
Table 3: Research Reagent Solutions for DE Optimization in Drug Discovery
| Reagent/Resource | Function in DE Research | Application Context |
|---|---|---|
| CEC2017/CEC2020 Benchmark Suite | Standardized performance evaluation | Algorithm validation and comparison |
| DAVIS/KIBA Dataset | Real-world drug-target interaction data | Binding affinity prediction optimization |
| CSAN-BiLSTM-Att Architecture | Deep learning model for DTI prediction | Hyperparameter optimization case study |
| Halton Sequence Generator | Quasi-random population initialization | Improving initial population diversity [58] |
| Policy Gradient Network (RLDE) | Adaptive parameter control | Reinforcement learning-enhanced DE [58] |
| Niching/Crowding Mechanisms | Multi-modal optimization support | Identifying multiple candidate drug compounds [17] |
Differential evolution's mutation strategy provides a fundamental advantage over genetic algorithms in escaping local optima, particularly for the continuous, high-dimensional optimization problems prevalent in drug discovery and development. The difference-vector based approach enables self-adaptive step sizing, automatic balancing of exploration and exploitation, and directed search through the optimization landscape. For drug development professionals, DE offers practical advantages in optimizing complex models, predicting drug-target interactions, and navigating the rugged search spaces characteristic of molecular design problems. While both genetic algorithms and differential evolution have roles in computational optimization, DE's mechanistic approach to mutation makes it particularly valuable for overcoming the local optima problem that frequently impedes progress in drug discovery pipelines. Future research directions include further integration with reinforcement learning for parameter adaptation, enhanced multi-modal capabilities for identifying diverse candidate solutions, and specialized mutation strategies for domain-specific challenges in pharmaceutical research.
Balancing Exploration and Exploitation in Complex Chemical Search Spaces
The process of drug discovery inherently involves navigating vast, complex chemical spaces in search of molecules with desired therapeutic properties. With an estimated 10^60 drug-like compounds in chemical space, the challenge lies not only in identifying promising candidates but also in balancing the search between thoroughly investigating known promising regions (exploitation) and venturing into novel, unexplored territories (exploitation) [60]. This fundamental trade-off between exploration and exploitation represents a core optimization problem that computational approaches must address to accelerate therapeutic development.
Within this context, evolutionary algorithms (EAs) have emerged as powerful optimization techniques for chemical space navigation. Two prominent branches—Genetic Algorithms (GA) and Differential Evolution (DE)—offer distinct approaches to managing the exploration-exploitation balance. While both belong to the broader class of evolutionary computation, their mechanisms for generating new solutions differ significantly, leading to characteristic strengths in different aspects of chemical space exploration [6]. For researchers and drug development professionals, understanding these distinctions is crucial for selecting appropriate algorithms for specific discovery challenges, particularly when dealing with highly competitive target classes where novelty is paramount [61] [60].
Fundamental Concepts: Exploration vs. Exploitation
In optimization algorithms, exploration refers to the process of investigating new regions of the search space to identify potentially promising areas that may contain superior solutions. In chemical terms, this equates to generating structurally diverse compounds with novel scaffolds or functional groups. Conversely, exploitation involves intensively searching the vicinity of known good solutions to refine and improve them, analogous to creating analogues of a lead compound to enhance potency or optimize properties [62].
The balance between these competing objectives is critical throughout the drug discovery pipeline. During virtual screening, this may manifest as the choice between selecting compounds similar to known binders (exploitation) versus choosing chemically diverse representatives from clustering results (exploration) [63]. In de novo molecular design, the tension emerges between refining known chemical series and generating entirely novel chemotypes [61]. Effective navigation of chemical space requires adaptive strategies that dynamically adjust this balance based on project stage, target biology, and intellectual property considerations.
Algorithmic Foundations: Genetic Algorithms vs. Differential Evolution
Genetic Algorithms (GA)
Genetic Algorithms operate on a population of candidate solutions, typically represented as fixed-length encodings (chromosomes). Inspired by biological evolution, GAs employ three primary operators: selection, crossover, and mutation. Selection identifies promising solutions based on fitness, favoring exploitation of known good regions. Crossover combines elements of parent solutions to create offspring, enabling both exploration and exploitation depending on implementation. Mutation introduces random changes, primarily serving exploration by generating novel variations [25].
In chemical optimization, GA representations may include binary fingerprints, integer-encoded features, or real-valued molecular descriptors. For example, in agricultural nutrition recommendation systems, researchers have encoded nutrient chemicals as integer values within chromosomes, using Euclidean distance to measure similarity between solutions [25]. Similarly, in movie recommendation systems, GA has been applied to optimize floating-point vectors representing user-item relationships, using Mean Absolute Error between predicted and actual ratings as the fitness function [25].
Differential Evolution (DE)
Differential Evolution is a specialized evolutionary algorithm that emphasizes vector differences between population members to drive the search process. Unlike the discrete representations common in GAs, DE typically uses real-valued vectors directly, making it particularly suitable for continuous optimization problems in chemical descriptor space [6]. DE's distinctive mutation operator generates new candidate solutions by adding scaled differences between population vectors to a base vector, creating an inherently self-scaling exploration mechanism [64].
The core DE mutation strategy ("rand/1") can be expressed as:
[ \vec{v}{i,g+1} = \vec{x}{r1,g} + F \cdot (\vec{x}{r2,g} - \vec{x}{r3,g}) ]
Where (\vec{v}{i,g+1}) is the mutant vector, (\vec{x}{r1,g}), (\vec{x}{r2,g}), and (\vec{x}{r3,g}) are randomly selected population vectors from generation (g), and (F) is a scaling factor controlling the magnitude of the differential variation [64]. This difference vector approach allows DE to automatically adapt its step size based on the distribution of solutions in the population—larger differences promote exploration when the population is diverse, while smaller differences facilitate exploitation as the population converges [65].
Table 1: Core Algorithmic Differences Between GA and DE
| Feature | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Representation | Binary, integer, or real-valued | Primarily real-valued vectors |
| Mutation Operator | Typically random perturbations | Based on vector differences between population members |
| Crossover | Multi-point, uniform, or simulated binary | Binary or exponential with greedy selection |
| Parameter Control | Often static | Frequently adaptive/self-adaptive |
| Exploration Mechanism | Mutation rate and selection pressure | Difference vector scaling and population diversity |
| Exploitation Mechanism | Elitism and fitness-proportional selection | Greedy selection and local refinement |
Algorithmic Mechanisms for Balancing Exploration and Exploitation
Hybrid DE Algorithms and Memetic Approaches
Modern DE variants often incorporate hybrid strategies to enhance the exploration-exploitation balance. Memetic Algorithms combine DE with local search techniques, using DE for global exploration while employing local search methods for intensive exploitation around promising regions [65]. For multimodal problems, niching competition strategies maintain population diversity by preserving solutions from different regions of chemical space, while supporting archive mechanisms retain high-quality solutions for subsequent exploitation phases [65].
Adaptive Parameter Control
Parameter adaptation represents a powerful approach for dynamically balancing exploration and exploitation throughout the optimization process. DE parameters—particularly the scale factor (F) and crossover rate (Cr)—significantly influence search behavior. Adaptive parameter control mechanisms adjust these parameters based on algorithm performance, typically increasing exploration (via larger (F) and lower (Cr)) during early stages while shifting toward exploitation (smaller (F) and higher (Cr)) as convergence is detected [65]. For population size (NP), reduction strategies gradually decrease population diversity to transition from exploration to exploitation [65].
Ensemble and Multi-Population Methods
Ensemble strategies employ multiple search operators or parameter settings concurrently, allowing the algorithm to automatically select appropriate configurations for different optimization stages or problem regions [65]. Multi-population techniques divide the population into subpopulations with specialized roles—some focused on exploration of unpromising regions, others on exploiting known good areas [65]. This approach is particularly valuable for complex chemical spaces containing multiple promising scaffolds or chemotypes.
Practical Implementation in Drug Discovery
Molecular Generation and Optimization
In de novo molecular design, recurrent neural networks (RNNs) combined with evolutionary algorithms have demonstrated significant potential for exploring chemical space. Using Simplified Molecular Input Line Entry Specification (SMILES) representations, these models can generate novel molecular structures with optimized properties [60]. The exploration-exploitation balance is managed through transfer learning approaches, where models are first pre-trained on large molecular databases (exploration) then fine-tuned on target-specific compounds (exploitation) [60]. This approach has successfully identified novel kinase inhibitors, including potent Pim1 inhibitors and CDK4 lead compounds [60].
Diversity-Driven Frameworks for Goal-Directed Generation
A critical challenge in goal-directed molecular optimization is the inherent conflict between maximizing a scoring function and maintaining structural diversity. A probabilistic framework has been proposed to reconcile these objectives by modeling the imperfect correlation between predicted scores and actual success probabilities [61]. This approach recognizes that scoring functions are imperfect predictors of real-world performance, making diverse solution batches more robust to model errors and unanticipated failures [61].
Quality-diversity algorithms such as MAP-Elites explicitly maintain diverse solutions across predefined feature dimensions, ensuring coverage of chemical space while optimizing properties [61]. Similarly, the Memory-RL framework prevents over-convergence by organizing molecules into similarity-based memory units and penalizing over-represented regions, effectively balancing exploration of novel regions with exploitation of known promising chemotypes [61].
Diagram 1: Adaptive Exploration-Exploitation Workflow. This flowchart illustrates how modern DE algorithms dynamically switch between exploration and exploitation phases based on population diversity metrics.
Experimental Protocols and Evaluation Metrics
Benchmarking Algorithm Performance
Comprehensive evaluation of exploration-exploitation balance requires rigorous experimental design. The Congress on Evolutionary Computation (CEC) competition frameworks provide standardized benchmark suites encompassing unimodal, multimodal, hybrid, and composition functions that test different algorithm capabilities [64]. For chemical applications, these are complemented by domain-specific benchmarks using public datasets like ChEMBL and DrugBank [60].
Statistical comparison methods are essential for robust algorithm assessment. The Wilcoxon signed-rank test enables pairwise comparison of algorithm performance across multiple benchmark problems, while the Friedman test with post-hoc Nemenyi analysis supports multiple algorithm comparisons [64]. The Mann-Whitney U-score test provides additional statistical validation, particularly for high-dimensional optimization problems relevant to chemical descriptor spaces [64].
Exploration-Exploitation Metrics
Quantifying exploration and exploitation during optimization requires specialized metrics. Diversity measures track population dispersion throughout the search process, typically using distance-based metrics in chemical descriptor space. Adaptation metrics monitor parameter changes and operator selection frequencies, providing insights into how algorithms dynamically balance search strategies [65]. For molecular optimization, chemical space coverage can be visualized using dimensionality reduction techniques, while scaffold diversity metrics assess structural novelty relative to known chemical databases.
Table 2: Key Reagents and Computational Tools for Chemical Space Exploration
| Tool/Reagent | Type | Function in Experimentation |
|---|---|---|
| ChEMBL Database | Chemical Database | Provides curated bioactivity data for training and benchmarking [60] |
| RDKit | Cheminformatics Library | Handles molecular representation, descriptor calculation, and similarity metrics [60] |
| TensorFlow | Deep Learning Framework | Implements neural network-based generative models and reinforcement learning [60] |
| SMILES Representation | Molecular Notation | Enables string-based molecular generation and manipulation [60] |
| Tanimoto Similarity | Similarity Metric | Quantifies molecular similarity for diversity assessment and clustering [61] |
| DB-Index | Cluster Quality Metric | Evaluates clustering purity in chemical space partitioning [25] |
Comparative Performance Analysis
Algorithm Selection Guidelines
Empirical studies across optimization domains reveal characteristic performance patterns for GA and DE approaches. DE generally exhibits stronger exploration capabilities in continuous spaces, with its difference-based mutation enabling effective navigation of high-dimensional chemical descriptor spaces [65] [6]. However, DE's exploitation ability may be relatively insufficient during later evolutionary stages as population diversity decreases [65]. This makes DE particularly suitable for initial stages of chemical space investigation where broad exploration is prioritized.
GA approaches offer greater representational flexibility, accommodating discrete molecular features and complex constraint handling. The explicit separation of selection, crossover, and mutation operators provides transparent control over exploration-exploitation balance, though this often requires careful parameter tuning [25]. GA implementations with elitism strategies and adaptive mutation rates have demonstrated effective performance on mixed discrete-continuous optimization problems common in molecular design [25].
Recent Advances and Hybrid Approaches
Modern DE variants have addressed original limitations through sophisticated mechanisms for maintaining population diversity and enhancing local refinement. Multi-population DE with specialized subpopulations for exploration and exploitation has shown improved performance on complex, multi-modal fitness landscapes [65]. Ensemble-based parameter adaptation automatically selects appropriate strategies for different optimization phases, reducing the parameter tuning burden while maintaining robust performance across diverse problem types [65].
In direct applications to chemical space exploration, hybrid models combining RNN-based molecular generation with evolutionary optimization have demonstrated practical success. For competitive target classes like kinase inhibitors, these approaches have identified novel chemotypes while maintaining desired activity profiles, successfully balancing exploration of new chemical space with exploitation of known structure-activity relationships [60].
Diagram 2: Algorithmic Approaches to Chemical Space Navigation. This diagram contrasts how GA and DE employ different operators to balance exploration and exploitation in chemical space.
The effective balance of exploration and exploitation in chemical search spaces remains a fundamental challenge in computational drug discovery. Both Genetic Algorithms and Differential Evolution offer distinct advantages for different aspects of this problem. DE's difference-vector-based approach provides powerful exploration capabilities in continuous descriptor spaces, while GA's flexible representation suits problems with mixed variable types and complex constraints.
Future research directions include developing more sophisticated theoretical frameworks for quantifying exploration-exploitation balance specifically in chemical spaces, integrating multi-fidelity evaluation methods that combine computational predictions with experimental data, and creating automated algorithm selection systems that recommend appropriate optimization strategies based on chemical problem characteristics [65] [61]. As artificial intelligence continues transforming drug discovery, evolutionary algorithms incorporating adaptive exploration-exploitation balance will play increasingly important roles in navigating the vast complexity of chemical space to accelerate therapeutic development.
For drug development professionals, the key practical consideration is matching algorithm selection to specific project needs—prioritizing exploration when seeking novel chemotypes for unprecedented targets or overcoming intellectual property barriers, while emphasizing exploitation when optimizing well-established chemical series during lead optimization phases. The most successful molecular design campaigns will likely continue employing hybrid strategies that dynamically adapt this balance throughout the discovery pipeline.
In the realm of evolutionary computation, Genetic Algorithms (GA) and Differential Evolution (DE) stand as two prominent metaheuristics inspired by biological principles. While both operate on population-based, survival-of-the-fittest paradigms, their underlying mechanisms and operational strengths differ significantly [10]. Selecting the appropriate algorithm is crucial for solving complex optimization problems efficiently, particularly in fields like drug development where outcomes impact research timelines and resource allocation. This guide provides an in-depth comparison of GA and DE, detailing their methodologies, performance characteristics, and ideal application domains to empower researchers in making informed algorithm selections.
Core Methodologies and Fundamental Differences
Genetic Algorithm (GA) Framework
Genetic Algorithms, introduced by John Holland, simulate natural evolution processes including selection, crossover, and mutation [66]. A typical GA workflow involves the following stages:
- Initialization: A population of candidate solutions (chromosomes) is generated, often randomly. Chromosomes are traditionally represented as binary strings, though other encodings like permutation or value-based schemes are also used [66].
- Selection: Individuals are selected for breeding based on their fitness, typically using methods like roulette wheel selection, tournament selection, or rank selection [67]. This applies Darwinian pressure, favoring fitter solutions.
- Crossover: Selected parent chromosomes recombine to produce offspring. This operator exploits existing genetic material by swapping subsequences between parents, promoting the propagation of beneficial building blocks (schemata) [26] [66].
- Mutation: Introduces random changes to individual genes with a low probability. This operator explores new regions of the search space, helping to maintain population diversity and prevent premature convergence [26] [66].
The GA process is iterative, repeating these steps across generations until a termination condition is met [26]. Its dynamic adjustment of exploration and exploitation is partially governed by the crossover rate, which can be adapted based on generation number [66].
Differential Evolution (DE) Framework
Differential Evolution, developed by Storn and Price, is specifically designed for optimization over continuous spaces [10] [38]. Its streamlined procedure emphasizes differential mutation:
- Initialization: A population of real-valued vectors is generated within the feasible solution space [38].
- Mutation: For each target vector in the population, a donor vector is created using a weighted difference of other randomly selected population vectors. A common strategy, DE/rand/1, is formulated as: ( \vec{v}i(g+1) = \vec{x}{r1}(g) + F \cdot (\vec{x}{r2}(g) - \vec{x}{r3}(g)) ) where ( F ) is the scaling factor controlling amplification of the differential variation [10] [38] [68].
- Crossover: The donor vector mixes with the target vector to form a trial vector. This is typically done through binomial crossover, where each component of the trial vector is inherited either from the donor or the target based on a crossover probability (( CR )) [10] [38].
- Selection: The trial vector competes directly against the target vector. The fitter of the two survives to the next generation, ensuring the population's average fitness monotonically improves [10] [38].
Key Mechanistic Differences
The fundamental differences between GA and DE lie in their representation and operator design, which directly influence their search capabilities.
- Representation and Search Space: GA traditionally uses binary representations, making it seemingly suited for discrete problems, though real-valued encodings are also employed. DE uses native real-valued vectors, making it inherently strong for continuous optimization [10] [68].
- Crossover vs. Mutation Primacy: In GA, crossover is the primary operator for creating new solutions, with mutation serving a background role. In DE, the differential mutation operator drives the search, with crossover playing a supporting role in mixing genetic material [10].
- Selection Strategy: GA often uses fitness-proportionate or rank-based selection to choose parents for the next generation. DE employs a one-to-one selection scheme where each target vector is immediately replaced if a better trial vector is found, leading to a more greedy and faster convergence in many cases [10] [68].
Diagram 1: Genetic Algorithm (GA) Workflow. Crossover is the primary operator, with mutation playing a secondary role.
Diagram 2: Differential Evolution (DE) Workflow. Differential mutation drives the search, with greedy one-to-one selection.
Comparative Performance Analysis
Algorithm Characteristics and Application Fit
Table 1: Algorithm Characteristics and Problem-Specific Recommendations
| Feature | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Primary Representation | Binary, Permutation, Value-based [66] | Real-valued vectors [10] |
| Core Strength | Discrete/combinatorial optimization [10] | Continuous parameter optimization [10] [68] |
| Key Operators | Selection, Crossover, Mutation [26] | Differential Mutation, Crossover, Greedy Selection [10] |
| Parameter Sensitivity | Moderately sensitive to crossover & mutation rates [26] | Highly sensitive to scaling factor (F) & crossover rate (CR) [10] [38] |
| Convergence Speed | Can be slower, prone to premature convergence [68] | Generally faster and more robust on continuous problems [10] [68] |
| Ideal Problem Types | Scheduling, Routing, Feature Selection, Rule Discovery | Engineering Design, Hyperparameter Tuning, Chemical Parameter Fitting [10] |
Empirical Performance Evidence
Experimental studies across various domains consistently highlight the performance trade-offs between GA and DE.
Table 2: Empirical Performance Comparison in Controller Tuning and Optimization
| Study Context | Reported Performance | Key Finding |
|---|---|---|
| Position Domain PID Controller Tuning [68] | DE featured the highest performance indexes. PSO was efficient for linear contours. GA featured premature convergence in all cases. | DE outperformed both PSO and GA for nonlinear contour tracking, demonstrating superior efficiency and consistency. |
| General Optimization [10] | DE produces better, more stable solutions than GA. DE works well for complex problems (multi-objective, neural network training). | DE is viewed as an improvement over GA, particularly for real-valued function optimization, due to its vector-based operations. |
| Chemometrics & Experimental Design [10] | DE provides fast, efficient optimization of any real, vector-valued function. It requires fewer tuning parameters than many other metaheuristics. | DE is presented as a powerful, yet underutilized, alternative to GA for finding optimal experimental designs in chemical applications. |
A notable limitation of GA is its tendency to converge towards local optima or even arbitrary points rather than the global optimum, especially on complex fitness landscapes [26]. This premature convergence can be mitigated by adjusting the fitness function or increasing mutation rates, but it remains a inherent challenge. DE's differential mutation operation often provides a more effective balance, helping it escape local optima and maintain robust search performance across diverse problem landscapes [10] [68].
Implementation Protocols and Best Practices
Experimental Setup and Parameter Tuning
Implementing GA or DE effectively requires careful attention to their respective parameter tuning and population management strategies.
Genetic Algorithm Protocol:
- Population Initialization: Generate a population of ( N ) individuals. For binary GAs, each chromosome is a string of 0s and 1s. Permutation encodings are used for ordering problems [66].
- Fitness Evaluation: Define a problem-specific fitness function. The fitness guides the selection process, favoring individuals with higher fitness values [26] [66].
- Selection and Variation: Apply selection (e.g., roulette wheel, tournament) to choose parents. Perform crossover (e.g., single-point) with probability ( pc ) and mutation (bit-flip) with a low probability ( pm ) [66] [67].
- Termination: Run for a predefined number of generations or until fitness plateau is observed [26].
Differential Evolution Protocol:
- Population Initialization: Generate a population of ( NP ) real-valued vectors, each of dimension ( D ), within the specified lower and upper bounds [38]. ( x{ij}(0) = rand(0,1) \times (x{ij}^U - x{ij}^L) + x{ij}^L )
- Mutation and Crossover: For each target vector ( \vec{x}i ), generate a donor vector via a mutation strategy (e.g., DE/rand/1). Create a trial vector ( \vec{u}i ) through binomial crossover controlled by ( CR ) [10] [38] [68].
- Greedy Selection: Compare the trial vector ( \vec{u}i ) directly to the target vector ( \vec{x}i ). Select the fitter one for the next generation [10].
- Parameter Settings: Mutation factor ( F ) is typically in [0, 2], and crossover rate ( CR ) in [0, 1]. ( F ) controls step size, while ( CR ) controls the influence of the donor vector [10] [38].
The Scientist's Toolkit: Key Research Reagents
Table 3: Essential Computational Tools for Evolutionary Algorithm Research
| Tool/Component | Function in Algorithm Implementation | Example Usage/Note |
|---|---|---|
| Fitness Function | Evaluates candidate solution quality; guides evolutionary search [26]. | Problem-specific; can be computationally expensive (e.g., simulating a chemical process). |
| Encoding Scheme | Represents a candidate solution in a form the algorithm can process [66]. | Binary (GA), Real-valued (DE), Permutation (for sequencing). |
| Selection Operator | Selects parent solutions based on fitness for reproduction [67]. | Roulette Wheel, Tournament, Rank-based selection. |
| Variation Operators | Creates new solutions by recombining (crossover) or perturbing (mutation) parents [26] [10]. | Single-point crossover (GA), Differential mutation (DE). |
| Parameter Set | Controls algorithm behavior and performance [26] [10]. | Population size (( N )), Mutation/Scaling Factor (( F )), Crossover Rate (( CR )). |
Genetic Algorithms and Differential Evolution are powerful optimization tools with distinct operational profiles. GA, with its flexible representation scheme, is a traditional and often effective choice for discrete and combinatorial problems. Conversely, DE, with its efficient differential mutation and greedy selection, excels at continuous optimization problems, frequently demonstrating faster convergence and superior robustness compared to GA [10] [68].
The choice between GA and DE should be primarily guided by the nature of the decision variables in the target problem. For drug development professionals, this translates to selecting DE for continuous parameter fitting tasks, such as optimizing kinetic parameters in pharmacokinetic models or tuning hyperparameters of quantitative structure-activity relationship (QSAR) models. GA remains a strong candidate for discrete optimization tasks, such as molecular docking pose selection or feature selection for biomarker discovery. Future work may focus on hybrid approaches and adaptive parameter control, such as reinforcement learning-based DE [38], to further enhance performance and automate the optimization process for complex scientific inquiries.
Empirical Evidence: Benchmarking Performance and Analyzing Strengths
The selection of an appropriate optimization algorithm is critical for solving complex engineering problems characterized by high-dimensional, non-linear, and combinatorial solution spaces. Within the class of evolutionary algorithms, Genetic Algorithms (GA) and Differential Evolution (DE) have emerged as prominent techniques for handling such challenges. While both algorithms operate on population-based principles inspired by natural evolution, their methodological approaches and performance characteristics differ significantly. This technical guide provides an in-depth comparative analysis of GA and DE performance across multiple engineering domains, with particular emphasis on in-core fuel management as a case study, to inform algorithm selection for researchers and practitioners.
Fundamental Algorithmic Mechanisms
Genetic Algorithm Framework
Genetic Algorithms, introduced by John Holland in 1975, operate through a cycle of selection, crossover, and mutation operations applied to a population of candidate solutions [10]. Each solution is typically encoded as a discrete data structure (chromosome) comprising multiple genes. The algorithm emphasizes crossover as its primary exploratory mechanism, combining genetic material from parent solutions to produce offspring with potentially superior fitness [69]. GAs have demonstrated particular effectiveness for optimization problems involving discrete variables and combinatorial solution spaces, making them suitable for scheduling, routing, and topology optimization problems [69] [70].
Differential Evolution Framework
Differential Evolution, proposed by Storn and Price in 1997, is specifically designed for continuous optimization problems [3] [10]. DE employs a different operational sequence, where mutation precedes crossover as the primary driving mechanism. The distinctive feature of DE is its mutation strategy, which generates new candidate solutions by calculating weighted difference vectors between existing population members [71]. This approach enables DE to efficiently explore the search space by automatically adapting step sizes based on the distribution of the current population. DE requires fewer control parameters compared to GA and has demonstrated superior performance on many real-valued optimization problems [10] [72].
Key Algorithmic Differences
The table below summarizes the fundamental operational differences between GA and DE:
Table 1: Fundamental Operational Differences Between GA and DE
| Aspect | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Primary Search Operator | Crossover-driven | Mutation-driven |
| Parameter Encoding | Typically discrete/binary | Continuous/real-valued |
| Variable Handling | Effective for discrete variables | Superior for continuous variables |
| Mutation Mechanism | Random perturbation | Difference vector-based |
| Selection Pressure | Generally lower | Generally higher |
| Parameter Sensitivity | More parameters to tune | Fewer control parameters |
Nuclear Engineering Case Study: In-Core Fuel Management
Problem Formulation
In-core fuel management optimization (ICFMO) represents a challenging class of problems in nuclear engineering with significant economic and safety implications [73]. The ICFMO problem involves determining the optimal configuration and reloading pattern for nuclear reactor fuel assemblies to maximize performance metrics while respecting multiple physical constraints. This problem exhibits several challenging characteristics:
- Large combinatorial solution space with multiple conflicting objectives [73]
- Non-linear objective functions with constraints on criticality, power peaking factors, and thermal limits [71]
- Requirement to simultaneously maximize fuel cycle length while minimizing power peaking factor [73]
Experimental Protocol and Methodology
A comparative study between DE and GA was conducted on the Dalat Nuclear Research Reactor (DNRR), employing the following methodological framework [73]:
Objective Function Formulation: Defined a multi-objective function targeting both maximization of cycle length and minimization of power peaking factor
Algorithm Implementation:
- DE utilized the DE/rand/1/bin mutation strategy with carefully tuned parameters
- GA employed standard selection, crossover, and mutation operators with binary encoding
Parameter Tuning: Conducted preliminary sensitivity analysis to determine optimal parameter values for both algorithms to ensure fair comparison
Performance Metrics: Evaluated based on solution quality (fitness value at convergence) and computational efficiency (number of generations to convergence)
Validation: Compared results against actual reactor operating configuration to assess practical improvement
Results and Performance Analysis
The comparative analysis demonstrated that DE consistently outperformed GA in solving the ICFMO problem for the DNRR case study [73]. Specific findings included:
- DE achieved superior solution quality with better fitness values (combined cycle length and power peaking factor)
- DE exhibited faster convergence characteristics, requiring fewer generations to reach near-optimal solutions
- Both algorithms produced satisfactory results that improved upon the actual reactor configuration
- The performance advantage of DE was attributed to its efficient exploration of the continuous search space inherent in the reactor physics parameters
These findings align with another nuclear reactor core design study that reported DE and its variant (DERL) "outperformed the more established GA and PSO algorithms in a challenging optimization problem" [71].
Figure 1: Experimental workflow for the comparative analysis of GA and DE in in-core fuel management optimization
Performance Analysis in Additional Engineering Domains
Water Distribution Systems Design
A comprehensive comparative study evaluated DE and GA performance on six benchmark water distribution system (WDS) design problems with decision variables ranging from 8 to 454 dimensions [72]. The experimental protocol included sensitivity analysis to determine optimal parameter values for both algorithms, ensuring equitable comparison conditions. Results demonstrated that DE consistently outperformed GA in both efficiency and solution quality across all case studies [72]. The performance advantage became particularly pronounced as problem dimensionality increased, suggesting DE better handles high-dimensional optimization problems.
Heat Exchanger Network Retrofit
In chemical process engineering, a parallelized hybrid GA-DE algorithm was developed for heat exchanger network (HEN) retrofit optimization under multi-period operations [70]. The hybrid approach leveraged the complementary strengths of both algorithms:
- GA handled discrete topology variables (existence and configuration of heat exchangers)
- DE optimized continuous heat load variables across multiple operating periods
This specialized hybrid implementation demonstrated that combining both algorithms could effectively address mixed-integer optimization problems with both discrete and continuous variables [70].
Unit Commitment Scheduling Problem
In power systems engineering, the unit commitment (UC) problem presents a high-dimensional, highly constrained, mixed-integer optimization challenge. Research introduced a hGADE hybrid framework that integrated GA for handling binary variables (unit on/off status) and DE for continuous variables (power dispatch levels) [69]. Extensive case studies demonstrated that the hybrid approach outperformed individual algorithm implementations, particularly for large-scale test systems with numerous constraints.
Quantitative Performance Comparison
The table below summarizes key performance metrics for GA and DE across multiple engineering applications:
Table 2: Performance Comparison of GA and DE Across Engineering Domains
| Application Domain | Problem Dimension | GA Performance | DE Performance | Key Findings |
|---|---|---|---|---|
| In-Core Fuel Management [73] | Multi-objective with constraints | Satisfactory | Superior | DE achieved better fitness values with faster convergence |
| Water Distribution Systems [72] | 8-454 variables | Competitive | Superior | DE consistently outperformed GA in efficiency and solution quality |
| Nuclear Reactor Core Design [71] | Constrained continuous optimization | Good | Better | DE and DERL variants outperformed established GA and PSO |
| Unit Commitment Problem [69] | Mixed-integer, high-dimensional | Effective for binary variables | Effective for continuous variables | Hybrid hGADE framework performed best |
| Heat Exchanger Networks [70] | Mixed-integer, multi-period | Effective for topology | Effective for heat loads | Hybrid approach successfully addressed complexity |
Table 3: Essential Components for GA and DE Implementation in Engineering Optimization
| Component | Function | Implementation Considerations |
|---|---|---|
| Population Initialization | Generates initial candidate solutions | Halton sequences improve uniformity [38]; Random initialization with boundary constraints [3] |
| Fitness Function | Evaluates solution quality | Problem-specific; Must accurately represent engineering objectives and constraints [73] [71] |
| Mutation Operators | Introduces population diversity | DE: Difference vector-based [71]; GA: Random perturbation [69] |
| Crossover/Recombination | Combines parent solutions | DE: Binomial/Exponential [10]; GA: Single/Multi-point [69] |
| Selection Mechanisms | Determines population for next generation | DE: Greedy one-to-one selection [3]; GA: Tournament, Roulette [25] |
| Constraint Handling | Manages feasible solution search | Penalty functions [70]; Preserving strategies [70]; Repair mechanisms |
| Parameter Tuning | Optimizes algorithm parameters | Sensitivity analysis essential [72]; Adaptive methods improve performance [38] |
Advanced DE Variants and Recent Improvements
Recent research has focused on addressing DE's limitations, particularly its parameter sensitivity and premature convergence tendencies. A reinforcement learning-based DE variant (RLDE) incorporates several enhancements [38]:
- Halton sequence initialization for improved population diversity
- Policy gradient network for dynamic parameter adjustment
- Hierarchical mutation mechanism based on fitness-based population classification
Testing on 26 standard benchmark functions demonstrated that RLDE significantly enhanced global optimization performance compared to canonical DE and other heuristic algorithms [38]. Such hybrid and enhanced approaches represent promising directions for further algorithmic improvements.
Figure 2: Algorithm selection guidance based on problem characteristics and empirical performance evidence
This comprehensive analysis of GA and DE performance across multiple engineering domains, with emphasis on in-core fuel management optimization, demonstrates the context-dependent superiority of each algorithm. The evidence suggests that DE generally outperforms GA for continuous optimization problems across nuclear engineering, water distribution systems, and reactor design applications. However, GA maintains advantages for problems with substantial discrete or combinatorial elements. The emerging trend of hybrid GA-DE frameworks represents a promising approach for complex engineering problems containing both discrete and continuous variables, leveraging the complementary strengths of both algorithms. For practitioners, algorithm selection should be guided by problem characteristics: DE for predominantly continuous domains, GA for strongly discrete problems, and hybrid approaches for mixed-integer challenges.
The selection of an appropriate optimization algorithm is pivotal for solving complex problems in fields such as drug development and manufacturing system design. For researchers and scientists entering this domain, understanding the performance characteristics of different algorithms is essential. This technical guide provides a comprehensive convergence analysis of two prominent evolutionary algorithms: Genetic Algorithms (GA) and Differential Evolution (DE). We examine their relative performance in terms of convergence speed (how quickly an algorithm approaches the optimal solution) and consistency (the reliability of this performance across multiple runs) [74] [75].
The performance gap between these algorithms is not merely theoretical. Studies applying these methods to complex real-world problems reveal significant differences in their optimization capabilities. For instance, in cognitive radio engine design, DE has demonstrated superior performance in terms of fitness value, convergence speed, and stability compared to traditional GA approaches [74]. Similarly, a comparative study on combinatorial problems concluded that DE's most significant advantage over GA is its enhanced stability across various problem types [76].
Theoretical Foundations of Convergence
Convergence analysis examines how optimization algorithms approach optimal solutions. The Average Convergence Rate (ACR) serves as a key metric, measuring how rapidly the approximation error of an evolutionary algorithm converges to zero per generation [77]. Theoretical work has established that for objective functions satisfying the Lipschitz condition, evolutionary algorithms with positive-adaptive mutation operators can achieve linear average convergence rates [77]. This means the error decreases exponentially with iterations, which is highly desirable for complex optimization problems.
The convergence behavior of these algorithms is fundamentally influenced by their balance between exploration (searching new regions of the solution space) and exploitation (refining known good solutions). DE naturally exhibits strong exploratory characteristics in early optimization stages before gradually becoming more exploitative, while GA often requires explicit mechanisms to maintain this balance [75].
Comparative Performance Analysis
Quantitative Performance Metrics
Table 1: Comparative Performance Metrics of GA and DE
| Performance Metric | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Convergence Speed | Moderate, can stagnate prematurely [75] | Generally faster, especially in early iterations [74] [76] |
| Solution Consistency | Variable across runs [76] | Higher stability and reliability [76] |
| Parameter Sensitivity | High sensitivity to parameter settings [75] | Fewer control parameters, but sensitive to scaling factor and crossover rate [75] |
| Global Search Capability | Good, but prone to premature convergence [78] | Excellent, maintains population diversity effectively [38] |
| Local Refinement | Effective with proper operator design [78] | Can require specialized strategies for fine-tuning [75] |
Application-Specific Performance
The relative performance of GA and DE varies across problem domains. In cognitive radio engine optimization, DE demonstrated superior performance in terms of fitness value, convergence speed, and stability compared to GA [74]. For facility layout design in manufacturing systems, a hybrid GA approach incorporating chaos theory and dominant block mining proved superior to traditional methods in both accuracy and efficiency [78].
Recent improvements to DE through reinforcement learning have demonstrated enhanced global optimization performance, particularly in addressing the algorithm's tendency toward premature convergence in complex scenarios [38]. Similarly, extensions to GA incorporating biological life-cycle concepts have shown improvements in maintaining diversity and adaptability, leading to better convergence speed and solution quality [79].
Experimental Methodologies for Convergence Analysis
Standard Benchmark Evaluation
Rigorous evaluation of convergence performance requires standardized testing methodologies. Researchers typically employ benchmark functions including Ackley, Rastrigin, Griewank, and Rosenbrock functions, which provide well-established test cases with known optimal solutions [77] [38]. The IEEE Congress on Evolutionary Computation (CEC) benchmark suites (e.g., CEC-2017, CEC-2019) offer standardized testing frameworks for comparative algorithm analysis [75] [79].
Experimental protocols should include:
- Multiple independent runs (typically 30+) to account for stochastic variations
- Statistical significance testing using Wilcoxon signed-rank tests or Friedman tests [75]
- Convergence trajectory analysis tracking best fitness values across generations
- Population diversity measurement throughout the evolutionary process
Real-World Problem Validation
Beyond benchmark functions, algorithm performance should be validated on real-world problems. In pharmaceutical applications, this might include:
- Molecular docking optimization for drug discovery
- Drug design parameter optimization including properties and activities [23]
- Clinical trial design optimization predicting outcomes and enabling drug repositioning [23]
For engineering applications, validated problems include:
- Unmanned Aerial Vehicle (UAV) task assignment [38]
- Facility layout design in manufacturing systems [78]
- Mechanical design optimization with non-convex constraints [75]
Visualization of Algorithm Convergence Behavior
Convergence Dynamics Workflow
Convergence Rate Comparison
Research Reagent Solutions
Table 2: Essential Computational Tools for Convergence Analysis
| Research Tool | Function | Application Context |
|---|---|---|
| IEEE CEC Benchmark Suites | Standardized test functions for performance comparison [75] | Algorithm validation and comparative studies |
| Statistical Test Frameworks | Wilcoxon signed-rank and Friedman tests for significance verification [75] | Determining statistical significance of performance differences |
| Reinforcement Learning Policy Networks | Dynamic parameter adjustment for adaptive optimization [38] | Enhancing DE performance through parameter adaptation |
| Chaotic Initialization Methods | Improved Tent map for population diversity enhancement [78] | Generating high-quality initial populations for GA |
| Association Rule Mining | Dominant block identification to reduce problem complexity [78] | Complexity reduction in facility layout optimization |
| Halton Sequence Initialization | Uniform population initialization for improved solution coverage [38] | Enhancing initial population quality in DE |
| Multi-Objective Optimization Metrics | Performance assessment for conflicting objectives [74] | Problems requiring balance of multiple performance criteria |
Discussion and Research Implications
The convergence analysis presented indicates that DE generally exhibits more consistent performance and better convergence characteristics than basic GA across a range of optimization problems [74] [76]. However, advanced hybrid approaches and modifications to both algorithms can significantly enhance their performance.
For drug development professionals, these findings have practical implications. The consistency of DE makes it particularly valuable for pharmaceutical applications where reproducible results are essential. DE's strength in handling high-dimensional problems aligns well with complex molecular optimization challenges in drug discovery [23]. However, recent GA extensions incorporating biological life-cycle concepts may offer advantages for specific drug design problems where maintaining diverse solution populations is critical [79].
Future research directions should focus on developing more adaptive hybridization strategies that leverage the strengths of both algorithms. The integration of reinforcement learning for parameter adaptation, as demonstrated in recent DE improvements [38], represents a promising approach for enhancing convergence performance in pharmaceutical applications and other complex optimization domains.
In the realm of evolutionary computation, robust statistical evaluation is paramount for drawing meaningful conclusions about algorithm performance. When comparing optimization algorithms like Genetic Algorithms (GAs) and Differential Evolution (DE), researchers must account for inherent stochasticity through appropriately designed experiments and rigorous statistical analysis. Single-run comparisons often yield misleading results due to random initialization and probabilistic operators, making multiple independent runs essential for reliable performance assessment [27] [64].
Statistical performance evaluation enables researchers to determine whether observed differences in algorithm performance are statistically significant rather than attributable to random chance. This is particularly crucial when benchmarking algorithms for scientific research or practical applications such as drug development, where optimization reliability directly impacts outcomes [80]. Proper evaluation methodologies provide insights into not only which algorithm performs better on average but also their consistency, convergence properties, and robustness across diverse problem domains.
This technical guide examines established protocols for statistical performance evaluation, focusing specifically on comparisons between GA and DE algorithms. Through structured experimental design, appropriate metric selection, and rigorous statistical testing, researchers can generate reliable evidence about relative algorithm performance to inform algorithm selection and development decisions.
Foundational Concepts: Genetic Algorithms vs. Differential Evolution
Algorithmic Structures and Mechanisms
Genetic Algorithms (GAs) and Differential Evolution (DE) both belong to the broader class of population-based evolutionary algorithms but employ distinct operational mechanisms. GAs typically utilize selection, crossover, and mutation operators inspired by biological evolution, with common selection strategies including tournament selection and roulette wheel selection [27]. The algorithm maintains a population of candidate solutions that undergo recombination and mutation to explore the search space, with selection pressure guiding the population toward improved solutions over generations.
In contrast, Differential Evolution employs a different approach characterized by its unique mutation strategy. DE generates new candidate solutions by combining scaled differences between population members with base vectors, followed by crossover operations. The canonical DE mutation strategy "DE/rand/1/bin" creates mutant vectors according to the formula:
[ \vec{v}{i,g+1} = \vec{x}{r1,g} + F \cdot (\vec{x}{r2,g} - \vec{x}{r3,g}) ]
where (\vec{x}{r1,g}), (\vec{x}{r2,g}), and (\vec{x}_{r3,g}) are distinct population vectors, and (F) is the scaling factor controlling differential variation [64]. This differential mutation mechanism enables DE to effectively explore search spaces without explicit gradient information.
Key Operational Differences
The fundamental distinction between GA and DE lies in their mutation operations. While GA typically applies small random perturbations to individuals, DE utilizes difference vectors between population members to direct search, creating a self-adjusting step size mechanism [12]. Additionally, DE performs selection after generating trial vectors, immediately replacing parents with superior offspring in a steady-state fashion, whereas GA often employs generational replacement [2].
Research indicates that DE's exploration-exploitation balance often differs from GA, with DE demonstrating stronger robustness in approaching global optima across various problem domains [27]. However, the relative performance of these algorithms is highly problem-dependent, necessitating empirical evaluation for specific applications such as drug development optimization problems.
Table 1: Core Operational Differences Between GA and DE
| Feature | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Mutation Strategy | Random perturbations | Scaled vector differences |
| Selection Timing | Typically generational | Steady-state, greedy |
| Parameter Sensitivity | Highly dependent on operator probabilities | Fewer control parameters (F, CR) |
| Exploration Mechanism | Crossover-driven recombination | Difference vector-directed search |
| Common Variants | Tournament selection, Roulette wheel | DE/rand/1/bin, DE/best/1/bin |
Experimental Design for Multiple Independent Runs
Determining Run Quantity and Termination Criteria
Conducting multiple independent runs is essential for obtaining statistically meaningful algorithm comparisons. The specific number of runs depends on desired confidence levels and performance metric variability, but empirical studies often employ 50 independent runs for robust statistical analysis [27]. Each run should begin with different random seeds to ensure population initialization diversity while maintaining identical experimental conditions across compared algorithms.
Termination criteria must be consistently applied across all runs and algorithms. Common approaches include: (1) fixed number of generations or function evaluations, (2) convergence-based criteria when improvement rates fall below thresholds, and (3) computation time limits [2]. For fair comparison, function evaluation counts should be identical for all algorithms, enabling direct performance comparison at equivalent computational budgets.
Parameter Configuration and Tuning
Algorithm parameters significantly influence performance and must be carefully calibrated before comparative evaluation. GA performance depends on parameters including population size, crossover rate, mutation probability, and selection mechanism [27]. DE requires fewer control parameters, primarily the scaling factor (F) and crossover rate (CR), though these significantly impact performance [38].
Comprehensive parameter surveys should precede final comparative experiments. For example, researchers might evaluate multiple crossover types (one-point, two-point), mutation probabilities, and elitist archive sizes for GA, similarly testing various F and CR values for DE [27]. Parameter tuning should utilize separate validation problems or training subsets distinct from final test problems to prevent overfitting.
Figure 1: Experimental workflow for statistical performance evaluation of evolutionary algorithms
Performance Metrics and Data Collection
Fitness and Solution Quality Metrics
The primary metric for optimization algorithm performance is typically the objective function value or fitness of obtained solutions. For comprehensive comparison, researchers should record both the best fitness and average fitness across population members at each generation [27]. This enables analysis of not only final solution quality but also population diversity and convergence behavior.
When comparing GA and DE, common fitness-based metrics include:
- Best fitness: The optimal objective value found across all runs
- Mean best fitness: Average of best solutions across multiple runs
- Standard deviation: Variability in solution quality across runs
- Success rate: Percentage of runs locating solutions within specified tolerance of global optimum
For multi-objective problems, additional metrics like hypervolume or Pareto front coverage may be necessary, though these extend beyond our current focus on single-objective optimization.
Convergence and Efficiency Measures
Beyond final solution quality, convergence speed provides crucial algorithm performance insights. Researchers should track best fitness progression throughout runs, enabling generation of convergence curves that visualize how quickly algorithms approach optimal regions [2]. The area under convergence curve can quantify overall convergence efficiency, while number of function evaluations to reach target precision measures optimization speed.
Statistical analysis of convergence behavior might include comparing generations or evaluations required to first reach specific solution quality thresholds. DE often demonstrates faster convergence than GA in continuous optimization problems, though sometimes at risk of premature convergence [27] [38].
Table 2: Essential Performance Metrics for Algorithm Comparison
| Metric Category | Specific Metrics | Interpretation |
|---|---|---|
| Solution Quality | Best fitness, Mean best fitness, Standard deviation | Ultimate optimization capability and reliability |
| Convergence Behavior | Generations to threshold, Area under curve, Success rate | Optimization speed and efficiency |
| Robustness | Performance across problem variants, Parameter sensitivity | Algorithm consistency and reliability |
| Statistical Significance | p-values, Effect sizes, Confidence intervals | Reliability of observed performance differences |
Statistical Testing Frameworks
Non-Parametric Hypothesis Tests
Due to typically non-normal distributions of performance metrics, non-parametric statistical tests are generally preferred for evolutionary algorithm comparisons [64] [80]. These tests make fewer distributional assumptions and are better suited for the often skewed or outlier-prone results from stochastic optimization algorithms.
The Wilcoxon signed-rank test serves as a robust choice for pairwise algorithm comparisons across multiple problems [64]. This test ranks absolute performance differences between paired observations, comparing the sums of ranks for positive and negative differences. Similarly, the Mann-Whitney U test (also called Wilcoxon rank-sum test) compares two independent samples, making it suitable for metrics like best fitness values from independent runs [27] [64].
For comparisons involving more than two algorithms, the Friedman test with corresponding Nemenyi post-hoc analysis provides a non-parametric alternative to repeated-measures ANOVA [64]. These tests rank algorithm performance for each problem instance, then compare average ranks across all problems to identify significant differences.
Interpreting Test Results and P-Values
When applying statistical tests, the null hypothesis typically states that no performance difference exists between algorithms [80]. Small p-values (conventionally < 0.05) indicate strong evidence against the null hypothesis, suggesting statistically significant performance differences.
However, p-values alone provide incomplete information. Effect size measures like Cohen's d or Cliff's delta should accompany significance tests to quantify the magnitude of performance differences [80]. Additionally, confidence intervals for performance metric differences offer more informative comparisons than binary significance declarations.
A comprehensive statistical evaluation should also assess practical significance—whether observed differences matter in real-world applications. For drug development optimization, even statistically significant differences may be practically irrelevant if all algorithms find clinically equivalent solutions.
Figure 2: Statistical testing decision framework for algorithm performance comparison
Case Study: GA vs. DE in Research Reactor Optimization
Experimental Methodology and Implementation
A comprehensive comparison between GA and DE was conducted for in-core fuel management (ICFM) optimization of the DNRR research reactor [27]. This real-world engineering problem involved optimizing loading patterns for 100 highly enriched uranium fuel bundles, representing a challenging 100-dimensional combinatorial optimization problem with objectives of maximizing fuel cycle length while flattening power distribution.
Researchers implemented two GA variants: GA1 with tournament selection and GA2 with roulette wheel selection, both employing two-point crossover and scramble mutation operators [27]. These were compared against a basic DE implementation using the "DE/rand/1/bin" mutation strategy. All algorithms utilized identical population size (NP=30), fitness function, and convergence criterion (500 generations) to ensure fair comparison.
Each algorithm underwent 50 independent runs with different random seeds, with best fitness values recorded for statistical analysis. This substantial number of runs provided robust datasets for reliable statistical comparison and power to detect meaningful performance differences.
Statistical Analysis and Interpretation
Performance data from 50 independent runs were analyzed using Kruskal-Wallis and Mann-Whitney tests, non-parametric alternatives to one-way ANOVA and t-tests, respectively [27]. Results demonstrated that GA1 with tournament selection and DE exhibited statistically equivalent performance, with both significantly outperforming GA2 with roulette wheel selection.
Despite similar average performance, the algorithms displayed distinct behavioral characteristics: DE demonstrated superior exploration capability and stronger robustness, becoming trapped in local optima in fewer runs (approximately 26%) compared to GA1 (26%) and GA2 (38%) [27]. However, the single best solutions from GA1 and GA2 after 50 runs slightly outperformed DE's best solution, suggesting potential benefits from combining DE's reliability with GA's refinement capability.
Table 3: Case Study Results - GA vs. DE Performance Comparison
| Algorithm | Mean Best Fitness | Local Optima Trapping Rate | Statistical Ranking | Remarks |
|---|---|---|---|---|
| GA1 (Tournament) | 0.92 | 26% | 1 | Best individual solution found |
| GA2 (Roulette Wheel) | 0.87 | 38% | 3 | Lowest performance |
| DE (rand/1/bin) | 0.91 | 26% | 2 | Most robust exploration |
Advanced Evaluation Techniques
Behavioral Analysis and Search Characteristics
Beyond traditional fitness-based metrics, advanced evaluation techniques analyze algorithm behavior and search characteristics. The cross-match test compares multivariate distributions of solutions explored during optimization processes, providing insights into whether different algorithms exhibit similar search behaviors [81]. This approach helps identify redundant algorithms despite superficial operational differences.
Behavioral analysis examines how algorithms explore fitness landscapes, including diversity maintenance, exploration-exploitation balance, and adaptive capabilities throughout evolutionary processes. For example, DE's differential mutation creates a self-scaling property that automatically adjusts search step sizes based on population distribution, while GA typically maintains more consistent exploration patterns throughout execution [12] [2].
Reinforcement Learning for Parameter Adaptation
Recent advances integrate reinforcement learning (RL) with evolutionary algorithms to create adaptive parameter control mechanisms. The RLDE algorithm exemplifies this approach, using a policy gradient network to dynamically adjust DE's scaling factor F and crossover probability CR based on evolutionary state [38]. This addresses DE's parameter sensitivity issues and demonstrates improved performance across standard test functions.
Similar approaches could benefit GA by adaptively adjusting selection pressure, mutation rates, or crossover operators throughout execution. For drug development applications where objective function evaluations may be computationally expensive (e.g., molecular docking simulations), such adaptive mechanisms can significantly enhance optimization efficiency without manual parameter tuning.
The Scientist's Toolkit: Essential Research Reagents
Table 4: Essential Methodological Components for Robust Algorithm Evaluation
| Research Component | Function | Implementation Examples |
|---|---|---|
| Benchmark Problems | Provide standardized test suites | CEC benchmark functions, BBOB suite, domain-specific problems |
| Statistical Testing Framework | Quantify significance of performance differences | Wilcoxon signed-rank test, Friedman test, Mann-Whitney U test |
| Performance Metrics | Measure algorithm effectiveness and efficiency | Best fitness, convergence speed, success rate, robustness |
| Parameter Tuning Protocols | Ensure fair algorithm comparison | Grid search, racing techniques, REVAC methodology |
| Behavioral Analysis Tools | Characterize search dynamics | Cross-match test, fitness landscape analysis, diversity measures |
Statistical performance evaluation through multiple independent runs provides the foundation for reliable comparisons between evolutionary algorithms like Genetic Algorithms and Differential Evolution. Robust experimental design, appropriate metric selection, and rigorous statistical analysis collectively enable researchers to draw meaningful conclusions about relative algorithm performance.
The case study demonstrates that while DE often exhibits advantages in exploration reliability, advanced GA variants can achieve competitive performance, with optimal algorithm selection being problem-dependent. For drug development professionals and researchers, these methodologies offer structured approaches to evaluate optimization algorithms for specific applications, ensuring that algorithm selection decisions rest on statistically sound evidence rather than anecdotal observations.
Future directions in performance evaluation include increased emphasis on behavioral analysis, adaptive algorithm frameworks, and problem-specific benchmark development. By adopting comprehensive evaluation methodologies, researchers can advance evolutionary computation capabilities while maintaining scientific rigor in algorithm development and comparison.
For researchers, scientists, and drug development professionals embarking on computational optimization, selecting the appropriate algorithm is a critical first step. In the context of a broader thesis on genetic algorithm vs differential evolution for beginners research, this guide provides an in-depth comparison of two prominent evolutionary algorithms (EAs): Genetic Algorithms (GA) and Differential Evolution (DE). Both methods belong to the class of population-based, metaheuristic optimization techniques inspired by natural evolution. They are particularly valuable for handling complex, non-linear, and non-differentiable objective functions commonly encountered in fields like drug discovery and systems biology, where gradient-based methods often fail. Understanding their core mechanisms, relative strengths, and weaknesses is essential for their effective application.
Core Algorithmic Mechanisms
The fundamental operational principles of GA and DE dictate their performance and suitability for different problems.
Genetic Algorithm (GA)
GA operates on a population of candidate solutions, typically represented as fixed-length chromosomes (e.g., bit strings or real-valued vectors). Its workflow is characterized by a selection-recombination-mutation cycle [82]:
- Selection: Individuals are chosen for reproduction based on their fitness, emulating the survival-of-the-fittest principle. Techniques like roulette wheel or tournament selection are common.
- Crossover (Recombination): This is the primary search operator in GA. It creates new offspring by combining genetic information from two or more parent solutions. A simple example is single-point crossover, where segments of parent chromosomes are swapped.
- Mutation: This operator introduces random, small-scale changes to an offspring's chromosome with a low probability. It helps maintain population diversity and enables exploration of new regions in the search space.
A simple GA, as visualized in Figure 1, often retains only a top percentage (e.g., 10%) of the best-performing solutions (the elite) from one generation. The next generation is then filled by creating offspring through crossover and mutation applied to this elite group [82].
Differential Evolution (DE)
DE is a specialized EA specifically designed for continuous optimization problems. It evolves a population of real-valued vectors through a distinctive mutation-crossover-selection cycle [83]:
- Mutation: DE generates a donor vector for each target vector in the population. The most common strategy, "DE/rand/1," creates a donor vector ( \vec{vi} ) by combining three distinct random population vectors: ( \vec{vi} = \vec{x{r1}} + F \cdot (\vec{x{r2}} - \vec{x{r3}}) ). The scaling factor ( F ) controls the amplification of the differential variation ( (\vec{x{r2}} - \vec{x_{r3}}) ) [83].
- Crossover: The donor vector ( \vec{vi} ) mixes with the target vector ( \vec{xi} ) to produce a trial vector ( \vec{ui} ). Binomial crossover is standard, where each component of ( \vec{ui} ) is inherited either from the donor or the target based on a crossover probability ( Cr ) [83].
- Selection: DE employs a one-to-one greedy selection scheme. The trial vector ( \vec{ui} ) is compared directly with its parent target vector ( \vec{xi} ). The better of the two advances to the next generation [83].
Figure 1: A comparative workflow of a Simple Genetic Algorithm and Differential Evolution.
Structured Comparative Analysis
The table below summarizes the key characteristics of GA and DE, providing a clear framework for comparison.
Table 1: A structured comparison of Genetic Algorithms and Differential Evolution.
| Feature | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Core Philosophy | Mimics genetic inheritance: selection, crossover, mutation [82]. | Leverages vector differences for exploration and exploitation [83]. |
| Representation | Flexible (binary, integer, real-valued) [82]. | Primarily real-valued vectors [83]. |
| Primary Operators | Selection & Crossover are dominant [82]. | Differential Mutation is the main driver [83]. |
| Selection Mechanism | Often fitness-proportional; selects multiple parents for recombination [82]. | One-to-one greedy selection; offspring competes directly with its parent [83]. |
| Parameter Sensitivity | Highly sensitive to crossover and mutation rates. | Highly sensitive to the scaling factor ( F ) and crossover rate ( Cr ) [83]. |
| Performance on Noisy/Local Optima | Can maintain diversity but may converge prematurely. Known for discovering diverse solutions [82]. | Exceptional at escaping local optima due to its differential mutation scheme [83]. |
| Typical Application Scope | Broad, including discrete and combinatorial optimization (scheduling, feature selection). | Excellent for continuous parameter optimization (model fitting, engineering design) [83]. |
Key Strengths and Weaknesses
Genetic Algorithms:
- Strengths:
- Versatility: Can be applied to a wide range of problems, including those with discrete or mixed-variable search spaces, through appropriate chromosome encoding [82].
- Solution Diversity: The selection and crossover process can help maintain a diverse population, leading to the exploration of various regions in the search space. Policies discovered by GA and other evolution strategies are often found to be more diverse compared to those found by other algorithms [82].
- Weaknesses:
Differential Evolution:
- Strengths:
- Strong Global Search Capability: The differential mutation operator is highly effective at exploring the search space and avoiding local optima, making it a powerful global optimizer [83].
- Simple and Efficient: The algorithm's structure is straightforward, yet it often demonstrates fast and robust convergence on continuous problems [83].
- Fewer Parameters: While sensitive, DE has a relatively small set of control parameters ( (F, Cr, NP) ) to adjust [83].
- Weaknesses:
- Limited to Continuous Spaces: The classic DE is not naturally suited for discrete or combinatorial problems without significant modification.
- Parameter Sensitivity: While having fewer parameters, its performance can be highly sensitive to the choices of ( F ) and ( Cr ), though advanced versions like objective-dimension feedback (ODF) have been proposed to adaptively configure parameters based on fitness ranking and dimension diversity ranking [83].
- Vector Dependence: Its operations rely on vector differences, which can be less interpretable than the genetic operations of GA.
Experimental Protocols and Applications
To illustrate the practical application of GA and DE, this section details a protocol for parameter estimation in biological network dynamics, a common challenge in systems biology and drug development.
Case Study: Parameter Estimation in Systems Biology
Objective: To estimate the kinetic parameters of a biological network model (e.g., a metabolic pathway or signaling cascade) from experimental time-series data. This is often necessary when experimental data is available for only a subset of system variables [84].
Methodology:
- Problem Formulation:
- A system of ordinary differential equations (ODEs) is used to model the network: ( \frac{dx}{dt} = f(x, k) ), where ( x ) represents molecule concentrations and ( k ) represents the kinetic parameters.
- An objective function is defined to quantify the difference between model prediction and experimental data. A common choice is the Sum of Squared Errors (SSE): ( E(k) = \sum (x{measured}(t) - x{estimated}(t, k))^2 ).
Enhanced Objective Function with Differential Elimination:
- To improve estimation accuracy, especially with unmeasured variables, Differential Elimination (DE constraint), an algebraic method, can be used. It rewrites the ODE system to eliminate unmeasured variables, deriving constraint equations ( C_t(k) ) that must be zero if the parameters are correct [84].
- The standard objective function is then augmented with this DE constraint: ( O(k) = E(k) + \alpha \cdot C(k) ) where ( \alpha ) is a weighting factor [84].
Optimization Setup:
- Both GA and DE are deployed to minimize the objective function ( O(k) ).
- For a model with two molecules (A and B) where only ( x{AB} ) is measured [84]:
- Parameters to Estimate: ( kp ) (production/binding rate), ( km ) (decay/dissociation rate).
- Reference Data: Simulated time-course data of ( x{AB} ) using known parameters.
Results and Comparison:
- Simulation studies show that introducing DE constraints drastically improves parameter estimation accuracy for both GA and DE [84].
- GA with DE constraints successfully estimated both ( kp ) and ( km ), whereas GA without constraints frequently failed to estimate ( k_p ) correctly [84].
- DE with DE constraints also achieved accurate estimations, demonstrating the value of incorporating problem-specific knowledge into the optimization process [84].
Figure 2: Workflow for parameter optimization using GA/DE with differential elimination.
The Scientist's Toolkit: Essential Research Reagents
Table 2: Key computational and data "reagents" for optimization experiments in biological modeling.
| Item / Resource | Function / Purpose |
|---|---|
| Time-Series Experimental Data | Serves as the ground truth for calibrating the mathematical model. Critical for calculating the error function ( E(k) ) [84]. |
| Mathematical Model (ODE System) | A mechanistic representation of the biological system. It forms the basis for simulation and parameter estimation [84]. |
| Differential Elimination Software | An algebraic tool (e.g., in Maple or Mathematica) used to derive constraint equations ( C_t(k) ) from the ODE model, improving estimation accuracy with incomplete data [84]. |
| Optimization Algorithm (GA/DE Library) | Software implementations (e.g., in Python, R, or MATLAB) of GA and DE. They perform the iterative search for the optimal parameter set [84] [83]. |
| High-Performance Computing (HPC) Cluster | Parallel computing resources that significantly reduce the computation time for evaluating large populations over many generations [84]. |
Genetic Algorithms and Differential Evolution are powerful tools in the computational researcher's arsenal. The choice between them is not a matter of which is universally better, but of which is more appropriate for a given problem. GA offers greater flexibility for problems involving discrete decisions or complex representations. In contrast, DE often demonstrates superior performance and efficiency for real-valued parameter optimization in continuous spaces, such as model fitting in systems biology. For beginners, the key is to align the algorithm's strengths with the problem's characteristics: use DE for challenging continuous landscapes where global search is paramount, and consider GA for problems requiring a more flexible representation or where diverse solution ideas are valuable. Advanced techniques, such as incorporating domain knowledge through differential elimination, can significantly enhance the performance and reliability of both algorithms in practical research applications.
Evolutionary Algorithms (EAs) represent a sophisticated class of meta-heuristic optimization methods that emulate the processes of biological evolution. By utilizing mechanisms such as selection, mutation, and crossover, these algorithms effectively tackle a wide variety of optimization challenges across diverse domains including drug discovery, engineering design, and artificial intelligence [25]. Within this broader toolkit, two prominent algorithms have emerged as powerful solutions for complex optimization problems: Genetic Algorithms (GA) and Differential Evolution (DE). Both methods operate on population-based principles of evolution through natural selection, yet they employ distinct methodological approaches that make them uniquely suited to different types of challenges [6] [10].
The fundamental principle underlying both GA and DE is the concept of "survival of the fittest," where a population of candidate solutions undergoes iterative improvement through simulated evolutionary processes [85]. However, their implementation details diverge significantly, leading to different performance characteristics in practical applications. As research in evolutionary computation advances, understanding the nuanced distinctions, relative strengths, and appropriate application domains for each algorithm becomes crucial for researchers, scientists, and development professionals seeking to leverage these powerful optimization tools [11] [38].
This technical guide provides a comprehensive comparison of GA and DE, examining their core mechanisms, performance characteristics, and implementation considerations. By synthesizing current research and experimental findings, we aim to provide a definitive verdict on positioning these algorithms within the modern computational toolkit, with particular attention to applications in scientific research and drug development.
Algorithmic Fundamentals: Core Mechanisms and Methodologies
Genetic Algorithms: Binary and Real-Valued Representations
Genetic Algorithms maintain close metaphorical alignment with biological genetic reproduction, employing terminology and operations directly inspired by natural selection [6]. The algorithm begins with a population of chromosomes, each representing a potential solution to the optimization problem. These chromosomes are traditionally represented as binary strings, though real-valued representations are also commonly used, particularly for numerical optimization problems [85].
The standard GA workflow encompasses three primary operations: selection, crossover, and mutation. Selection identifies the fittest individuals to serve as parents for the next generation, typically using methods like tournament selection or roulette wheel selection based on fitness scores. Crossover then combines genetic material from parent chromosomes to produce offspring—for example, single-point crossover swaps genetic segments between two parents at a randomly selected point. Mutation introduces random variations by flipping bits in binary representations or adding small perturbations to real values, maintaining population diversity and enabling exploration of new solution regions [85].
For a simple optimization problem such as maximizing f(x) = x² within a specified range, a GA would encode potential solutions as binary strings, evaluate fitness using the objective function, select parents probabilistically based on fitness, perform crossover to create offspring, apply random mutations, and iteratively replace the population while preserving the best solutions [85]. This process continues until convergence criteria are met or a maximum number of generations is reached.
Differential Evolution: Vector-Based Operations
Differential Evolution operates on real-valued vectors using straightforward vector operations rather than the genetically-inspired operations of GA [86] [10]. DE maintains a population of candidate solutions but utilizes a different approach to generating new candidates. The algorithm employs a distinctive mutation strategy that leverages differences between population members to explore the solution space [6].
The DE process begins with population initialization, typically using real-valued vectors distributed throughout the search space. The critical distinction emerges in the mutation phase, where DE creates a donor vector for each target vector in the population by adding the scaled difference between two randomly selected vectors to a third vector: vi = xr1 + F × (xr2 - xr3) where F is a scaling factor typically in [0, 2] [10]. This differential mutation strategy enables automatic adaptation of the search step size based on the distribution of the population.
Following mutation, DE performs crossover by mixing components from the donor vector with the target vector to create a trial vector. Crossover probability (CR) determines whether each dimension is inherited from the donor or target vector. Finally, selection occurs through direct competition between each trial vector and its corresponding target vector, with the superior solution advancing to the next generation [86] [10]. This greedy selection strategy often contributes to DE's faster convergence compared to GA.
Visualizing Algorithm Workflows
Genetic Algorithm Workflow - Standard GA process showing iterative evolution through selection, crossover, and mutation operations.
Differential Evolution Workflow - DE process highlighting differential mutation and greedy selection mechanisms.
Comparative Analysis: Performance and Application Characteristics
Quantitative Performance Comparison
Table 1: Algorithm Characteristics and Performance Comparison
| Characteristic | Genetic Algorithm (GA) | Differential Evolution (DE) |
|---|---|---|
| Representation | Binary or real-valued | Primarily real-valued vectors |
| Mutation Operation | Bit-flip or small perturbation | Vector difference-based: F × (xr2 - xr3) |
| Crossover Method | Single/multi-point, uniform | Parameter mixing with probability CR |
| Selection Strategy | Fitness-proportional, tournament | One-to-one greedy selection |
| Parameter Sensitivity | Moderate (mutation rate, crossover rate) | High (F, CR) requiring careful tuning |
| Convergence Speed | Generally slower convergence | Faster convergence for numerical problems |
| Local Optima Avoidance | Good with proper parameter tuning | Excellent due to differential mutation |
| Theoretical Foundation | Well-established theory | Limited convergence proofs |
Experimental studies consistently demonstrate that DE outperforms GA on a majority of numerical optimization problems, particularly in continuous solution spaces [11]. A comprehensive comparison between state-of-the-art genetic algorithms (NSGA-II, SPEA2, IBEA) and their differential evolution variants (DEMO^NS-II, DEMO^SP2, DEMO^IB) conducted on 16 numerical multiobjective test problems revealed that "on the majority of problems, the algorithms based on differential evolution perform significantly better than the corresponding genetic algorithms with regard to applied quality indicators" [11]. This performance advantage is attributed to DE's more efficient exploration of the decision space in numerical optimization contexts.
Application Domain Suitability
Table 2: Application Domain Recommendations
| Application Domain | Recommended Algorithm | Rationale |
|---|---|---|
| Discrete/Combinatorial Problems | Genetic Algorithm | Natural binary representation |
| High-Dimensional Numerical Optimization | Differential Evolution | Superior real-valued vector operations |
| Multi-objective Optimization | DE-based variants | Better performance in empirical studies |
| Problems with Noisy/Incomplete Data | Genetic Algorithm | Robustness in uncertain environments |
| Chemical Process Optimization | Differential Evolution | Effective with continuous parameters |
| Neural Network Training | Differential Evolution | Successful applications in literature |
| Drug Design & Molecular Optimization | Both (problem-dependent) | Structure-dependent performance |
The selection between GA and DE depends significantly on the problem structure and domain requirements. Genetic Algorithms traditionally excel in discrete optimization problems where solutions naturally lend themselves to binary representations, such as feature selection, scheduling problems, and circuit design [85]. Differential Evolution demonstrates superior performance in continuous numerical optimization problems, including parameter estimation, function optimization, and engineering design optimization [10] [38]. Recent research indicates that DE-based approaches have successfully addressed complex real-world problems in chemometrics, chemical process optimization, and optimal experimental design [10].
Implementation Considerations: Practical Guidance
Parameter Tuning and Sensitivity
Both GA and DE require careful parameter tuning to achieve optimal performance. GA typically necessitates setting population size, mutation rate, crossover rate, and selection pressure. DE operates with fewer parameters—population size (NP), scaling factor (F), and crossover rate (CR)—but exhibits higher sensitivity to these settings [10] [38].
Research indicates that improper DE parameter selection can cause stagnation in local optima or difficulty converging. Recommended starting values are F = 0.5 and CR = 0.9 for general applications, with adaptive parameter control strategies showing significant performance improvements [38]. Recent advances include reinforcement learning-based parameter adaptation, where algorithms dynamically adjust F and CR values during optimization based on population fitness trends [38].
For Genetic Algorithms, mutation rates typically range from 0.001 to 0.01, with crossover rates between 0.7 and 0.95. Population size should be set according to problem complexity, with larger populations providing better exploration at increased computational cost [85].
Enhanced Variants and Hybrid Approaches
Recent algorithmic improvements have addressed inherent limitations in both approaches:
- Reinforcement Learning-enhanced DE (RLDE): Incorporates policy gradient networks for dynamic parameter adjustment and implements hierarchical mutation mechanisms based on fitness-based population classification [38].
- Multi-strategy Fusion DE (MSFDE): Integrates multi-population strategies, novel adaptive mechanisms, and interactive mutation strategies to balance exploitation and exploration capabilities [38].
- Self-Learning Genetic Algorithm (SLGA): Employs reinforcement learning to intelligently adjust key genetic parameters during evolution [38].
- DEMO Variants: Multiobjective DE extensions that have demonstrated superior performance compared to traditional GA-based multiobjective approaches [11].
These enhanced algorithms address common limitations such as premature convergence and parameter sensitivity while maintaining the fundamental strengths of their underlying approaches.
Experimental Protocols and Validation Frameworks
Standardized Testing Methodology
Robust comparison between optimization algorithms requires standardized testing methodologies encompassing diverse problem types:
Test Problem Selection: Comprehensive evaluation should include unimodal, multimodal, separable, non-separable, and constrained optimization problems across various dimensionalities (10D, 30D, 50D) [38].
Performance Metrics: Multiple quality indicators must be employed, including convergence speed, solution accuracy, reliability, and computational efficiency [11].
Statistical Validation: Results should undergo rigorous statistical testing with multiple independent runs to account for algorithmic stochasticity [11].
Parameter Settings: Comparisons should use optimally tuned parameters for each algorithm, documented for reproducibility [38].
Recent experimental studies employ 26 standard test functions for optimization testing, with comparisons conducted across multiple dimensions to thoroughly evaluate algorithm performance [38].
The Scientist's Toolkit: Essential Research Reagents
Table 3: Essential Computational Tools for Evolutionary Algorithm Research
| Tool/Resource | Function | Application Context |
|---|---|---|
| Standard Test Functions | Algorithm benchmarking | Performance validation (e.g., 26-function suite) |
| Parameter Tuning Frameworks | Optimization of algorithm parameters | Adaptive control systems (e.g., RL-based tuning) |
| Statistical Analysis Packages | Result validation | Significance testing of performance differences |
| Visualization Tools | Algorithm behavior analysis | Convergence plots, population diversity tracking |
| Parallel Computing Resources | Handling computational complexity | Population-based simulations |
| Benchmark Datasets | Real-world performance assessment | Domain-specific validation (e.g., chemical processes) |
The comprehensive analysis of Genetic Algorithms and Differential Evolution within the evolutionary computation toolkit yields a clear verdict: DE generally outperforms GA in numerical optimization problems, particularly in continuous domains, while GA maintains relevance for discrete combinatorial problems and scenarios where its binary representation is advantageous [11] [38].
Current research trends indicate growing adoption of DE in scientific and engineering applications, with continued development of hybrid approaches and adaptive parameter control mechanisms [10] [38]. The integration of machine learning techniques, particularly reinforcement learning, with evolutionary algorithms represents a promising direction for enhancing both GA and DE performance while reducing dependence on manual parameter tuning [38].
For researchers and drug development professionals, algorithm selection should be guided by problem characteristics: DE is recommended for high-dimensional numerical optimization with continuous parameters, while GA remains valuable for discrete optimization and problems with natural binary representations. As both algorithms continue to evolve, their position within the broader computational toolkit appears secure, with ongoing innovations ensuring their relevance for complex optimization challenges in scientific research and industrial applications.
Conclusion
For beginners in research and drug development, understanding the distinction between Genetic Algorithms and Differential Evolution is crucial for effective algorithm selection. GAs, with their structured chromosome-based approach, offer a intuitive entry point, while DE's strategy of using vector differences often provides faster and more robust convergence for continuous optimization problems commonly encountered in chemistry and biology, such as molecular design and experimental planning. The choice is not about which algorithm is universally superior, but which is better suited to the problem's nature—specifically, the solution representation and the landscape of the objective function. Future directions involve hybridizing these algorithms with other AI methods, like Bayesian optimization or deep learning, to create more powerful tools for automated experimentation and accelerated therapeutic discovery. Mastering these evolutionary fundamentals paves the way for tackling the high-dimensional, multi-modal optimization challenges at the forefront of modern science.
References
- 1. Evolutionary algorithm [https://en.wikipedia.org/wiki/Evolutionary_algorithm]
- 2. Differential Evolution from Scratch in Python [https://www.machinelearningmastery.com/differential-evolution-from-scratch-in-python/]
- 3. A tutorial on Differential Evolution with Python [https://pablormier.github.io/2017/09/05/a-tutorial-on-differential-evolution-with-python/]
- 4. Evolutionary algorithms vs genetic algorithms | by Hey Amit [https://medium.com/data-scientists-diary/evolutionary-algorithms-vs-genetic-algorithms-5f015eed4b45]
- 5. A Gentle Introduction To Genetic Algorithms [https://towardsai.net/p/l/a-gentle-introduction-to-genetic-algorithms]
- 6. What's differential evolution and how does it compare to a ... [https://stackoverflow.com/questions/9506809/whats-differential-evolution-and-how-does-it-compare-to-a-genetic-algorithm]
- 7. Unit 7) Differential Evolution - Automated Machine Learning [https://towardsdatascience.com/unit-7-differential-evolution-automated-machine-learning-eb22014e592e/]
- 8. Genetic algorithms: An overview of how biological systems ... [https://aggietranscript.faculty.ucdavis.edu/genetic-algorithms-an-overview-of-how-biological-systems-can-be-represented-with-optimization-functions/]
- 9. Paddy: an evolutionary optimization algorithm for chemical ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d4dd00226a]
- 10. Using Differential Evolution to Design Optimal Experiments [https://pmc.ncbi.nlm.nih.gov/articles/PMC7088454/]
- 11. Differential Evolution versus Genetic Algorithms in ... [https://link.springer.com/chapter/10.1007/978-3-540-70928-2_22]
- 12. | Baeldung on Computer Science Differential Evolution Algorithm [https://www.baeldung.com/cs/differential-evolution-algorithm]
- 13. Differential evolution [https://en.wikipedia.org/wiki/Differential_evolution]
- 14. Differential evolution: A recent review based on state-of-the ... [https://www.sciencedirect.com/science/article/pii/S111001682100613X]
- 15. Differential Evolution: An alternative to nonlinear convex ... [https://medium.com/data-science/differential-evolution-an-alternative-to-nonlinear-convex-optimization-690a123f3413]
- 16. Optimized differential evolution and hybrid deep learning ... [https://www.sciencedirect.com/science/article/pii/S1110016824009621]
- 17. Advancements in multimodal differential evolution [https://link.springer.com/article/10.1007/s10462-025-11314-7]
- 18. Population Genetics - Stanford Encyclopedia of Philosophy [https://plato.stanford.edu/entries/population-genetics/]
- 19. Genetic Algorithms Short Tutorial [https://www.cs.ucdavis.edu/~vemuri/classes/ecs271/Genetic%20Algorithms%20Short%20Tutorial.htm]
- 20. Differential Evolution in Algorithmic Trading Strategies [https://questdb.com/glossary/differential-evolution-in-algorithmic-trading-strategies/]
- 21. Fitness (biology) [https://en.wikipedia.org/wiki/Fitness_(biology)]
- 22. Fitness and its role in evolutionary genetics - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC2753274/]
- 23. The future of pharmaceuticals: Artificial intelligence in drug ... [https://www.sciencedirect.com/science/article/pii/S2095177925000656]
- 24. Neural DE: An Evolutionary Method Based on Differential ... [https://www.mdpi.com/2673-9909/5/1/27]
- 25. Survey of Genetic and Differential Evolutionary Algorithm ... [https://arxiv.org/html/2507.11751v1]
- 26. Genetic algorithm [https://en.wikipedia.org/wiki/Genetic_algorithm]
- 27. Comparative evaluation of the performance of improved ... [https://www.sciencedirect.com/science/article/abs/pii/S0029549322003041]
- 28. Leveraging Latent Evolutionary Optimization for Targeted ... [https://arxiv.org/html/2407.13779v1]
- 29. Genetic Algorithms [https://www.geeksforgeeks.org/dsa/genetic-algorithms/]
- 30. for Docking Simulations | SpringerLink Differential Evolution [https://link.springer.com/protocol/10.1007/978-1-0716-4949-7_14]
- 31. How does a Genetic Algorithm work? - Pico [https://www.pico.net/kb/how-does-a-genetic-algorithm-work/]
- 32. - Cornell University Computational Optimization... Differential evolution [https://optimization.cbe.cornell.edu/index.php?title=Differential_evolution]
- 33. An External Selection Mechanism for Differential Algorithm... Evolution [https://pmc.ncbi.nlm.nih.gov/articles/PMC9001124/]
- 34. Crossover and mutation: An introduction to two operations ... [https://blogs.sas.com/content/iml/2021/10/18/crossover-mutation.html]
- 35. A differential evolution framework based on the fluid model ... [https://www.sciencedirect.com/science/article/abs/pii/S0952197624007188]
- 36. How the Genetic Algorithm Works - MATLAB & Simulink [https://www.mathworks.com/help/gads/how-the-genetic-algorithm-works.html]
- 37. Crossover in Genetic Algorithm [https://www.geeksforgeeks.org/machine-learning/crossover-in-genetic-algorithm/]
- 38. An improved differential evolution algorithm based on ... [https://www.nature.com/articles/s41598-025-22730-8]
- 39. Crossover Operators in Genetic Algorithm | by Apar Garg [https://medium.com/geekculture/crossover-operators-in-ga-cffa77cdd0c8]
- 40. A Comparison Study for Different Settings of Crossover and... [https://link.springer.com/chapter/10.1007/978-94-007-2792-2_62]
- 41. Multi-objective differential evolution algorithm integrating a ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494625011044]
- 42. Genetic Algorithms – An Overview [https://help.imsl.com/c/2016/html/cnlstat/CNL%20Stat/csch13.16.16.html]
- 43. Genetic algorithms - What is a genetic algorithm? [https://rock-the-prototype.com/en/algorithms/genetic-algorithms/]
- 44. Harnessing Genetic Algorithms for Hyperparameter ... [https://dev.to/bikashdaga/harnessing-genetic-algorithms-for-hyperparameter-optimisation-in-2025-a-deep-dive-4bek]
- 45. Hybrid genetic algorithm and deep learning techniques for ... [https://www.nature.com/articles/s41598-025-06375-1]
- 46. A Genetic Algorithm for Navigating Synthesizable ... [https://arxiv.org/html/2509.20719v1]
- 47. Integrating Generative Pretrained Transformer and Genetic ... [https://pubmed.ncbi.nlm.nih.gov/40762910/]
- 48. Genetic Algorithms [https://web.cs.ucdavis.edu/~vemuri/Genetic_Algorithms.htm]
- 49. Differential Evolution and Its Applications in Image ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9638376/]
- 50. A study on scale factor in distributed differential evolution [https://www.sciencedirect.com/science/article/abs/pii/S0020025511000909]
- 51. An Analysis of Differential Evolution Population Size [https://www.mdpi.com/2076-3417/14/21/9976]
- 52. Genetic Algorithm (GA) Parameter Settings [https://www.eislab.gatech.edu/people/scholand/gapara.htm]
- 53. Choosing Mutation and Crossover Ratios for Genetic ... [https://www.mdpi.com/2078-2489/10/12/390]
- 54. differential_evolution — SciPy v1.16.2 Manual [https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.differential_evolution.html]
- 55. Evolving Benchmark Functions to Compare Evolutionary ... [https://arxiv.org/html/2403.14146v1]
- 56. Differential Evolution Using Enhanced Mutation Strategy Based on Random Neighbor Selection | MDPI [https://www.mdpi.com/2073-8994/15/10/1916]
- 57. A Two-Stage Differential Evolution Algorithm with Mutation Strategy Combination [https://www.mdpi.com/2073-8994/13/11/2163]
- 58. An improved differential evolution algorithm based on ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12592545/]
- 59. Differential Evolution Algorithm (DGA) - by Tahsin Soyak [https://medium.com/@tahsinsoyakk/differential-evolution-algorithm-dga-a-comprehensive-guide-71c1b3671bcf]
- 60. Chemical space exploration based on recurrent neural networks [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-020-00446-3]
- 61. Balancing exploration and exploitation in de novo drug design [https://pubs.rsc.org/en/content/articlehtml/2024/dd/d4dd00105b]
- 62. Exploration versus exploitation in space, mind, and society [https://pmc.ncbi.nlm.nih.gov/articles/PMC4410143/]
- 63. Exploration vs. Exploitation - Virtual Screening [https://www.charnwooddiscovery.com/navigating-the-exploration-vs-exploitation-trade-off-striking-the-right-balance-for-success/]
- 64. Comparative Study of Modern Differential Evolution ... [https://www.mdpi.com/2227-7390/13/10/1556]
- 65. Methods to balance the exploration and exploitation in ... [https://www.sciencedirect.com/science/article/abs/pii/S0925231223010226]
- 66. A review on genetic algorithm: past, present, and future [https://pmc.ncbi.nlm.nih.gov/articles/PMC7599983/]
- 67. Selection (evolutionary algorithm) [https://en.wikipedia.org/wiki/Selection_(evolutionary_algorithm)]
- 68. Comparative Study of DE, PSO and GA for Position ... [https://www.mdpi.com/1999-4893/8/3/697]
- 69. A genetic algorithm – differential evolution based hybrid ... [https://www.sciencedirect.com/science/article/pii/S0020025516301773]
- 70. A parallelized hybrid genetic algorithm with differential ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9127363/]
- 71. Differential evolution algorithms applied to nuclear reactor ... [https://www.sciencedirect.com/science/article/abs/pii/S0306454909001704]
- 72. A comparative study of differential evolution and genetic ... [https://ui.adsabs.harvard.edu/abs/2012JZUSA..13..674D/abstract]
- 73. Comparative analysis of the differential evolution and genetic ... [https://inis.iaea.org/records/abdff-6pm14]
- 74. Comparative performance analysis of evolutionary ... [https://www.sciencedirect.com/science/article/abs/pii/S1570870514000213]
- 75. Comparative Performance Analysis of Differential Evolution ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9189812/]
- 76. A Comparative Study on Differential Evolution and Genetic ... [https://www.semanticscholar.org/paper/A-Comparative-Study-on-Differential-Evolution-and-Hegerty-Hung/cc44e4e0dd2de316a9a19f1480b2772b969d4715]
- 77. Adaptive evolutionary algorithms with linear average ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494625009469]
- 78. New improved hybrid genetic algorithm for optimizing ... [https://www.nature.com/articles/s41598-025-97526-x]
- 79. Extending Genetic Algorithms with Biological Life-Cycle ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11351250/]
- 80. Evaluation metrics and statistical tests for machine learning [https://www.nature.com/articles/s41598-024-56706-x]
- 81. Comparing Optimization Algorithms Through the Lens of ... [https://arxiv.org/html/2507.01668v1]
- 82. A Visual Guide to Evolution Strategies | 大トロ [https://blog.otoro.net/2017/10/29/visual-evolution-strategies/]
- 83. Differential evolution with objective and dimension ... [https://www.sciencedirect.com/science/article/abs/pii/S2210650223000950]
- 84. Parameter optimization by using differential elimination [https://pmc.ncbi.nlm.nih.gov/articles/PMC2982696/]
- 85. Genetic Algorithms — A Beginner Friendly Guide [https://medium.com/@jhimli.c1/genetic-algorithms-a-beginner-friendly-guide-a95762bdadf2]
- 86. Full Guide to Implementing Differential Evolution In Python [https://levelup.gitconnected.com/full-guide-to-implementing-differential-evolution-in-python-9fc7fdeccaa8]